Uma Breve Jornada em Séries Temporais — Pt. 2: Lidando com Séries Univariadas

Olá! Nessa segunda parte da jornada vamos entrar na prática da previsão de séries temporais abordando problemas de séries temporais univariadas. Até agora na nossa jornada, estamos na seguinte situação:
- Uma Breve Jornada em Séries Temporais — Pt.1: Introdução
- Uma Breve Jornada em Séries Temporais — Pt.2: Lidando com séries univariadas (texto de agora);
- Uma Breve Jornada em Séries Temporais — Pt.3: Lidando com séries multivariadas (em breve).
Se você não leu a primeira parte, volte uma casa e leia o texto anterior. Mas se você já tá por dentro do assunto e quer ver o circo pegando fogo, siga em frente na leitura!
Atenção: algumas coisas que serão abordadas aqui serão explicadas superficialmente e o suficiente para entender o contexto. Para melhores explicações eu deixarei um link para um outro texto que trate sobre determinado tema.
O que vamos aprender nesse artigo?
- Análise e pré-processamento de dados.
- Organização dos dados e divisão em treino e teste, tópicos importantes na modelagem e previsão de Séries Temporais.
- Implementação de uma rede neural MLP.
- Métricas de validação de modelos de séries temporais.
O que vamos utilizar nessa atividade?
- Para a implementação, as queridas libs do Python:
pandasmatplotlibkerasenumpy - Vamos utilizar uma rede neural para ser o nosso modelo de previsão, mais especificamente a rede MLP.
O problema a ser atacado
O caso que vamos abordar a partir de agora é de temperaturas mínimas diárias em Melbourne, Austrália. Esses dados foram coletados diariamente durante 9 anos, de 1981 até 1990. Esse dataset (e mais outros 6 datasets de séries temporais) pode ser encontrado nesse link, que inclusive tem me ajudado muito nos meus estudos.
Let’s code!

Pontapé inicial
Inicialmente, importamos as bibliotecas e funções necessárias para a atividade. Nesse caso, eu fiz as seguintes importações:
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import math
import keras
from keras.models import Sequential
from keras import losses
from keras.layers import Dense
from keras.wrappers.scikit_learn import KerasRegressorE depois carreguei o dataset usando pandas e exibi as 10 primeiras linhas:
data = pd.read_csv('daily-minimum-temperatures-in-me.csv')
data.head(10)
Visualizando o comportamento dos dados
Antes de qualquer tomada de decisão de pré-processamento de dados em séries temporais nós devemos, em primeiro lugar, observar o comportamento dos dados através de gráficos.
Primeiro, eu fiz um parse nas datas para que fosse possível plotá-las no gráfico de forma legível:
dateparse = lambda x: pd.datetime.strptime(x, '%Y-%m-%d')
data = pd.read_csv(
'daily-minimum-temperatures-in-me.csv',
parse_dates=['Date'],
date_parser=dateparse
)E depois, o plot propriamente dito através do seguinte código:
data.plot(x='Date', y='Temperatures', figsize=(8, 5))
plt.grid(True)
Observando o gráfico acima, podemos perceber que o desenho do gráfico apresenta um padrão de comportamento bem definido que se repete ao longo do tempo. Nesse caso, anualmente. Esse é um comportamento típico de uma série temporal sazonal, onde os dados se comportam de forma semelhante ao longo das observações.
Algumas manipulações necessárias
Depois de observar nossos dados nós agora precisamos prepará-los para o treinamento da rede neural. A fase de pré-processamento, para esse problema, foi feita em 3 etapas:
- Normalização dos dados que ajuda o treinamento da rede.
- Organização dos dados que, em séries temporais, devemos rearranjar os dados de forma que seja possível de a rede performar bem na sua execução.
- Divisão em treino e teste que, no caso das séries temporais, conta com uma sutileza na hora de fazer a devida divisão.
