Our journey from Gitlab to Kubeflow
Lifen’s mission is to make innovation seamless in the healthcare industry. We want to allow any organisation (public or private), any start up or any developer to contribute to and to improve the healthcare industry, by unbundling our internal APIs & Microservices and offering a platform to build better healthcare products together. In doing so, we are effectively offering tools, to easily get around these obstacles.
Our main product went from receiving and analyzing 300 medical reports per month to more than 1.5 million reports per month. As we rely on AI to hack our way into interoperability we continuously need to improve our ability to analyse and structure medical reports’ content.
In previous articles, we discussed how we started our first AI algorithm and how we built a robust on-premise CI/CD machine-learning pipeline on Gitlab. Here, we will explore why and how we moved our ML workflow from Gitlab to Kubeflow.
Why We Left Gitlab
Each tool has its pros and cons that must be evaluated at a specific moment in a project’s lifetime. Until recently, Gitlab answered our needs, but there are two main reasons why we decided to make a move to Kubeflow.
First, it became important for us to improve the team’s scalability. Back when we started, the AI team was a one-man operation, we had a couple of algorithms in production and Gitlab provided everything we needed (such as on-premise runners for security purposes, complete git-integration and alignement with our production workflow). Since then, our AI team has tripled, and so has the number of algorithms it uses. This growth in turn resulted in:
- a constant need to scale our on-premise Gitlab runners to deal with the increase in trainings;
- time wasted on searching for old job results; and
- the need for GPUs for specific trainings.
Second, a change was needed to improve the quality of our algorithms. Gitlab isn’t made to compare jobs and to search for old job results, and we thus suffered from a lack of result observability. The more accurate our algorithms became, the more we needed to be able to compare and observe their metrics to select the right one.
We chose to experiment with Kubeflow for a while because it works de facto with Kubernetes (which is how we have been orchestrating our production platform for two years now), it has a relatively strong community (although it is lacking a more complete documentation), it is compatible with every cloud provider and the user experience seemed suited to our needs (being able to organise seamlessly our runs by experiment).
