The Ultimate Guide to Vector Database Landscape — 2024 and Beyond
In a world burgeoning on the brink of a fourth industrial revolution, almost every nuance of human interaction is becoming digital. In this landscape, companies are not just evolving into software entities; they’re seamlessly integrating AI into their fabric, often in ways invisible to the naked eye.
As we navigate this digital world, a fascinating development emerged this year in the realm of data management. The landscape of databases, already vast and varied (over 300 databases according to Dbengines), witnessed the birth of yet another new category — Vector databases. This innovation, driven by the meteoric rise of Generative AI and the widespread adoption of Large Language Models (LLMs), is transforming the way we handle data.
Just a year ago, when OpenAI unveiled ChatGPT, it became a beacon, highlighting the potential of LLMs. Yet, these models, like ancient sculptures, were frozen in time on the data they were trained on, not reflecting the dynamic and vast data universe of modern enterprises.
Enter the age of Retrieval Augmented Generation (RAG) — a software pattern that relies on the power of meaning-based search by turning raw data into vectors. This is where vector libraries and databases enter the stage, transforming data into a format ripe for AI’s grasp.
As we delve into Google trends, tracing the trajectories of RAG and vector databases, a parallel pattern emerges, mirroring the growing interest and necessity of these technologies in our digital journey.


With the emergence of both RAG and vector databases, as developers we are now faced with a dizzying set of choices on how to build enterprise generative AI applications and what to choose when it comes to vector stores. This article goes into the details of the high-level categories for vector stores and attempts to lens this new market from the perspective of how to build generative AI applications at enterprise scale.
Understanding RAG
A lot has already been written about RAG so let us cover the basics here.
Basics of RAG:
● RAG involves searching across a vast corpus of private data and retrieving results that are most similar to the query asked by the end user so that it can be passed on to the LLM as context.
● Most of the data that is searched and retrieved typically involves both unstructured and structured data. For most unstructured data, semantic or meaning based search is used and traditionally it has been also a technique to search across images and also to find anomalies in data and to some extent, classifying data.
● What was different this time around is the fact that with the introduction of LLMs, embedding models that could convert data into vectors thereby codifying their meaning by calculating the distance between similar data, could now be allowed to build all LLM apps that needed context to data it was not trained on.

Now that we understand the basics, let us look at three simple steps in order to use semantic search for RAG use case:
Step 1 — Create embeddings or vectors using a model — Vectors can be created using models that are either free and open sourced or they can be created by calling API end points that are provided by companies like OpenAI.
Step 2 — Store vectors — This is where vector libraries, stores or databases come in. A vector is a set of numbers that are separated by commas and can be stored using either a vector library in memory, or by databases that can store these numbers in an efficient manner. A database can store vectors as different index types that makes the storage and retrieval faster for millions of vectors that may have more than a thousand dimensions.
Step 3 — Search and retrieve using vector functions. There are two popular methods to measure similarity between vectors. The first one is to measure the angle between two vectors (cosine similarity) and the second one is to measure the distance between the objects being searched. In general, the results could be for an exact match or an approximate match — exact K Nearest Neighbor (KNN) or Approximate Nearest Neighbor (ANN).