Normalização
A normalização é bastante útil quando temos um dataset com atributos de valores numéricos mas que estão em escalas diferentes. Por exemplo: suponha que você tenha um atributo idade que tem valores como 23, 5, 8, 75, 32… e um outro atributo altura que tem valores como 1.82, 1.66, 1.75, 1.54… Já deu pra notar a diferença de escala entre os valores dos dois atributos, né? Isso tende a dificultar o aprendizado do nosso modelo e daí surge o motivo de normalizar os dados.
Você pode fazer isso de duas formas: utilizando a função MinMaxScaler() (read the docs para saber mais sobre a função), do sklearn ou fazer isso “manualmente”. Nesse caso eu fiz “manualmente” da seguinte forma:
def data_norm(data):
mini = min(data)
maxi = max(data)
return (data - mini)/(maxi - mini)Essa função vai deixar todos os valores dentro de uma mesma escala, geralmente entre 0 e 1.
Organização dos dados
Essa tarefa é o ponto chave na modelagem de séries temporais em relação a outros problemas de aprendizado de máquina e vou explicar o porquê.
Vamos fazer um comparativo com o problema de classificação, um tipo bem clássico. Naturalmente, datasets de problemas de classificação trazem consigo o que chamamos de rótulo ou atributo alvo ou atributo de classe, que é a variável que queremos predizer. Em séries temporais univariadas nós nunca teremos o rótulo porque só temos um atributo. Mas como vamos fazer previsão se não temos o que prever? É aqui que entra a tarefa de organização dos dados.
Vamos trabalhar com códigos de exemplo, que não estão dentro do contexto do problema de temperaturas mínimas diárias. Imagine que essa lista abaixo é o único atributo do nosso dataset:
# código de exemplo
feature = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]A essência da previsão de séries temporais é prever o futuro observando o passado. Ou seja, prever um novo valor a partir dos valores anteriores. Então você concorda comigo que o valor futuro de cada elemento da lista é o elemento seguinte? Observe a lista e reflita sobre a minha indagação (e ignore o último elemento )…
Refletiu? Então se essa ideia ficou bem fixada na sua mente, faz sentido criarmos um novo atributo, que será o nosso atributo alvo, com os valores futuros de cada elemento da lista que temos. Daí, ficaria assim:
# código de exemplo
feature = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
target = [20, 30, 40, 50, 60, 70, 80, 90, 100]ou assim:
10 | 20
20 | 30
30 | 40
40 | 50
50 | 60
60 | 70
70 | 80
80 | 90
90 | 100Esse procedimento é feito através desta função:
def split_sequence(data, n_steps):
x, y = list(), list()
for i in range(len(data)):
end_ix = i + n_steps
if (end_ix > len(data)-1): break
seq_x, seq_y = data[i:end_ix], data[end_ix]
x.append(seq_x)
y.append(seq_y) return np.array(x), np.array(y)
Ela recebe como parâmetros o dataset e o número de passos a frente que eu quero prever. Por exemplo, se a observação dos seus dados é diária e você passa como parâmetro n_steps=3 , você diz pra função que crie o atributo alvo com o terceiro valor futuro de cada observação. Ou seja, no caso de observações diárias, estamos querendo prever um valor daqui a três dias. No exemplo simples que dei acima ficaria:
10 | 40
20 | 50
30 | 60
40 | 70
50 | 80
60 | 90
70 | 100
...Por ser uma série univariada, o retorno da função já será o nosso x (os atributos descritores, que nesse caso é um só) e nosso y (que é o nosso alvo). No fim das contas, transformamos nossa série temporal em um dataset de aprendizado supervisionado de uma forma bem explícita, com atributo descritor e um atributo alvo.
Veja só como ficou as chamadas das funções data_norm() e split_sequence() :
x, y = split_sequence(data=data_norm(dataset['atributo']), n_steps=3)Das maravilhas que o Python nos proporciona! Em uma única linha eu fiz normalização, divisão dos dados e separei meu x e meu y . Agora só nos resta dividir nossos dados em treino e teste. Bora lá?
