Machine Learning: Decision Tree Classifier
A decision tree classifier lets you make non-linear decisions, using simple linear questions.
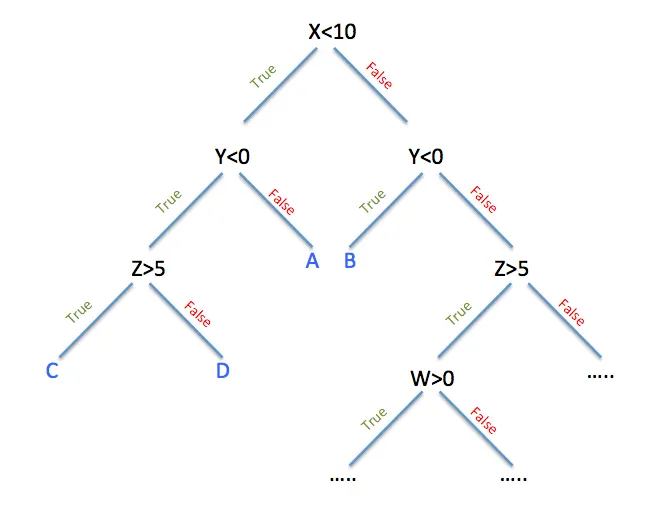
As noted in a previous blog (https://medium.com/@mikecavs/machine-learning-supervised-learning-classification-4f44a91d767#.5rqr5srd1), a decision tree classifier deals with different parameters and, depending on the response over each parameter, splits the data until a final answer is reached.
What the machine does is to select the best attribute that can split the data and can give as much information as possible. That is how the machine selects the best decision tree among many.
Although, it is important to understand that the more we split the data the more we risk overfitting the data.
This concept can be understood by taking a closer look at one of the parameters available in the “sklearn” library, used to build this sort of classifier.
http://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
“min_samples_split” is the parameter that tells the machine the “granularity” of the data we want to reach. The default value is 2, which means that the algorithm will continue to split the data until it reaches a node where there are at most 2 samples.
Intuitively, we can gather that if we are in this condition, than there is a high probability of overfitting, since the algorithm will try to cover pretty much all the data. In fact, if we increase this value we can see that the complexity and the “depth” of the tree diminishes and therefore it avoids overfitting our data.
Surprisingly, increasing the “min_samples_split” parameter increases also the accuracy of the algorithm.
One of the main, fundamental concepts to understand how a decision tree classifier works, is introduced by “entropy”. It is a measure of the “impurity” found in a bunch of examples.
Entropy controls where a decision tree decides to split the data.

In a decision tree we try to find variables and split points that make the subsets as pure as possible, therefore with the lowest value of entropy.
If all the examples are of the same class then the entropy value is zero. So we want to arrive to a node that splits the data into 2 complete separate classes, meaning each side of the node has zero entropy.
On the other hand, if the examples are evenly split between different classes, then the entropy is at the maximum, 1.
To further understand this concept, it is important to reference the “information gain” which is intrinsically connected to the entropy.
In mathematical terms, the “information gain” is defined by the “entropy of the parent” less the “weighted average entropy of the children”.
A decision tree algorithm aims to maximize the information gain. This is how the machine chooses which feature to split on.
So we simply want to arrive to a node that splits the data “clearly”.
Let’s say we have a bunch of 12 examples containing two different classes, 6 identified as A and 6 as B. If a node further splits the data into two smaller samples, each one containing 3 units of A and 3 units of B, we can clearly see that we haven’t gained much information compared to before the split. We just have divided the 12 examples into two parts of 6 but the content of each is still “unclear”. We still don’t know which one to choose as they both contain the same amount of A and B.

If, instead, the node splits the data in two parts where on one side we have 6 units of A and on the other we have 6 units of B, then we have much clearer information about the data. On one side we have all the As and on the other all the Bs. Therefore we gained the greatest amount of information to properly answer a question (which could be “which side should I go if I want have an A?”).

The entropy on each side of the data is zero. Both are “pure” as they contain examples of the same class (A or B).
This blog has been inspired by the lectures in the Udacity’s Machine Learning Nanodegree. (http:www.udacity.com)