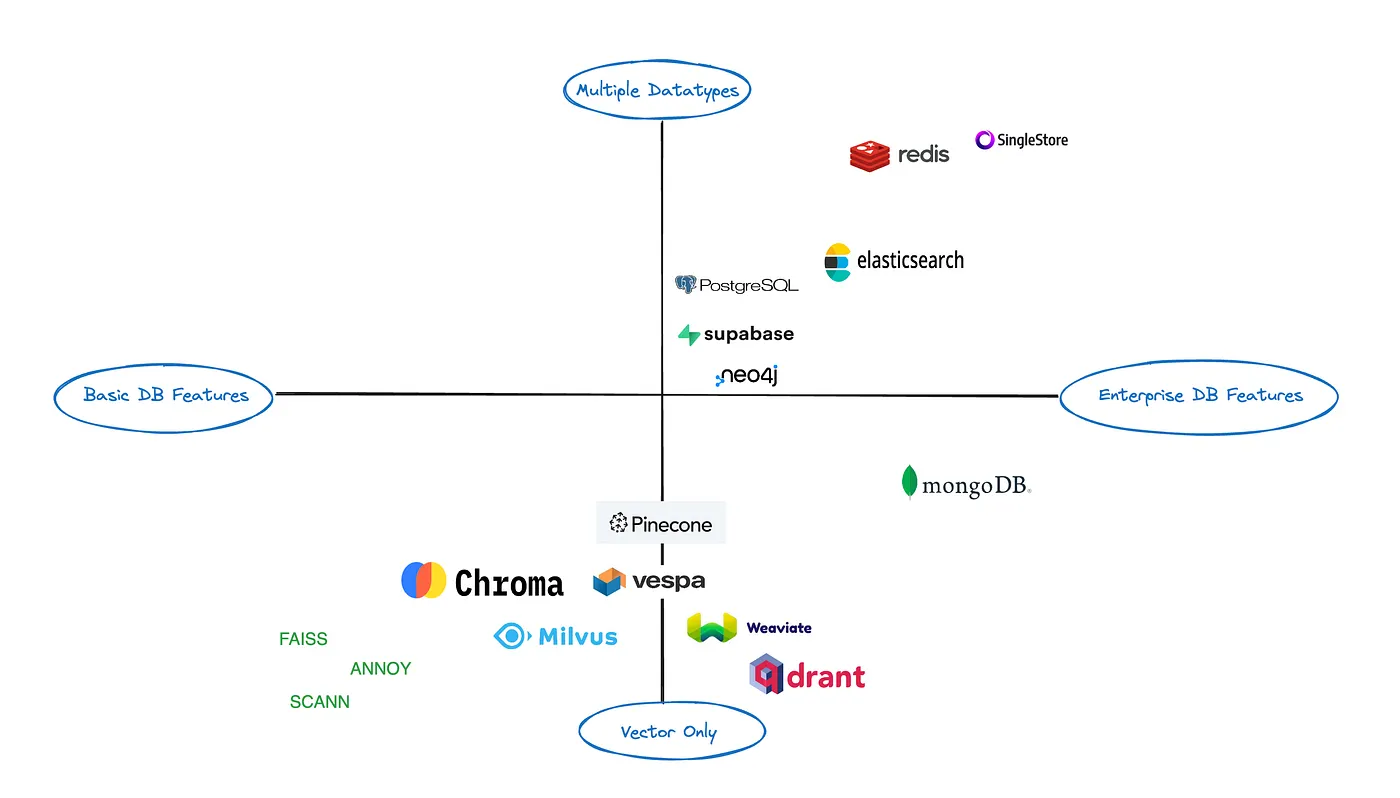
Keeping these three things in mind, the world of vector stores falls under three broad categories — Vector Libraries, Vector-only Databases and Enterprise Databases that also support Vectors.
Vector Libraries (e.g., FAISS, NMSLIB, ANNOY, ScaNN)
There are a few well known open-source libraries that can be used directly in the application code to store and search vectors. These libraries typically use the computer’s memory space and are not scalable as enterprise databases but good for small project. The most popular libraries include FAISS, which was released by Meta, Non-Metric Space Library (NMSLIB), Approximate Nearest Neighbor Oh Yeah (ANNOY) by Spotify and Scalable Nearest Neighbors (ScaNN).
Vector-Only Databases (e.g., Milvus, Pinecone etc.)
Vector-only databases are usually built only for vectors. Some of these are open-sourced while others are commercially available. However, most of these are not usually scalable beyond a point and lack enterprise grade features like multiple deployment option (on-prem, hybrid and cloud), disaster recovery (DR), ACID compliance, data security and governance and multi-AZ deployments etc. For smaller projects and prototypes this works well as they can be spun up very quickly and then can be used to search against PDF or other unstructured data files. In addition, one has to keep in mind that these databases only store vectors with a small amount of meta data about the data itself so in order to retrieve the full text or the file, for example, the application code needs to make two calls — one to the vector database to get back the search result and then based on the meta data, a second call to get the actual data. This adds up quickly depending on the complexity of the applications and if the data is sitting across multiple databases.
Enterprise Databases with Vectors (e.g., MongoDB, SingleStore, Neo4J):
In addition to vector libraries and specialized vector databases, this year also saw almost all the major databases add vector capabilities to their feature set. Some examples include MongoDB, Neo4j, Couchdb, and Postgres etc. Among the hyperscalers, AWS introduced vector support in OpenSearch Service, MemoryDB for Redis, Amazon DocumentDB and Amazon DynamoDB. Similarly, Google introduced Vectors in AlloyDB for PostgreSQL through the open-source extension pgvector. One enterprise database that already had Vectors since 2017 in addition to support for exact keyword match is SingleStore. This year they announced support for additional vector indexes.