Treino e teste
Apesar desse tópico ser bem simples na maioria dos casos, existe uma sutileza na hora de realizar esse processo quando se trata de séries temporais. Vamos ver como isso funciona.
Aqui temos uma única preocupação: manter a ordem temporal dos dados. Ou seja, não podemos embaralhá-los. Nossa intenção aqui é fazer com que o nosso modelo seja capar de representar a série da melhor forma possível para poder prever um valor futuro e manter a ordem temporal dos dados garante que o nosso modelo consiga representar o comportamento dos dados da melhor forma possível.
Convencionalmente utilizamos a função train_test_split() do sklearn para dividir os dados de treino e teste. Essa função tem um argumento bem útil chamado shuffle — read the docs — que é booleano e, por padrão, recebe True . Isso vai fazer com que seus dados sejam embaralhados. Para evitar isso, atribua explicitamente o valor False ao parâmetro shuflle que fica tudo certo.
Se você quer ter certeza que os dados não serão embaralhados — não estou dizendo que não confio na implementação do sklearn , é apenas uma decisão de projeto — você pode fazer isso “manualmente”:
def split_data(x, y, train_size):
x_train = x[:int(len(x) * train_size)]
x_test = x[int(len(x) * train_size)]
y_train = y[:int(len(y) * train_size)]
y_test = y[int(len(y) * train_size)] return x_train, x_test, y_train, y_test
E em seguida é só chamar a função! Você verá que eu vou passar train_size=0.3 como parâmetro, dizendo que estou dividindo todo o dataset em 30% para treino e 70% para teste.
x_train, x_test, y_train, y_test = split_data(x, y, train_size=0.3)*Suspiro*
E aí, muita informação até agora? Dê uma pausa. Levante o bumbum da cadeira, faz um lanche, beba água e depois você volta pra aprender mais. Seu cérebro precisa de um alívio.

Implementando uma MLP
Tá descansada(o)? Deu pra relaxar um pouco, né? Então, sigamos!
Uma Multi-layer Perceptron é uma rede neural de múltiplas camadas composta por vários perceptrons ou neurônios que ligam-se a outros neurônios de outras camadas. Existem três tipos de camadas:
- Input layer, a camada que recebe os dados e os propaga para a próxima camada.
- Hidden layer, executa toda a matemática da rede. Podemos ter várias hidden layers.
- Output layer é a camada de saída, que entrega a resposta da predição de acordo com a entrada.
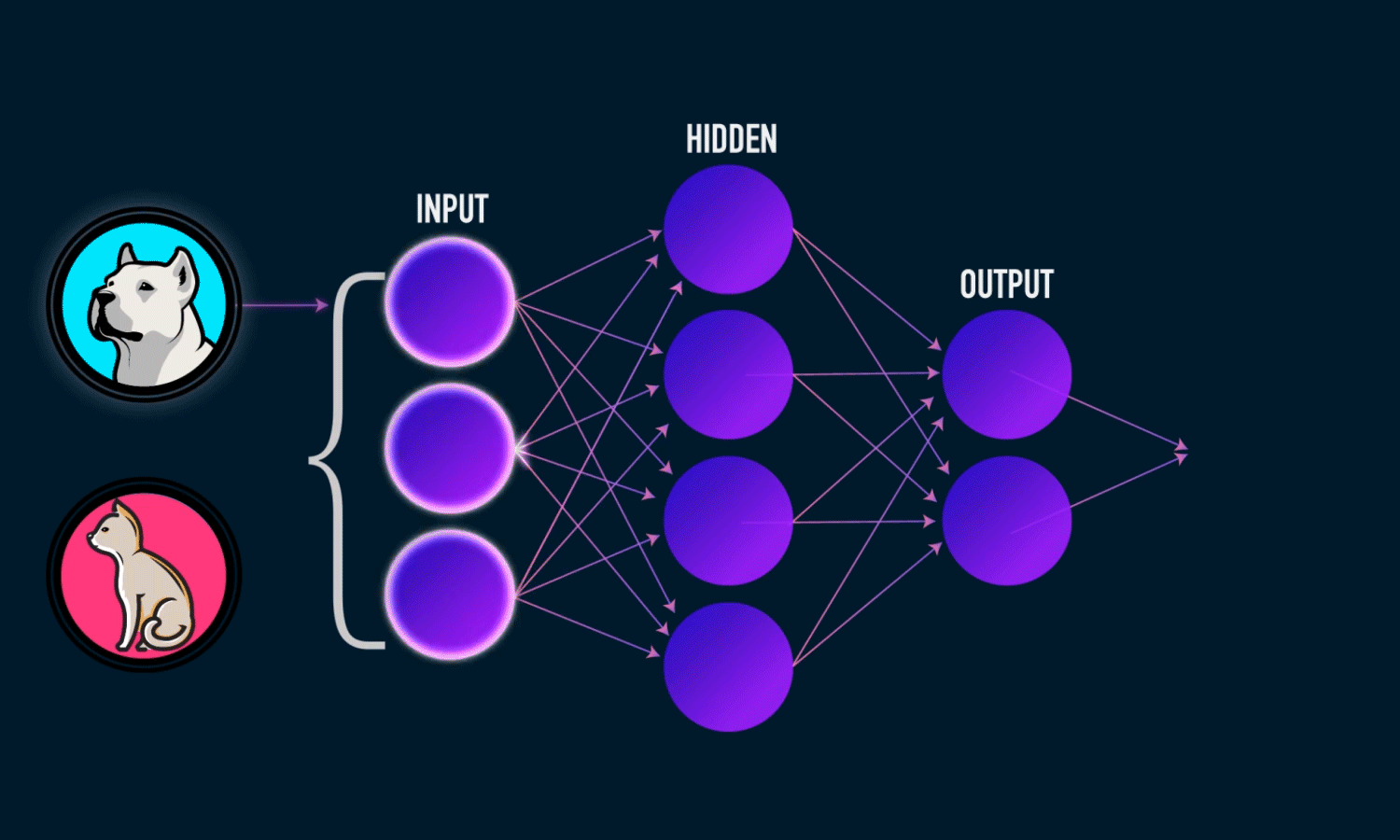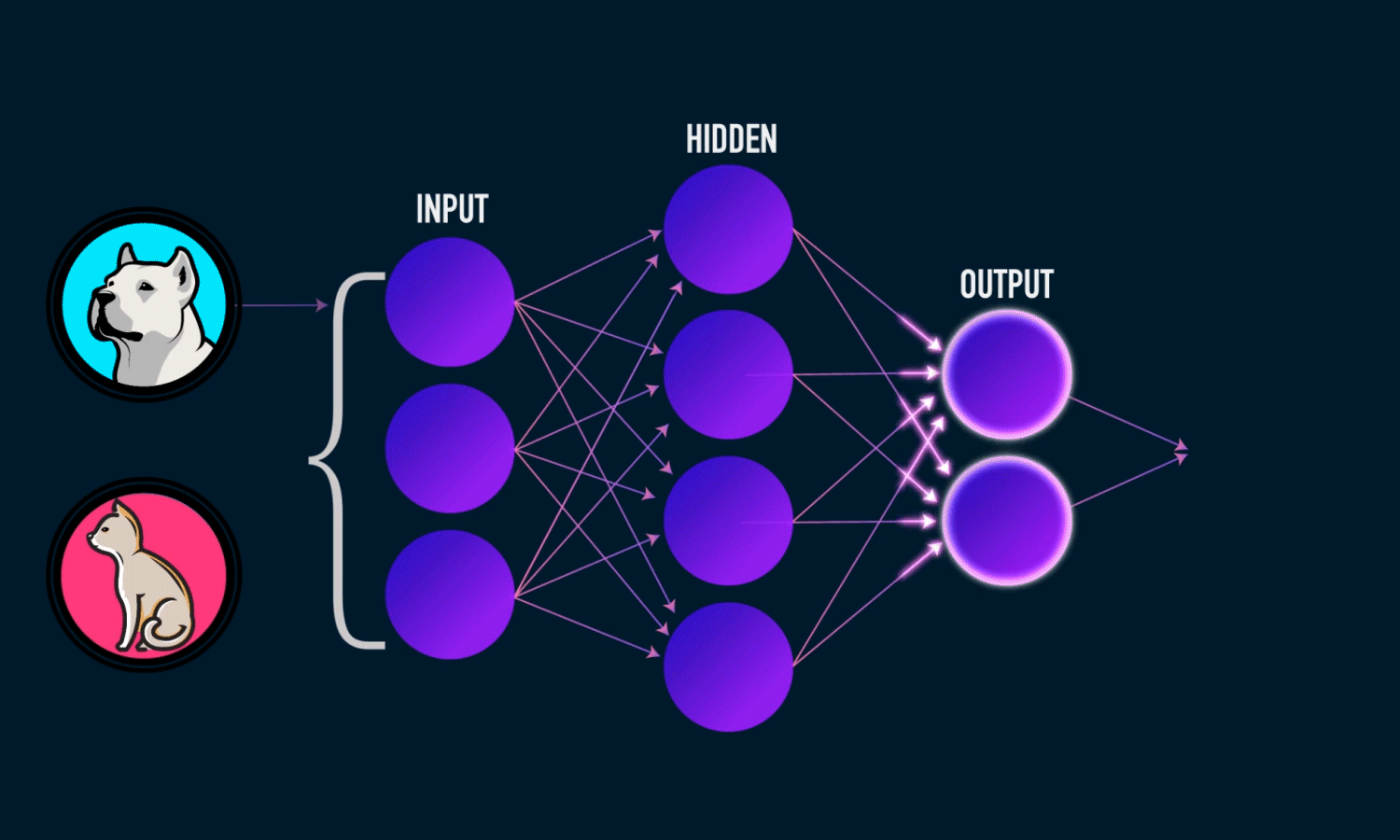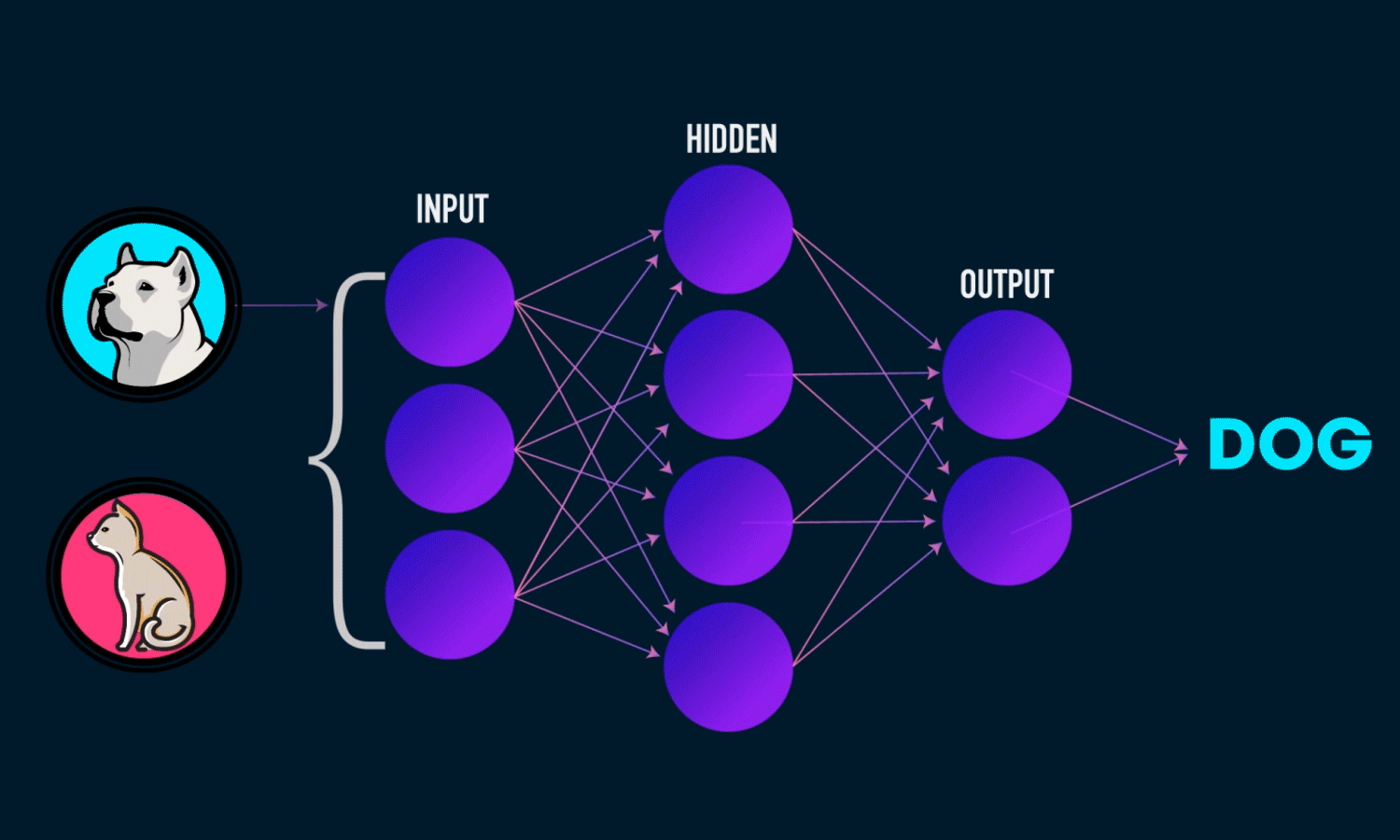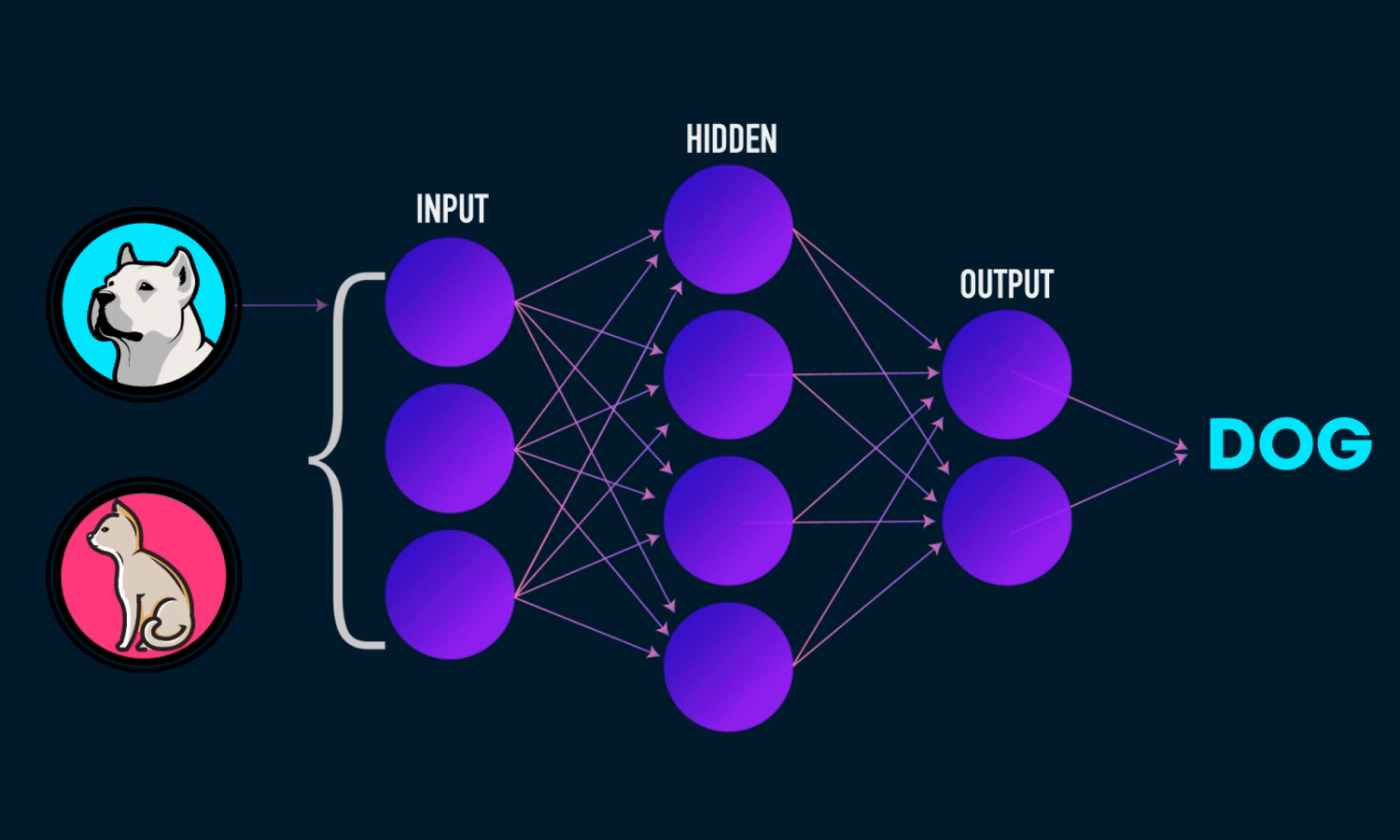
Ela trabalha executando os seguintes passos:
- Recebe os dados de entrada.
- Faz o devido processamento (matemática) ao longo das camadas.
- Na última camada, obtém o resultado referente aos dados de entrada.
- Pega o resultado obtido, compara com o original e ajusta os parâmetros internos da rede de acordo com o erro da comparação.
- Repete o passo 1.
Essa explicação de como uma MLP funciona é muito, muito, muito superficial. Estou assumindo que você, leitor(a), já tem um certo conhecimento em Machine Learning. Para um melhor entendimento sobre MLP, leia o texto do link que tá no rodapé da imagem acima e leia esse outro aqui.
