Machine Learning : Supervised Learning -classification
Before diving into a classification learning model, I would like to define key words used in supervised learning.
- Instances: vectors of attributes that define what the input space is.
- Concept: the function that maps inputs to outputs.
- Target concept: the answer we are looking for; what we are trying to find.
- Hypothesis class: a set of all concepts (functions) that we are willing to entertain.
- Sample: the training set. The collection of all the inputs paired with a label, which is ultimately the correct output.
- Candidate: the concept that might be the target concept.
- Testing set: used to verify the candidate concept, looking if it does a good job on the testing set, therefore if it can generalize well.
One of the models used for classification is the decision tree. (more on this at the following blog: https://medium.com/@mikecavs/machine-learning-decision-tree-classifier-9eb67cad263e#.38pwmn9xv)
To start a decision tree we need to identify the features about our inputs and evaluate them in order to reach the output.
We start from a particular attribute of the inputs and ask a question about it, represented by a node. The response to the question is the edge of the tree, which leads to other nodes or to the actual output.
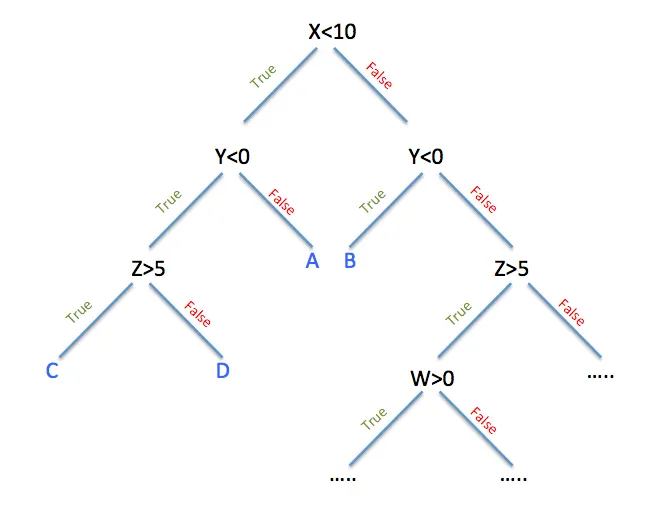
The best way to start is to first pick the attribute that best narrows down the possibilities and then move on, following the answer path, until we reach the answer.
As we start getting familiar with this model, we can soon realize that each case could be depicted by different decision trees. So it’s important to find the one that starts with the best attribute and reaches the answer faster.
The best attribute can be defined as the one that provides the largest gain in amount of information we can gather.
As a matter of fact, the gain of picking a certain attribute among a collection of training examples is mathematically defined as the difference between the measure of randomness and the average entropy over each set of examples.
The best attribute is simply the one which minimizes the entropy, therefore maximizes the gain.
The algorithm that reflects this statement and therefore picks the best decision tree is the ID3 algorithm. It’s defined as a “top-down” learning algorithm.
It basically creates a good split at the top of the tree and finds the shortest tree.
This blog has been inspired by the lectures in the Udacity’s Machine Learning Nanodegree. (http:www.udacity.com)