Two big databases — Oracle and SQL server, however, were not in this bucket but very likely to add support for native vectors in the next few months. Finally, in the data warehouse category, Databricks, added support for vectors in Nov of 2023 as well.
Overall, here are some attributes of using enterprise databases for vectors.
● Broader Data Handling: These databases offer vector handling capabilities along with traditional database functionalities like support for SQL and/or JSON data. This often means that companies may not need to buy yet another database which further complicates the data architecture.
● Versatility in RAG: The combination of structured and vector data retrieval can provide a richer context to the generative model, leading to more accurate and context-aware responses.
RAG in Action
As we saw earlier, a typical RAG architecture involves three steps:
Step 1 — Create embeddings or vectors from a vast corpus of data.
Step 2 — Store the vectors in a vector store as an index.
Step 3 — Search through the vectors by comparing the query with the vector data and sending the retrieved content to the LLM.
However, the three steps have several sub-steps, and the diagram below explains that one level deeper. For the sake of simplicity, the database is represented as one database that can support different datatypes including vector (for example SingleStore).
Let’s look at each step in more detail to understand the requirements for choosing a Vector database.

1. Creation of Embeddings and Vectors
In the world of semantic search, embeddings are the cornerstone. They are high-dimensional vectors that represent data — be it text, images, or other types — in a machine-processable format. These embeddings capture the essence of the data, including its semantic and contextual nuances, which is crucial for tasks like semantic search where understanding the meaning behind words or images is key.
The advent of transformer models has revolutionized the creation of embeddings, especially in natural language processing (NLP). Models like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer) have set new standards in understanding the context and semantics of language. These models process text data to create embeddings that encapsulate not just the literal meaning of words but their implied and contextual significance.
Options for Creating Embeddings
When it comes to generating embeddings, there are a few options:
● Pre-Trained Models: Utilizing existing models like BERT or GPT, which have been trained on vast amounts of data, can provide robust embeddings suitable for a wide range of applications.
● Fine-Tuning on Specific Datasets: For more specialized needs, these models can be further fine-tuned on specific datasets, allowing the embeddings to capture industry-specific or niche nuances. Fine tuning embedding models is more important for industries and companies that have data with entities that are very specific to that company and industry.
● Custom Model Training: In cases where highly specialized embeddings are needed, training a custom model from scratch might be the best approach, though this requires significant data and computational resources.
2. Storage of Vectors and Indexing Algorithms
A key part of vector efficiency is how it is stored in a database or library. There are several indexing algorithms that are used to cluster vectors together. These algorithms are responsible for organizing and retrieving vectors in a way that balances speed, accuracy, and resource usage.
Here are some examples of indexing algorithms.
● Inverted Indexes: Traditionally used in search engines, inverted indexes have been adapted for vector search. They map each unique value to a list of documents (or data points) containing that value, facilitating fast retrieval.
● Tree-Based Indexes: Such as k-d trees, these are efficient for lower-dimensional data. They partition the space into nested, hyper rectangular regions, allowing for fast nearest neighbor searches in lower dimensions.
● Graph-Based Indexes: Effective for handling complex, high-dimensional data. They use the structure of a graph to navigate through the data points, finding nearest neighbors by traversing the graph.
● Quantization Methods: These methods reduce the size of vectors by approximating their values, which helps in managing large datasets without significantly compromising the search quality. Quantization makes storing and searching through large volumes of vector data more manageable.
Performance and Scalability Considerations
The choice of indexing method affects a database’s performance and scalability. Inverted indexes, while fast, may not be as efficient for high-dimensional vector data. Tree-based and graph-based indexes offer more scalability for such data, but with varying trade-offs in terms of search accuracy and speed. Quantization offers a middle ground, balancing efficiency and accuracy.
3. Retrieval Using Semantic Search
In semantic search, the retrieval process begins with converting the query into a vector using the same method used for creating embeddings in the database. This query vector is then compared with the vectors stored in the database to find the most relevant matches. The effectiveness of semantic search lies in accurately measuring the similarity between the query vector and the database vectors.
Similarity Measures
The choice of similarity measure is crucial in semantic search, as it directly impacts the relevance of the search results. The most common measures include:
● Dot Product: This measure calculates the product of two vectors. A higher dot product indicates a higher degree of similarity. It’s straightforward but might not always account for the magnitude of the vectors.
