Swiping Right on Data: Analyzing the Trends of Tinder

We’re all kind of aware that men and women experience dating applications differently. The topic frequently comes up in internet memes, casual conversations with friends, and even discussions by psychologists and podcast bros. But I wanted to find out truly how different is it? Can we put a number on it. I also wanted to figure out if you could optimize your Tinder profile. There are many tools that help you make your resume better when you’re searching for a job. But, I couldn’t find any tool that would give you feedback on your profile. There’s some general advice out there like — maybe upload a picture with your cat, but even that is based on author’s own liking and intuition and not on numbers. As a data enthusiast who is new to Tinder and wanted to understand the dating app landscape, I delved into the maze of Tinder dataset to see if I can find something I don’t already intuitively know.
Inspiration
Inspiration for this project came from Alyssa Beatriz Fernandez who wrote this brilliant piece - “I analyzed hundreds of user’s Tinder data — including messages — so you don’t have to”, which I came across, a couple years back. I was fascinated by her findings, and wanted to see if I there’s anything more to dig.
Most of my data-related projects are for a very niche audience, so another reason to work on this was that I wanted to create something that was interesting for everyone and not just people with a programming or statistics background.
Obtaining the data
I initially searched on Kaggle and Google but couldn’t find what I was looking for. So, I thought maybe I should follow Alyssa’s footsteps and approach Kristian Bo, the guy who runs Swipestats.io. Swipestats is a unique platform where users can upload their Tinder, Bumble, and Hinge data and it returns a beautiful visualization of your data file. If you are currently using any of those applications, I highly encourage you to check it out. It’s brilliant.
Since it’s one of the go-to sites that offers this very unique service, it’s quite popular within it’s respective domain, and as a result they have amassed a significant amount of Tinder data over the years. I asked Kristian if I could get some of it do my data analytics project on it and he graciously agreed and shared an anonymized chunk out of it. My deepest gratitude to Kristian, couldn’t have done this project without his kindness.
Cleaning the data