After figuring out that a switch to Kubeflow was needed, we looked into the best way to implement it.
Switching From Gitlab’s Jobs to Kubeflow’s Pipelines
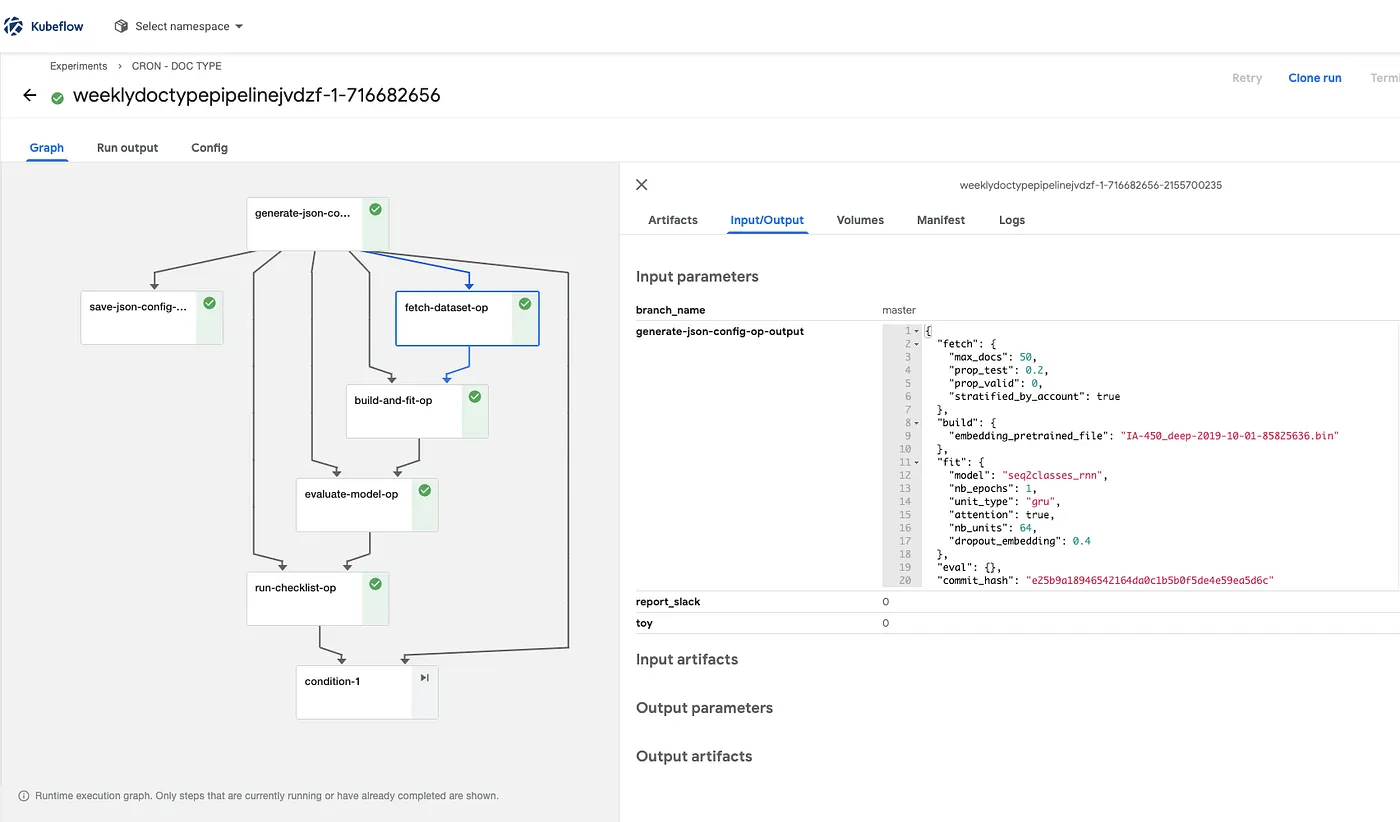
Most of our Gitlab pipelines were made of four consecutive jobs (fetch_dataset, build_and_fit, evaluate_model, report). These jobs are mainly Python methods launched with docker-compose and the full pipeline is orchestrated by a gitlab-ci.yml file.

In Kubeflow, things are a little bit different as everything is written in Python (a combination of pure Python and Kubeflow DSL), after which a compiler translates the Python code into an Argo Workflow describing how to successively run Kubeflow components inside a k8s pod.
We started to transform our methods into self-contained code using a func_to_container_op decorator.
Finally, we wrote a pipeline generator
Doing that enables us to have:
- A pipeline per algorithm
- Default configuration for each algorithm, neatly defined in a typed dataclass
- A way to simply override defaults through Kubeflow’s UI
Continuous Learning
After migrating Gitlab jobs into Kubeflow pipelines, we had to find a way to integrate Kubeflow into our CI/CD workflow in order to:
- launch a pipeline from a specific branch (for a new algorithm, for example);
- update our pipelines and recurring runs with the master branch; and
- launch toy learnings when the master branch is updated on each pipeline.
With Gitlab, meeting these objectives was pretty easy, however, there is no CI integrated within Kubeflow. The Kubeflow API is well documented (compared to Kubeflow in general) and does the job pretty well as you can tell from the script below.
We started by moving some Gitlab runners to our Kubeflow cluster, so that it could communicate easily with it. Then, we cleaned our 400 lines of .gitlab-ci.yml , to only the following:
.kubeflow_job: &kubeflow_job
script:
- pip install poetry
- poetry config virtualenvs.create true
- poetry install --no-interaction --no-dev
- export SCRIPT="pipelines.$CI_JOB_NAME"
- export JIRA_TOKEN=$JIRA_TOKEN
- export JIRA_USER=$JIRA_USER
- poetry run python -m $SCRIPT -c ${CI_COMMIT_SHA:0:6} -b $CI_COMMIT_REF_NAME
kubeflow_pipelines_update:
image: python:3.8.2
tags:
- lifen-dev-training-ia
<<: *kubeflow_job
kubeflow_toy_learning:
image: python:3.8.2
rules:
- if: '$CI_COMMIT_REF_NAME == "master"'
when: always
- when: manual
tags:
- lifen-dev-training-ia
<<: *kubeflow_jobWhere kubeflow_pipelines_update and kubeflow_toy_learning are simple scripts that upload new pipeline versions for each commit and launch toy learning for each commit on master.