● Cosine Similarity: Cosine similarity measures the cosine of the angle between two vectors. It’s particularly effective for text similarity as it normalizes for the length of the vectors, focusing solely on the orientation. This measure is widely used in NLP applications.
● Euclidean Distance: This metric measures the ‘distance’ between two points in the vector space. It’s effective for clustering tasks where the absolute differences between vectors are important.
Evaluating a Database for RAG
To evaluate how the databases listed in the article handle vector storage and retrieval, one should look at the following:
1. Multiple Datatype Support — What portion of existing data is stored in structured (for example SQL), semi-structured (for example JSON) and unstructured (for example pdfs, files etc.). If your company has a greater variety of data types, consider looking at enterprise databases with support for multiple data types (for example SingleStore).
2. Multiple Search Methodologies — If your company data is in multiple data types it is likely that you will end up doing both keyword search and semantic search. Databases like Elastic, AWS OpenSearch and SingleStore support both text-based lexical and vector-based semantic search options.
3. Data Freshness and Latency — How often do you get new data, for example through a Kafka stream, that needs to be vectorized in order to be searched through your generative AI application? It is important to keep in mind that databases with the ability to define functions and ingest pipelines make this a lot easier to handle.
4. Transactional or Analytics Use Cases — Does your application require any kind of analytics in the use case. If the answer is yes, then consider a database that can store data in columnar based data as well.
5. Prototype to Production — Answering this question requires understanding the total size of the overall data, the latency and accuracy requirements and other data security and governance requirements. For example, does your application require to take into account Role Based Access Control (RBAC), Audit and other industry level security compliance requirements and is the application and the data tolerant towards either outages and/or data loss. If the answer is more towards the Enterprise grade requirement, it makes sense to consider enterprise applications that support multiple data types, can be deployed in multiple ways (on-premises, cloud and hybrid) and can handle disaster recovery and scale with the user requirements.
Now that we have defined the basics of vectors and the requirements of a vector database for RAG, let’s look at the options of some well-known vector libraries, vector-only databases and enterprise databases that also support. I have tried to capture the different options across two dimensions in the following diagram.
Vector Libraries
FAISS (Facebook AI Similarity Search)
FAISS, developed by Facebook’s AI team, is an open-source library specialized in efficient similarity search and clustering of dense vectors. It’s particularly well-suited for large-scale vector search tasks and is used extensively in AI research for tasks like image and video retrieval. FAISS excels in handling high-dimensional data but does not directly support structured data types like SQL or JSON. It’s primarily a library, not a full-fledged database, and does not offer hosted or cloud services.
Pros:
● Optimized for large-scale vector search, efficient in handling high-dimensional data.
● GPU support enhances performance in AI-driven applications.
● Open-source and widely used in the AI research community.
Cons:
● Primarily a library, not a standalone database; requires integration with other systems.
● Limited to vector operations, lacks broader database management features.
● May require technical expertise to implement and optimize.
ANNOY (Approximate Nearest Neighbors Oh Yeah)
ANNOY, another open-source project, is designed for memory-efficient and fast approximate nearest neighbor searches in high-dimensional spaces. Developed by Spotify, it’s commonly used in scenarios where quick, approximate results are sufficient. ANNOY is a library rather than a database and doesn’t provide hosting services. It’s focused on vector operations and doesn’t natively support structured data types like SQL.
Pros:
● Fast and memory-efficient for approximate nearest neighbor searches.
● Particularly effective in high-dimensional spaces.
● Open-source and easy to integrate with other systems.
Cons:
● Focuses on approximate results, which might not be suitable for applications requiring high accuracy.
● As a library, it lacks comprehensive database functionalities.
● Limited support for structured data types.
SCANN (Scalable Nearest Neighbors)
SCANN, developed by Google Research, is an open-source library that specializes in large-scale nearest neighbor search. It offers a balance between accuracy and efficiency in high-dimensional space and is designed for use cases requiring precise vector search capabilities. Like FAISS and ANNOY, SCANN is a library focused on vector operations and doesn’t provide native support for structured data types or hosted services.
Pros:
● Balances accuracy and efficiency in vector search.
● Developed by Google Research, bringing credibility and robustness.
● Suitable for large-scale, precise vector search tasks.
Cons:
● Complexity in implementation and tuning for optimal performance.
● Primarily a search library, not a complete database solution.
● Lacks native support for structured data types.