O código
Existem duas formas bastante comuns de implementar uma MLP: utilizando sklearn e utilizando keras . Eu opter pelo keras . A implementação com o keras foi feita da seguinte forma: criei uma função chamada network_model() , onde eu defini a arquitetura da rede. Vê só:
def network_model():
model = Sequential()
model.add(
Dense(
30,
input_dim=step,
kernel_initializer='normal',
activation='relu'
)
)
model.add(Dense(1)) model.compile(loss='mse', optimizer='adam', metrics=['accuracy'] return model
Em seguida, chamo uma função que determina qual o tipo de rede neural que será utilizada. A filosofia da previsão de séries temporais nos faz perceber que esse é um problema de regressão. Cálculos de regressão tentam explorar e inferir a relação entre uma variável de resposta (atributo alvo) com variáveis explicatórias específicas (atributos descritores). Então, vamos utilizar o KerasRegressor() :
mlp_regressor = KerasRegressor(build_fn=network_model, epochs=100, batch_size=20)Veja que no argumento build_fn eu estou passando a função network_model , que encapsula a arquitetura da minha rede. E por fim, vamos colocar nosso modelo em treinamento com a função fit() :
model = mlp_regressor.fit(x_train, y_train, validation_data=(x_test, y_test), shuffle=False)Percebeu que o shuffle aparece mais uma vez em nossas vidas? a função fit() também embaralha os dados por padrão e por isso estamos deixando explícito que shuffle=False pelo mesmo motivo da fase de divisão em treino e teste. Ao executar seu código, você verá seu modelo em treinamento de uma forma bem semelhante a esta:

Rede treinada! Agora, vamos obter o resultado das predições que o meu modelo, agora treinado, é capaz de fazer. Para isso, vamos utilizar a função predict() :
pred = mlp_regressor.predict(x_test)Métricas (calculando o erro)
Agora temos o nosso modelo treinado e temos as predições. Tudo lindo! Mas… será que o nosso modelo é bom? Se sim, quão bom ele é? Como podemos provar? A nossa prova são as métricas!