I got access to a JSON file that had records of 1209 users and the file was about 563mb. The data was unstructured, messy and required a lot of cleaning. I had never worked on an unstructured data file before, and I’m not a JSON expert. I do understand the basic structure of it, but, I wanted to get it into a CSV form that I am more used too.
I tried cleaning it with GPT4, but it doesn’t accept files over 500mb (as of now), so I manually cropped a 10mb chunk out of the JSON file and uploaded that on GPT4, and prompted it to explain the structure of the file. Once I got the structure, I decided on what columns would suit me best for the questions I’m trying to find an answer for, and went from there.
Data cleaning was probably the hardest part of this project, it was super messy, contained many null values, contained duplicate columns, spelling mistakes, emojis that my computer didn’t recognize, and so much more. It was complete chaos. In the original data, they had combined state names and country names for some reason, and a lot of the names of these places were not written in English. I used GPT4 to figure out the name of the country based on the ‘state’ or ‘translate to English’ if it’s given in another language and map it to that column. Then I did the same for the ‘jobTitle’ column as well, because so many people had entered a value that was not in English.
I divided my task into 2 sections, or tables — one where I analyze user’s data and another one where I analyze conversations.
Part I — Analyzing User Data
Here are the columns I picked for this analysis from the JSON file.
['_id', 'sum_app_opens', 'no_of_days', 'nrOfConversations', 'longestConversation', 'longestConversationInDays', 'averageConversationLength', 'averageConversationLengthInDays', 'medianConversationLength', 'medianConversationLengthInDays', 'nrOfOneMessageConversations', 'percentOfOneMessageConversations', 'nrOfGhostingsAfterInitialMessage', 'no_of_matches', 'no_of_msgs_sent', 'no_of_msgs_received', 'swipe_likes', 'swipe_passes', 'birthDate', 'ageFilterMin', 'ageFilterMax', 'cityName', 'country', 'createDate', 'education', 'gender', 'interestedIn', 'instagram', 'spotify', 'jobTitle', 'user_age']Swiping Patterns — Let’s see how the two genders differ in their swiping behaviors. No points for guessing.
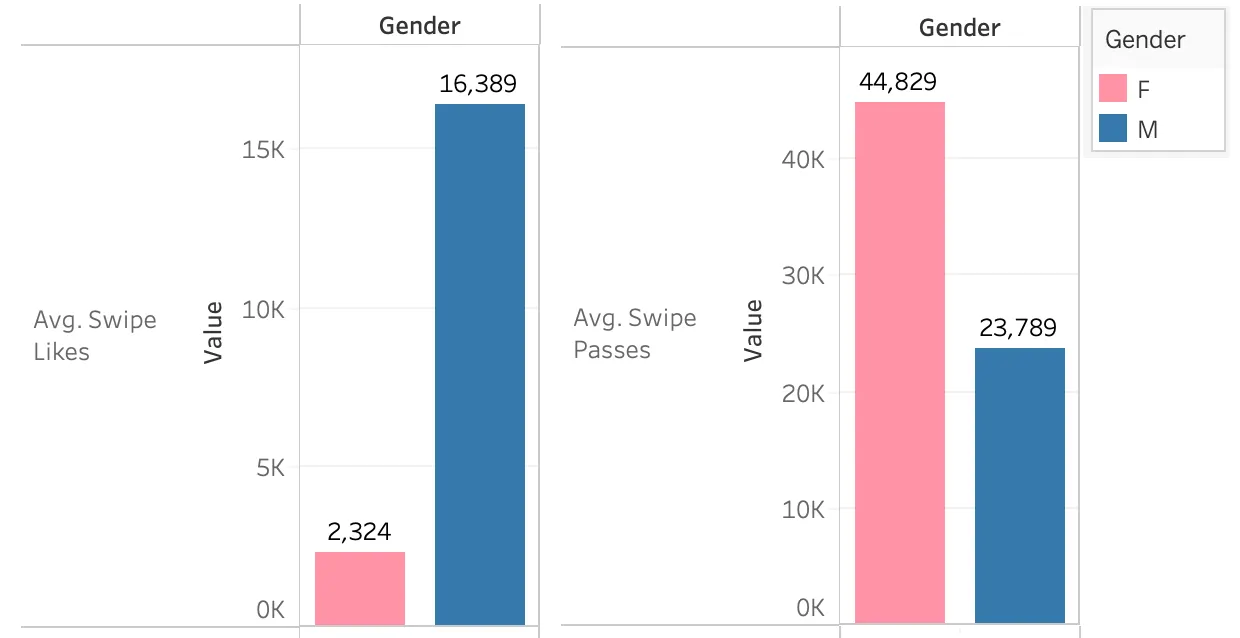
While I did not expect this to be equal, the extent of the imbalance still surprised me a little. One must wonder, given that men swipe right so frequently, they must be getting way more matches, right? Right… ?