Vector Only Databases
Pinecone
Pinecone is a vector database service designed for scalable, high-performance similarity search in applications such as recommendation systems and AI-powered search. As a fully managed cloud service, Pinecone simplifies the deployment and scaling of vector search systems. It primarily focuses on vector data but may support integration with other data types and systems.
Pros:
● Designed for scalable, high-performance similarity search.
● Fully managed cloud service, simplifying deployment and scaling.
● Suitable for AI-powered search and recommendation systems.
Cons:
● Being a specialized service, it might not cover broader database functionalities.
● Relatively newer product and struggles with production database grade features.
● Potential dependency on cloud infrastructure and related costs.
Weaviate
Weaviate is an open-source, graph-based vector database designed for scalable semantic search. It supports a variety of data types, including unstructured data, and can integrate with machine learning models for automatic vectorization of data. Weaviate offers both cloud and self-hosted deployment options and is suited for applications requiring a combination of graph database features and vector search.
Pros:
● Combines graph database features with vector search.
● Open source with support for various data types and automatic vectorization.
● Flexible deployment options, including cloud and self-hosted.
Cons:
● Complexity in setup and management due to its combination of graph and vector features.
● May require additional resources to handle large-scale deployments effectively.
● The unique combination of features might have a steeper learning curve.
Milvus
Milvus is an open-source vector database, optimized for handling large-scale, high-dimensional vector data. It supports a variety of index types and metrics for efficient vector search and can be integrated with various data types. Milvus can be deployed on-premises or in the cloud, making it versatile for different operational environments.
Pros:
● Open-source and optimized for handling large-scale vector data.
● Supports various index types and metrics for efficient search.
● Versatile deployment options, both cloud and on-premises.
Cons:
● Focuses mainly on vector data, with limited support for other data types.
● May require tuning for specific use cases and datasets.
● Managing large-scale deployments can be complex.
ChromaDB
Chroma db is an open source vector only database.
Pros:
● Suitable for applications requiring high throughput and low latency in vector searches.
● Optimized for GPU acceleration, enhancing performance in AI-driven applications.
Cons:
● It is meant for smaller workloads and prototype applications. It may not be suitable for petabyte scale of data.
Qdrant
Qdrant is an open-source vector search engine that supports high-dimensional vector data. It’s designed for efficient storage and retrieval of vector data and offers features like filtering and full-text search. Qdrant can be used in cloud or on-premises environments, catering to a range of applications that require efficient vector search capabilities.
Pros:
● Open-source and designed for efficient vector data storage and retrieval.
● Offers features like filtering and full-text search.
● Can be used in both cloud and on-premises environments.
Cons:
● Being a specialized vector search engine, it might lack some broader database management functionalities.
● Might require technical know-how for optimization and deployment.
● As a newer product, it may have a smaller community and fewer resources compared to established databases.
Vespa
Vespa, an open-source big data serving engine developed by Yahoo, offers capabilities for storing, searching, and organizing large datasets. It supports a variety of data types, including structured and unstructured data, and is well-suited for applications requiring real-time computation and data serving. Vespa can be deployed in both cloud and self-hosted environments.
Pros:
● Developed by Yahoo, providing robustness and reliability.
● Supports a variety of data types and suitable for large data sets.
● Real-time computation and data serving capabilities.
Cons:
● Complexity in configuration and management due to its extensive feature set.
● May require significant resources for optimal performance.
● The broad range of features might be overkill for simpler applications.
Enterprise DBs with Vectors
Elastic (Elasticsearch)
Elasticsearch is a widely used, open-source search and analytics engine known for its powerful full-text search capabilities. It supports a wide range of data types, including JSON documents, and offers scalable search solutions. Elasticsearch can be deployed on the cloud or on-premises and has expanded its capabilities to include vector search, making it suitable for a variety of search and analytics applications.
Pros:
● Powerful full-text search capabilities and scalable search solutions.
● Support for both text-based and vector based semantic search.
● Open source with wide adoption and a strong community.
● Supports a variety of data types.
Cons:
● Elastic uses ELSER, a black box model for vector search. This does not offer granular control as you would get in using your own embedding and search models.
● Can be resource-intensive, especially for large clusters.
● Complexity in tuning and maintaining for large-scale deployments.
● As a search engine, it may require additional components for complete database functionalities.
Mongo (MongoDB)
MongoDB is a popular open-source, document-based database known for its flexibility and ease of use. It supports a wide range of data types, primarily JSON-like documents. MongoDB offers cloud-based services (MongoDB Atlas) as well as on-premises deployment options. While traditionally focused on document storage, MongoDB has been incorporating more features for handling vector data.