Trocando em miúdos, nós utilizamos duas métricas. Uma no treino e outra no teste. Role a página para cima até o código da arquitetura da rede e veja que o argumento loss da função compile() recebe mse . MSE significa Mean Squared Error, que em português é Erro Médio Quadrado. O MSE é responsável por calcular o erro na fase de treinamento que é feito por baixo dos panos da seguinte forma:

Na fase de validação (ou teste), eu tenho duas fórmulas candidatas para fazer esse trabalho sujo, que são o MAPE e o RMSE. Aqui vamos utilizar o MAPE. O que essa função faz é calcular o percentual do erro médio absoluto desse jeito aqui:

A priori, não se espante com as fórmulas. O que você precisa saber é o que cada uma faz, não precisa saber aplicá-las manualmente, a programação vai fazer isso por nós. Mas nem sempre… o MAPE, por exemplo, não está implementado no sklearn (mas as outras estão) e com isso eu tive que implementar o meu MAPE:
def MAPE(y_test, prediction):
soma = 0
for i in range(len(y_test)):
soma += abs((y_test[i] - prediction[i]) / y_test[i]) * 100
media_erro = soma / len(y_test)
return media_erro.round(5)Viu só como é simples? Agora vamos aplicar a função e ver o resultado:
MAPE(y_test, pred)
> 24.79508Nosso modelo está com um erro de 24.79508%. Ou seja, ele tem uma acurácia na casa dos 76%. Não é dos melhores resultados mas é aceitável principalmente para quem tá começando a estudar esse tipo de problema.
Lembra que lá atrás eu disse que a gente busca fazer com o que o modelo possa representar os dados da melhor maneira possível? Os resultados mostram que chegamos consideravelmente perto. Mas vamos ver isso através dos gráficos:
plt.plot(y_test, 'k') # train result
plt.plot(pred, 'r') # prediction result
plt.grid(True)
Em preto, é o que nosso modelo representa e em vermelho é a resposta que ele dá a partir de um entrada desconhecida.
Considerações finais
Em primeiro lugar eu peço mil desculpas pelo texto longo, tentei ser o mais sucinto possível sem deixar de abordar as principais nuances que existem na modelagem e previsão de séries temporais.
Ao mesmo tempo agradeço a todas e a todos que tiram um tempinho para ler os artigos que nós do LICA escrevemos aqui no Medium. Tornar acessível conteúdo tecnológico e científico é o nosso propósito e fazemos isso com muito carinho!
Agradeço mais uma vez aos meus companheiros de laboratório por não deixarem apagar essa chama de produzir conteúdo para o mundo e agradecer também ao nosso orientador que é tão paciente com cada um de nós.
No mais, espero que vocês tenham aprendido algo sobre o assunto e quaisquer dúvidas podem me procurar no Twitter e me chamar na DM pra gente bater um papo. Vou deixar o link do meu repositório de séries temporais aqui também, lá tem o notebook com o código completo desse problema que a gente abordou aqui.
Mais uma vez o meu muito obrigado e um forte abraço! Espero por vocês na última parte da nossa jornada. Até breve!