Nope. Sorry Ken, the numbers aren’t too promising. Men get way less matches on an average even though they spend more time on the app.
Age Filters — This is what the age filter looks like for different genders.

Times are tough, economy is down, countries are fighting. Nobody is safe. Not even your granny.
Small Talk — A glance at conversation metadata. A more in depth analysis of the conversation data is there later on in this article.

An average girl has over 377 conversations over Tinder where as it’s just about 222 for a guy. For every 18 people a guy would ghost, a girl would ghost 107. The median length of a conversation is about 2.7 with a girl and 4.5 if you’re a guy. Which means, you have approximately 2.7 messages to make an impression on her or 4.5 messages to make an impression on him.
Location Matters!
A glimpse into what the average number of matches look like for different geographies.

If you find this article helpful and you feel like gifting me a ticket to Latvia, please don’t hesitate to reach out.

If you don’t see your country here, may I remind you that this is simply findings from a small random dataset of 1209 users. Which is just a fraction of the actual tinder user base. So, don’t worry about it.
Connecting your account with Instagram and Spotify — When you setup your profile, Tinder asks you to connect these 2 applications in order to complete your profile. This gives other users a brief window into your life, and your music taste. But let’s find out if it’s helping you or hurting you?

Linking Instagram to your Tinder profile tends to result in more matches for both men and women on average. In my opinion, this might be because of the fact that people who fully set up their profiles are more likely to be more active, and spending more time on the app would probably result in more matches overall.
But the relationship is not so linear in case of having Spotify on your profile. Men who have Spotify attached to their profile tend to get slightly more matches than men who don’t. Where as women who have it on their profile tend to get slightly less matches than women who don’t. Does this mean men have a better taste in music as compared to women?
“I guess we will never know” — Kanye West
Profession Matters!
Here, we take a look at different professions amongst the genders and how many matches they are getting on an average.


I’m a bit disappointed not to see ‘Musicians’ among the top. Growing up, I always believed that being an artist was the epitome of cool. It’s nice to see ‘Analysts’ doing well, though.
Part II — Analyzing Conversations
For the conversation analysis, I extracted the ‘id’, ‘match_id’, and ‘message’ columns from the JSON. The dataset I worked with was quite diverse, including languages other than English.
I started with creating a word and an emoji count to find out what were the top 10 words and top 10 emojis used through over 2 million rows and here were the results.

There’s an emoji missing in the third position; I suspect it was an Android-specific emoji. I’m not totally sure. Also, people use the word ‘I’ much more than the word ‘you’. I once saw a video by a YouTube channel named ‘Charisma on Command’, and they mentioned that the easiest way to start a conversation with someone you don’t know is to ask about them. People love to talk about themselves. It’s their favorite subject. This kind of validates the point.
What’s the best way to start a conversation?
I’ve classified conversation starters into four main themes:
- Basic ones — where people start the conversation with something fairly simple — Hey, Hi, Hello, etc,.
- GIF — where people simply send a moving picture from Giphy. In Tinder, there’s an option to send a GIF, and apparently people love to use it.
- Question — where people start the conversation by asking a question. It can be anything really.
- Pickup Line — they range from cheesy, funny, complimentary to straight up creepy. I won’t go into details.
Feature Engineering
Through the magic of Python, I created 6 new fields to my data— ‘Opener’, which counted the number of characters in the first message sent. ‘Conv. Length’, to get the count of messages sent to the same person. And then 4 boolean fields (True and False). Basic Opener — mapped the value ‘True’ if the very first message sent by the user had less than 18 characters in it. GIF — mapped the value ‘True’ if the very first message had a link from giphy in it. Question — mapped the value ‘True’ if the very first message ended with a question mark. Pickup Line — mapped the value ‘True’ if the very first message had more than 18 characters and did not end with a question mark.
Assumption — To measure which of these 4 themes did the best, I’ll use conversation length as a measure of success. I’m aware that this assumption might not capture instances where phone numbers or Snapchat usernames are exchanged within a couple messages. However, it’s the most practical measure I could think of. If you have any better ideas, feel free to let me know in the comments section.
What happens (on an average) when you start a conversation with a basic text — Hi, Hey, Hello, etc,.?

For guys — the average length of the conversation slightly increases when they start a ‘basic’ conversation as compared to something else.
For girls — the average length of the conversation dips a little when they start a ‘basic’ conversation as compared to something else.
What happens (on an average) when you start a conversation with a GIF?

Not a bright idea for anyone. Personally, I was surprised to see that there was anyone out there who uses a GIF in a conversation, let alone begin a conversation with one.
What happens (on an average) when you start a conversation with a question?

For guys — the average length of the conversation increases significantly when they start a conversation with a question.
For girls — the average length of the conversation dips when they start a conversation with a question.
What happens (on an average) when you start a conversation with a Pickup Line?

For guys — the average length of the conversation dips significantly when they start a conversation with a pickup line.
For girls — the average length of the conversation goes up when they start a conversation with a pickup line.
Tools Used
Jupyter notebook (Python). GPT4 for data cleaning and debugging code. Tableau for visualizations. Photoshop for creating and editing images.
Final Word
This is an analysis done on a very small subset of data from Tinder. This may or may not be an accurate reflection of the complete data, so take the findings here with a grain of salt. If you can be a male model in Latvia, be that. In all other cases, be yourself.
The contents of external submissions are not necessarily reflective of the opinions or work of Maven Analytics or any of its team members.
We believe in fostering lifelong learning and our intent is to provide a platform for the data community to share their work and seek feedback from the Maven Analytics data fam.
Happy learning!