Pros:
● Flexible and easy to use, with strong support for JSON-like documents.
● Scalable and widely adopted in various industries.
● Offers cloud-based services and on-premises deployment options.
Cons:
● Not traditionally focused on vector search; newer in this area.
● Document-oriented model may not be ideal for all use cases, especially analytics based.
● Performance can vary based on workload and data model.
SingleStore (formerly MemSQL)
SingleStore (formerly MemSQL) is a commercial database known for its high performance and scalability. It combines in-memory database technology with support for structured SQL queries, making it suitable for a variety of applications, including real-time analytics and transaction processing. SingleStore offers both cloud-based and on-premises deployment options.
Pros:
● Support for multiple data types like SQL, JSON (MongoDB API compatible), Geospatial, Key-Value and others
● Stores data in patented row and columnar based storage making it extremely capable for both transactional and analytics use cases.
● High performance and scalability, suitable for milliseconds response times.
● Combines in-memory database technology with SQL support.
● Offers both cloud-based and on-premises deployment options.
Cons:
● No support for Graph data type.
● Not ideal for simple prototypical applications.
Supabase
Supabase is an open-source Firebase alternative, providing a suite of tools for building scalable web and mobile applications. It offers a PostgreSQL-based database with real-time capabilities and supports a wide range of data types, including SQL. Supabase offers cloud-hosted services and is known for its ease of use and integration with various development tools.
Pros:
● Open-source alternative to Firebase, offering a suite of tools for application development.
● Real-time capabilities and supports a range of data types including SQL.
● Cloud-hosted services with ease of use and integration.
Cons:
● Being a relatively new platform, might have growing pains and evolving features.
● Dependence on PostgreSQL may limit certain types of scalability.
● Community and third-party resources are growing but not as extensive as more established databases.
Neo4J
Neo4J is a commercial graph database known for its powerful capabilities in managing connected data. It supports a variety of data types, with a focus on graph structures, and is used in applications requiring complex relationship mapping and queries. Neo4J can be deployed in both cloud-based and on-premises environments.
Pros:
● Powerful for managing connected data with graph structures.
● Used in complex relationship mapping and queries.
● Flexible deployment with cloud-based and on-premises options.
Cons:
● Specialized in graph database functionalities, which might not suit all use cases especially transactional, or analytics use cases.
● Can be resource-intensive, especially for large graphs.
● Graph databases generally have a steeper learning curve.
Redis
Redis is an open-source, in-memory data structure store, used as a database, cache, and message broker. It supports various data types, such as strings, hashes, lists, and sets. Redis is known for its speed and is commonly used for caching, session management, and real-time applications. It offers both cloud-hosted and self-hosted deployment options.
Pros:
● Extremely fast, in-memory data structure store.
● Versatile as a database, cache, and message broker.
● Wide adoption with strong community support.
Cons:
● In-memory storage can be limiting in terms of data size and persistence requirements. In addition, memory is still very expensive for all data use cases.
● Data models may not be suitable for complex relational data structures.
● Managing persistence and replication can be complex in larger setups.
Postgres (PostgreSQL)
PostgreSQL is a powerful, open-source object-relational database system known for its reliability, feature robustness, and performance. It supports a wide range of data types, including structured SQL data and JSON. PostgreSQL can be deployed on-premises or in the cloud and is widely used in a variety of applications, from small projects to large-scale enterprise systems. With the use of pgvector, you can use Postgres as a vector database. With pgvector, you can use Postgres as a vector database. Google, AWS and Azure each have versions of Postgres and pgvector offered as a service — AlloyDB, Aurora Postgres and Azure SQL Hyperscale respectively.
Pros:
● Robust, feature-rich, and reliable object-relational database system.
● Wide range of supported data types, including structured SQL and JSON.
● Open source with extensive community support and resources.
Cons:
● Can be resource-intensive and expensive for large-scale deployments.
● Does not support both transactional and analytics use cases.
● The complexity of features can lead to a steeper learning curve for new users.
Conclusion
This year we saw vectors and semantic search as one of the emerging and most popular attributes in databases due to the rise of LLMs and generative AI. We saw three categories of vector stores emerge — vector libraries, vector-only databases and enterprise databases that also added vector capabilities. In this article we looked at several of these from the perspective of building an application using RAG. I will continue to add additional databases and stores in this article as they continue to evolve in a new Updates section that will be added shortly.