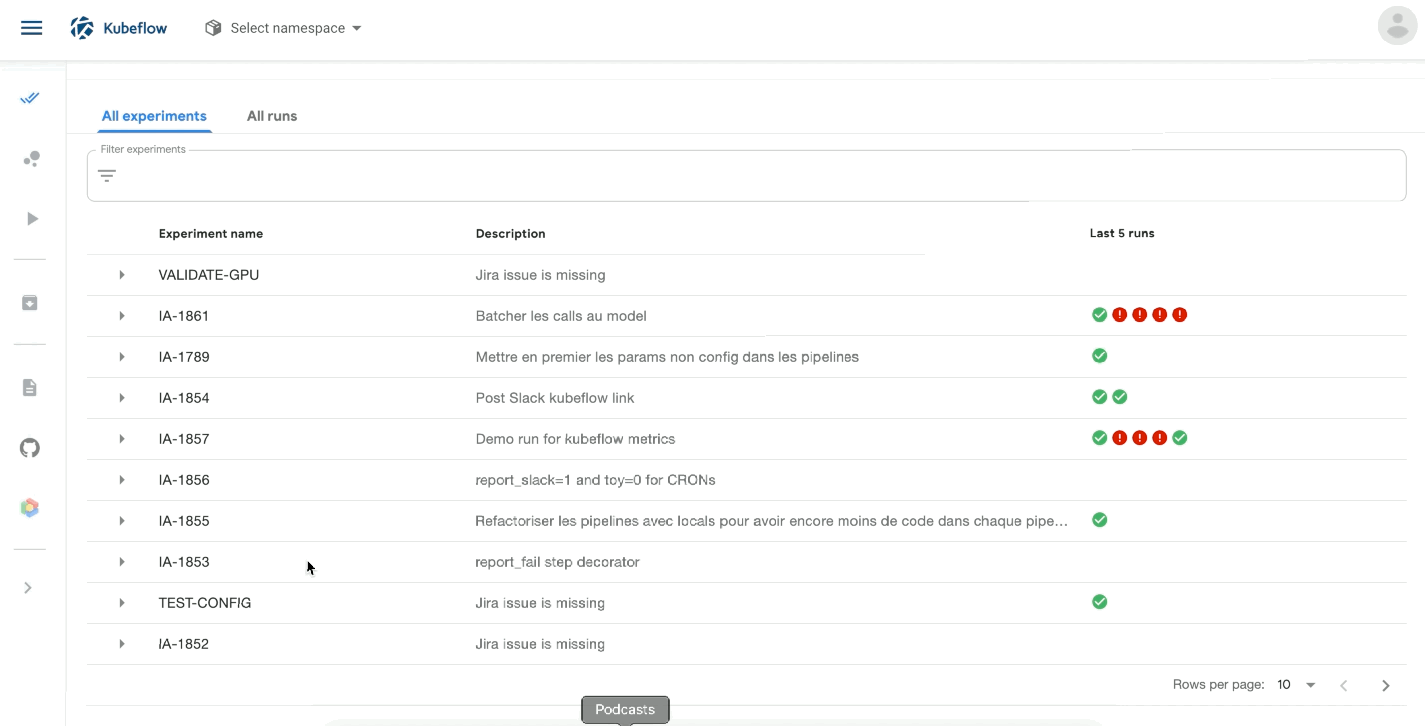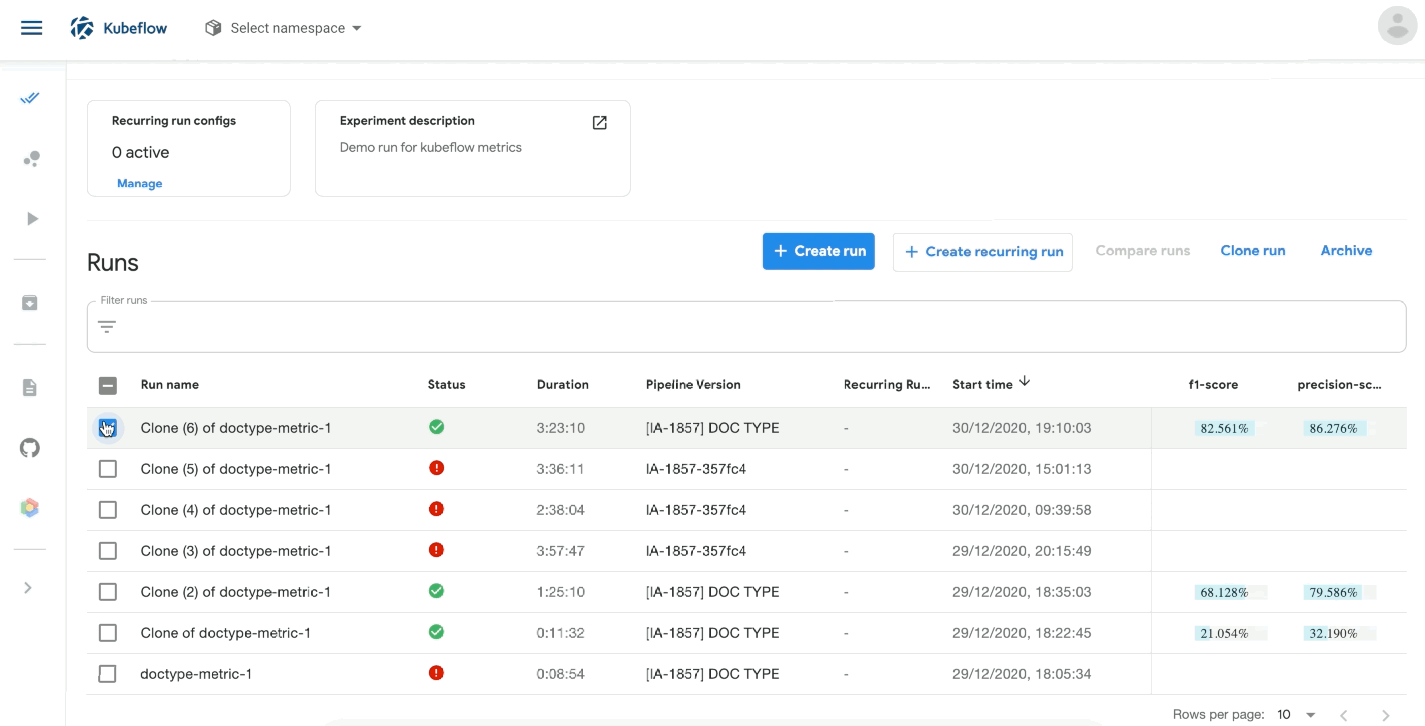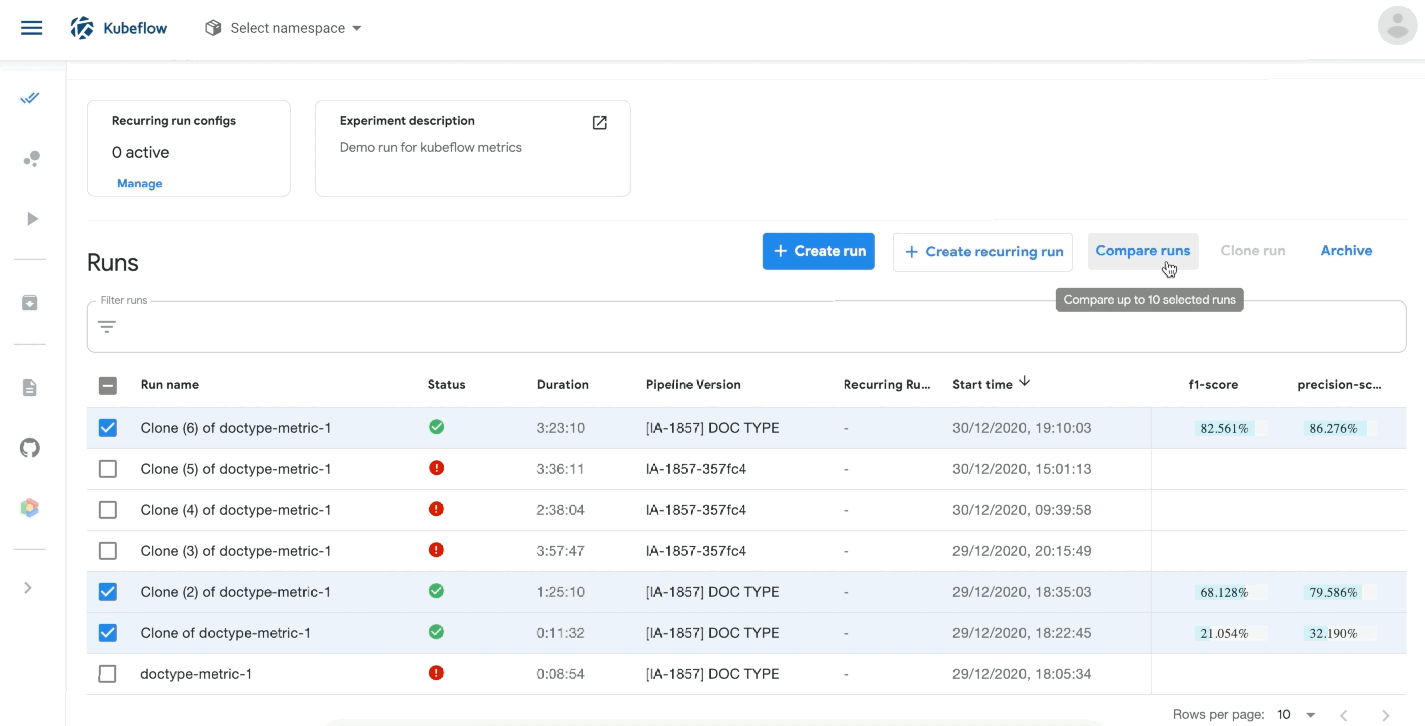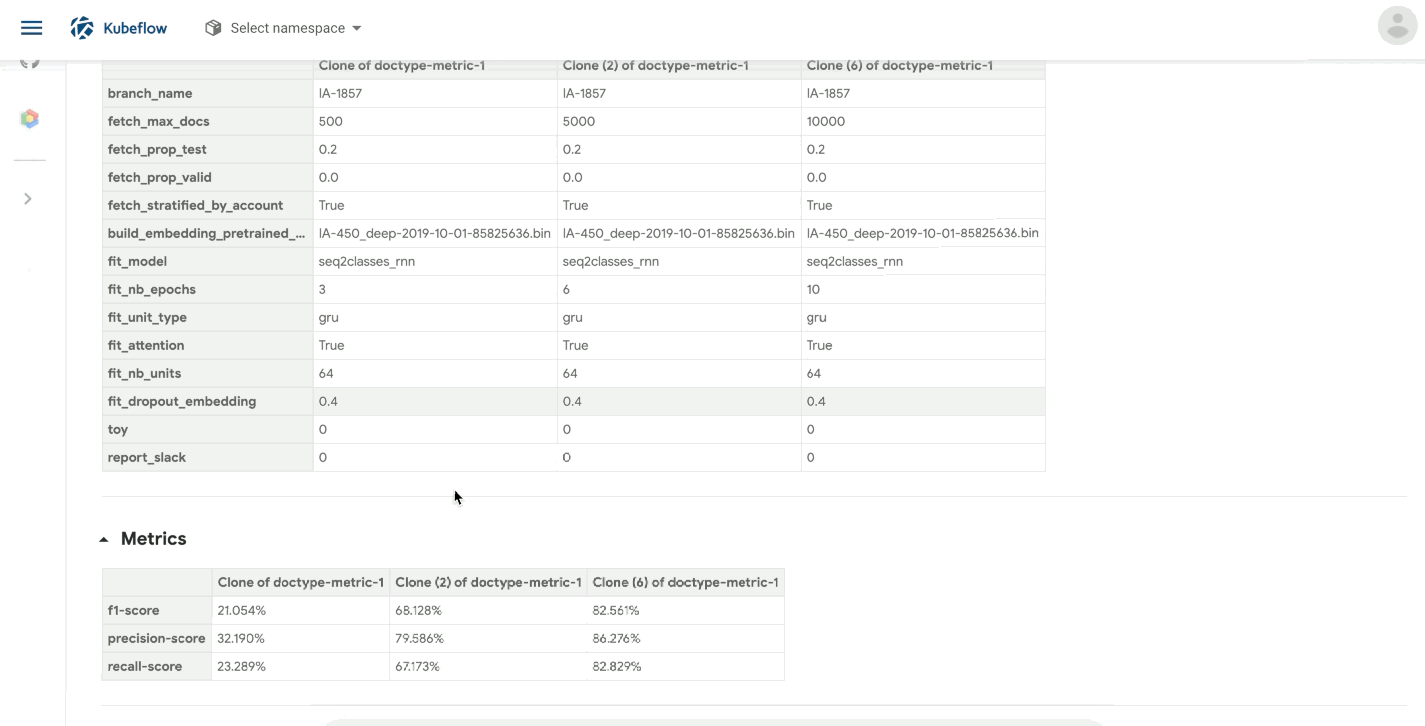
We also took advantage of Kubeflow to better organising our runs: kubeflow_pipelines_update creates a bucket on Kubeflow, with multiple runs (an “Experiment”) named after the branch on which we are working and with the branch’s JIRA description as shown below: [IA-1742] DOC TYPE
Conclusion
Migrating one of your core tools is never easy. We took the time to experiment with Kubeflow on a k3s cluster for a while before releasing it internally. This time was much needed as the Kubeflow documentation is lacking in terms of description of its setup, but we managed to find the information we were looking for every time, thanks to the Kubeflow community.
For now, we are overall happy with our decision, as we are able to visualise, compare and better organise our trainings, and we look forward to digging deeper into Kubeflow’s features and leveraging its full potential. However, the road to a perfect setup is taking longer than expected. MlOps is not a mature ecosystem, but we’re slowly getting there :)
Many thanks to Felix Le Chevallier, Clement and Marc for their help with this very interesting journey, and the whole data science team for the patience and the precious feedback during this migration. We have a lot of open positions , don’t hesitate to contact us if you are interested !
