Poke2Poke: Generating Pokemon Evolutions
TL;DR
Deep Generative Models (DGM) are powerful tools with many hidden layers trained to estimate the likelihood of each observation and create new samples from the underlying distribution [1]. In recent years, we have seen DGM capable of generating realistic-looking images, voices, and even videos.
In this post, we illustrate the results of combining different approaches in order to generate a Pokemon evolution given a Pokemon image. This problem can be seen as an image-to-image translation, where we want to give an image from a certain domain as an input and generate another image, from that very same domain, as an output.
The problem
As we mentioned before, we’ve seen many applications for DGM, like generating faces of people, cats, art [5, 6, 7], creating synthetic music [8], among many other impressive applications [9]. Many of these applications make the line between human creativity and AI more blurry. Not long ago, AI art was auctioned for $432,500 [10].
With these powerful tools we were left with one question: “Okay but, can we create Pokemons?” (being born in the 90’s, it’s the only possible question), but not only Pokemons, but can we give a DGM a Pokemon, and then it will spill out a synthetic Pokemon evolution? well, we took this opportunity to try and find that out.
This problem may seem inoffensive at a first glance, but let’s take a look. To generate a Pokemon evolution from a given Pokemon we must keep in mind two things:
- The resulting Pokemon must look like a Pokemon.
- The resulting Pokemon should look like the given Pokemon to some extent.
For the first point, we have to be careful. Pokemons are diverse and may not look anything alike between them, even if they are of the same type or same generation:

For the second point, DGM tries to find the underlying distribution of data to generate new data that looks like real data. to apply them to our problem that means that we are trying to find the pattern, a systematic way to represent Pokemon evolution lines, but there is a slight problem with this, some Pokemon look not so much like their predecessor.



As illustrated, some lines are somehow easy to predict, but some of some change the general appearance, color, size, anatomy, so we are left with the question, can a DGM learn how to evolve a Pokemon?
Some background: GANs and cGANs
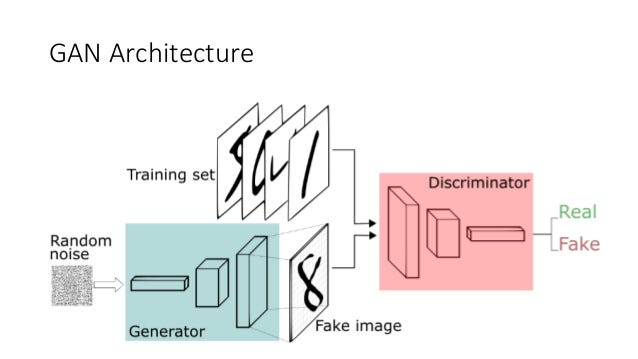
One of the most popular approaches for DGM is Generative Adversarial Networks (GAN). With this framework, we train two models simultaneously: a generative model G, which tries to capture the underlying distribution of the data, and the discriminator D, which estimates the probability of a sample coming from the underlying distribution of data.
The objective of G is to generate synthetic data, which will make the discriminator D fail, and the objective of D is to detect data that was generated from G. These tasks are antagonistic, adversarial, which makes this framework correspond to a minimax two-player game [2].

From the image, we can see that the generator G generates a fake image from random noise. Because of this random noise, we have little (to no) control over what synthetic image is generated and passed to the discriminator D. For our goal to generate evolutions given a Pokemon image, we need to make sure G generates not only a Pokemon, but one that looks like the evolution of a given one.
One way to achieve this is with Conditional Generative Adversarial Networks (cGAN), where the generator is conditioned to generate a certain image by simply feeding that particular image, y, to both the generator and discriminator [3].

As depicted above, to generate some synthetic data x_F, we feed not only a
random noise vector z to G, but we also append the data y which is also given
to the discriminator D alongside the real data x_R . With this, we can ask our
generator G to generate certain data and tell our discriminator D to detect
certain data too.
A first approach: Pix2Pix
The first approach we used was the framework Pix2Pix [4]. In this framework, we use as a generator a U-Net based architecture and a convolutional PatchGAN classifier on 256 × 256 RGB Pokemon images. The goal for the discriminator is still the same as we talk about in the cGANs section, but the generator is asked to not only try to fool the discriminator but also to make the generated image as close as possible to the ground truth in an L1 sense [4].
Ultimately what we are trying to achieve is

where λ will be a regularization factor, which will tell us how important is it that the generated images are close to the ground truth.
You can find the implementation here! For our firsts attempts to achieve the goal, we tried using a λ = 100, and training of 500 epochs, which gave the following results on the training and test samples:


Well, they don’t look like Pokemon to begin with, do they? Taking a look at the evolution of the losses we can find some answers to what it’s going on:



As we see, the discriminator loss is quite lower than the generator GAN loss, so we (erroneously) tried to make the generator be more persuasive into fooling the discriminator (besides, those didn’t look like Pokemons for us). We tried with a λ = 10, same number of epochs. We obtained the following results:

Alright, something is happening here, the generator is generalizing so that every Pokemon that is fed to the network will result in this form, just different colors. We see this as an effect of changing λ to such a small value, this means that we are not that interested in the output looking like the ground truth, but more interested in fooling the discriminator, so this form represents in a way the “average” Pokemon.
Let’s take a look at the losses:



Taking a look at these losses, we can realize it doesn’t look like a fair match, the discriminator it’s doing pretty good at detecting whether or not the image it’s a Pokemon, but the generator is having a hard time at making it look like a real Pokemon.
We saw that reducing λ will not do, so we tried with λ = 1000 to force de generator to create images resembling the given Pokemons. We obtained the following results:


The results appear to have some form, but they just look like someone tried to paint them using watercolors and then left the painting outside while it was raining.
Reducing the dimension of the problem: Variational Autoencoder + changing the images
At this point, we decided to change our approach to solve this problem, so the next step we took was to try out a Variational Autoencoder (VAE) as our generator, but first, let’s take a look at what is an Autoencoder.
Autoencoders [11] are a feed-forward network where we want the output data to be the input data. This architecture compresses the data from the input and passes it through a bottleneck, called latent space, which has a much lower dimension than the input and output data and then tries to reconstruct the input data from there. This bottleneck forces the network to extract the important data from the input in order to reconstruct it from the encoded data in the latent space.

But since autoencoders are really good at replicating data, but not so much for random sampling from their latent space since it may not be continuous or allow easy interpolation [12], we decided to try out Variational Autoencoders, whose latent spaces are, by design, continuous. Because of this continuous latent space, we are able to draw random samples from here that should look like Pokemons.

At this point we also decided to reduce the dimensionality of the problem by also reducing the size of the images: instead of using images with size 256 x 256, we changed it to 64 x 64 (You can find the sprites we used here).
This time, we wanted to train a VAE to learn how to reconstruct Pokemons. Then we want to calculate a δ vector for each Pokemon which is the average translation between the Pokemon and its evolution. For this we used the data from the first two generations, but we will talk more about this later, for now let’s focus in generating Pokemons.
You can find the architecture and details of the implementation in here. The following images show the results obtained from this approach, with 300 epochs. As we can see, it is doing pretty well at maintaining the overall form of the Pokemon, but lacks some details.


At this point (taking into consideration the amount of time we had to achieve our goal of generating Pokemon evolutions) we decided to use this approach since the results are close enough to look like real (a little blurry) Pokemons. Alright, we can move on and tackle the next problem: generating an evolution given a Pokemon.
Generating Pokemon evolutions
As we mentioned before, we want to get a vector δ in the latent space, which will be the average translation between each Pokemon to their evolution. That is the following:

You can find the implementation in this notebook.
Next, let’s analyze the distribution of all delta vectors. Below is the absolute value of the displacement in each latent dimension, this gives us an idea of how many dimensions actually transform a pokemon into its evolution in the latent space.

Now lets actually plot the distribution of each dimension (mean and std).

Standard deviations are very similar. Further statistical analysis would be necessary to determine if these samples come from the same distribution, i.e. if there is an actual translation between a pokemon and its evolution, or it is all a bunch of mumbo jumbo.
Now that we calculated this δs, we can proceed to generate Pokemon evolutions by displacing the lantent representation by the average δ. We show the following results:



A little blurry, but we can see some Pokemon-looking images. This results actually look better than we expected. In some cases the change is almost like blurrying the original image, but in other cases we can see some actual changes over the original pokemon.
We can also see the importance of having an autoencoder that regularizes on learning latent representations, because the vector space where the transition happens needs to be able to continuously represent actual Pokemons, for this evolution to take place.
Future work
As we can see, the generated Pokemon lack details once they come out of the VAE, so our next goal is to achieve sharper results. Our next approach is to try out the architecture proposed in this paper [14], a Variational Autoencoder Generative Adversarial Network (such a cool name), since it replaces the element-wise error with feature-wise errors, and it also adds an error due to the discriminator. We believe this will produce better-looking, sharper images of Pokemons.
Conclusion
DGM are powerful tools that had been able to solve problems that were thought of as unsolvable some year ago. At the same time, Deep Learning is continuously and rapidly evolving and proof of this is shown in this goal of generating Pokemon evolutions. As we stated before, capturing the underlying distribution of Pokemon evolutions was not a trivial thing to do, since this task involves capturing the style of multiple artists that created each Pokemon. Of course, the end result wasn’t as sharp as real Pokemon evolutions, but it shows the power of DGM. As a final thought is that at the end of the day, compute power plays a big role in developing almost any solution in Deep Learning.
Big kudos to Conor Larazou, whose post was very helpful [15]! also big kudos to Profesor Julio Waissman, for encouraging this idea as a final project for the Neural Networks class.
Thank you for coming to our TED talk.
Awesome references
- https://arxiv.org/pdf/2103.05180.pdf
- https://arxiv.org/pdf/1406.2661v1.pdf
- https://arxiv.org/pdf/1411.1784.pdf
- https://arxiv.org/pdf/1611.07004v3.pdf
- https://thispersondoesnotexist.com/
- https://thiscatdoesnotexist.com/
- https://thisartworkdoesnotexist.com/
- https://openreview.net/forum?id=H1xQVn09FX
- https://machinelearningmastery.com/impressive-applications-of-generative-adversarial-networks/
- https://www.nytimes.com/2018/10/25/arts/design/ai-art-sold-christies.html
- https://www.cs.toronto.edu/~hinton/science.pdf
- https://towardsdatascience.com/intuitively-understanding-variational-autoencoders-1bfe67eb5daf
- http://www.cs.us.es/~fsancho/?e=232
- https://arxiv.org/pdf/1512.09300.pdf

{kind=link}