
YouTube Data API v3 in Python: Tutorial with examples
Table of Contents
- Introduction
- Prerequisites
- How to get an API key
- How to install Google API Python Client Library - API Quota
- Tip: Maximize your quota credits - API documentation overview
- Overview section
- List section
— Parameters and Response subsections
- Summary - Query template
- Example 1: Searching videos
- Difference between Search resource and Video resource
- Part parameter
- Optional parameters
- Customize the desired attributes to be retrieved with ‘fields’ parameter
- How to request responses properties along items attributes
- How to access to query responses data - Example 2: How to get videos statistical information and store the data using Pandas library
- Pandas installation
- Setting the parameters to execute search.list method
- Setting the parameters to execute videos.list method - Example 3: Retrieving chat messages from live videos
- Getting LiveChatId from live video
- Live chat messages extraction - Conclusion
Introduction
YouTube is certainly one of the most important social media platforms. About 122 million users consume a billion hours of video every day and 500 hours of content are uploaded every minute. These factors made YouTube a tremendous valuable source of data, a treasure for us the data scientists. Fortunately, they provide three different APIs to easily extract information about virtually everything stored in their servers, so these petabytes of information can be leveraged to get useful insights of a wide variety of interesting problems.
In this post you will learn how to retrieve data from YouTube using the YouTube Data API v3 in Python. I will give you an overview about the API and its documentation. At the end of the reading you will be able to understand it, which will allow you to perform custom queries. Examples of how to search videos and their details like publish date, title, description, duration and their statistical information such as views, likes and comment counts will be provided. Finally, I will show how I used this API in my project YouTube’s Live Chat Extractor, a tool to retrieve chat messages from a live video in order to use this data in natural language processing projects.
Prerequisites
It is required to have Python installed on your device. I strongly recommend the Anaconda distribution. In addition, you need to obtain an API key and install the Google API Python Client Library.
How to get an API key
First of all, you need to have a Google account. If you do not have it, you can register here.
Once you have signed up, you need to go to Google Cloud Platform.
Then, you must create a new project. Click on Select a project tab near the upper left corner, and then click on NEW PROJECT:
You will be redirected to the New Project page. Name your project, for example as YouTube Data Extraction and click on CREATE:
After that, you will be redirected to the project’s dashboard. Note the Select a project tab now has the project name written on it, than means you have the YouTube Data Extraction project selected. In case you have more projects, you can select them from this tab.
Now, you need to enable the API in this project. Click on Explore and enable APIs option within Getting Started card in the lower left corner of the dashboard:
After that, you will be redirected to APIs & Services page. Here, click on + ENABLE APIS AND SERVICES at the top of the page:
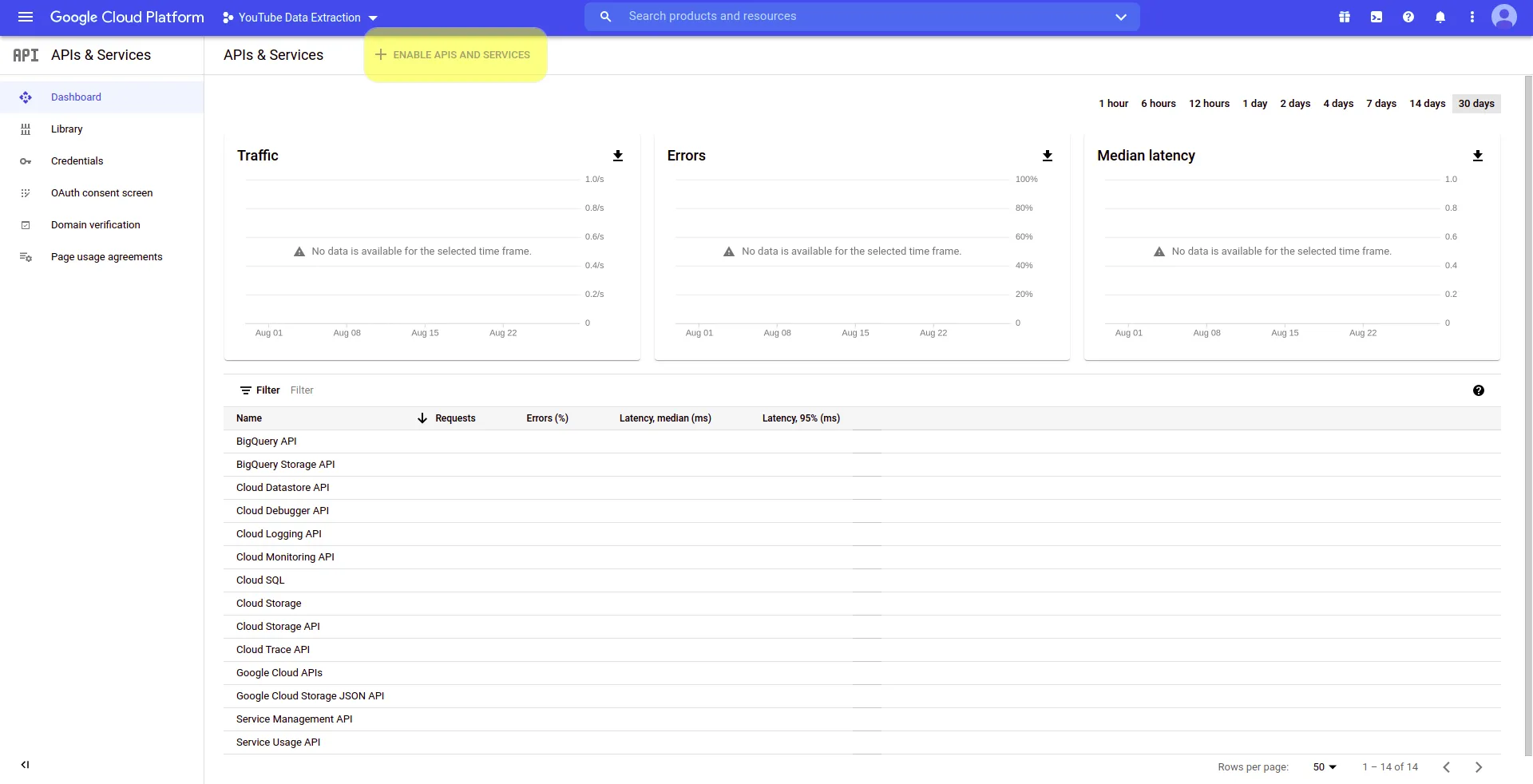
Then, you will be redirected to the API Library. Scroll down a little bit the options and you will find YouTube’s APIs. For the purposes of this article, you only need the one named YouTube Data API v3, so click on it:
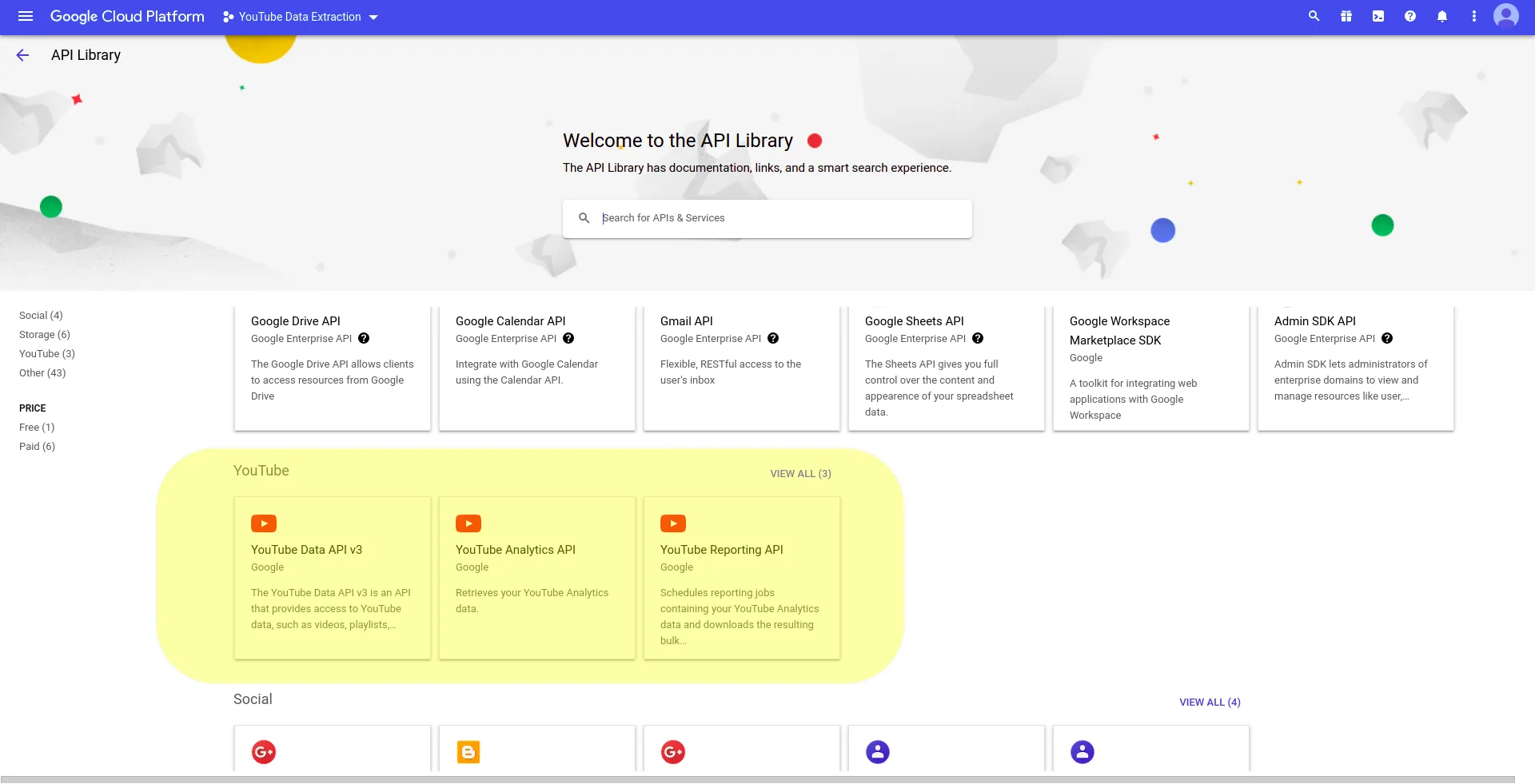
YouTube Data API v3 information will be displayed, you just need to click on ENABLE:
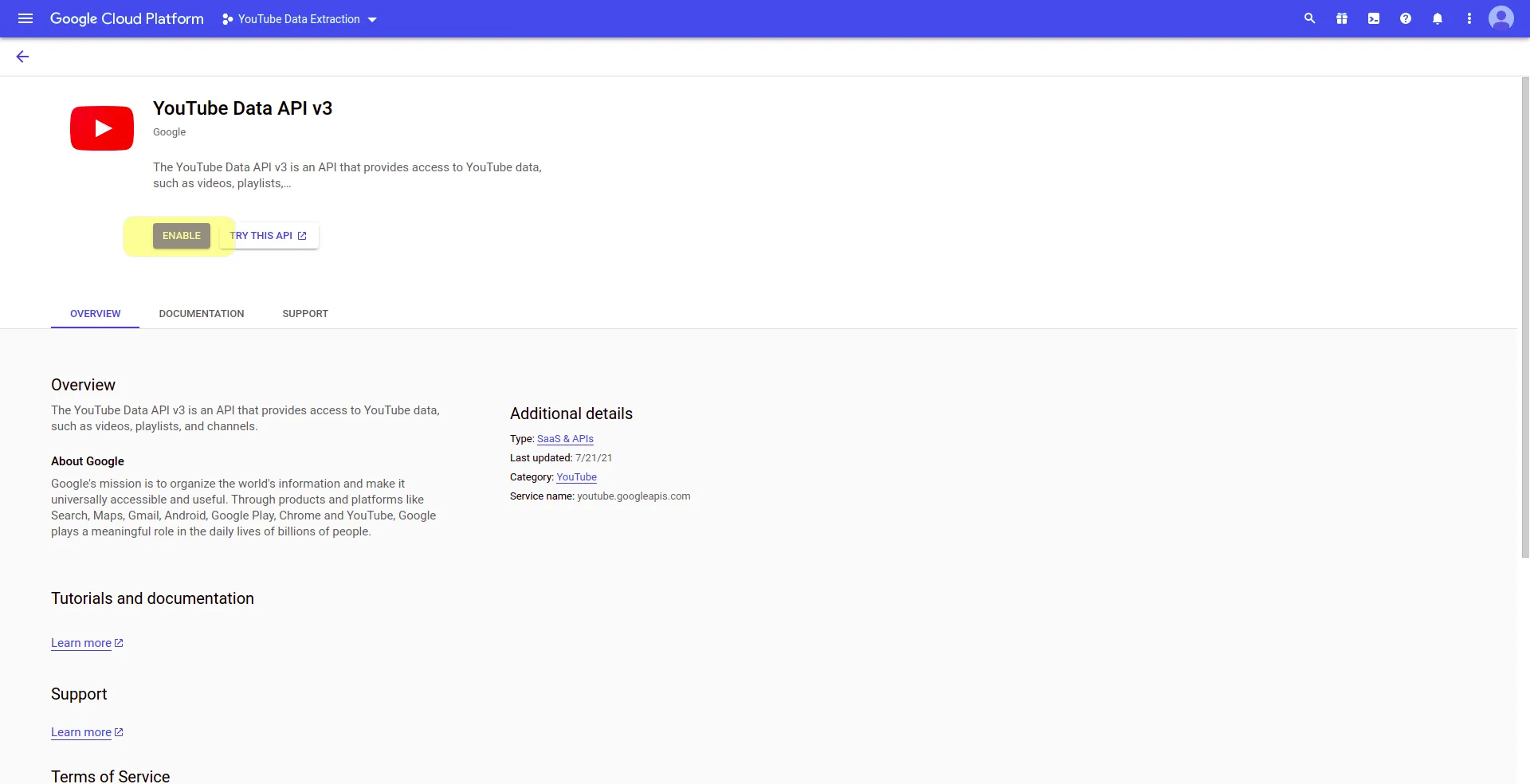
Next, you will be redirected to the API Overview page. At the top you will see the message “To use this API, you may need credentials. Click ‘Create credentials’ to get started”. Click on CREATE CREDENTIALS at the top right corner of the page:
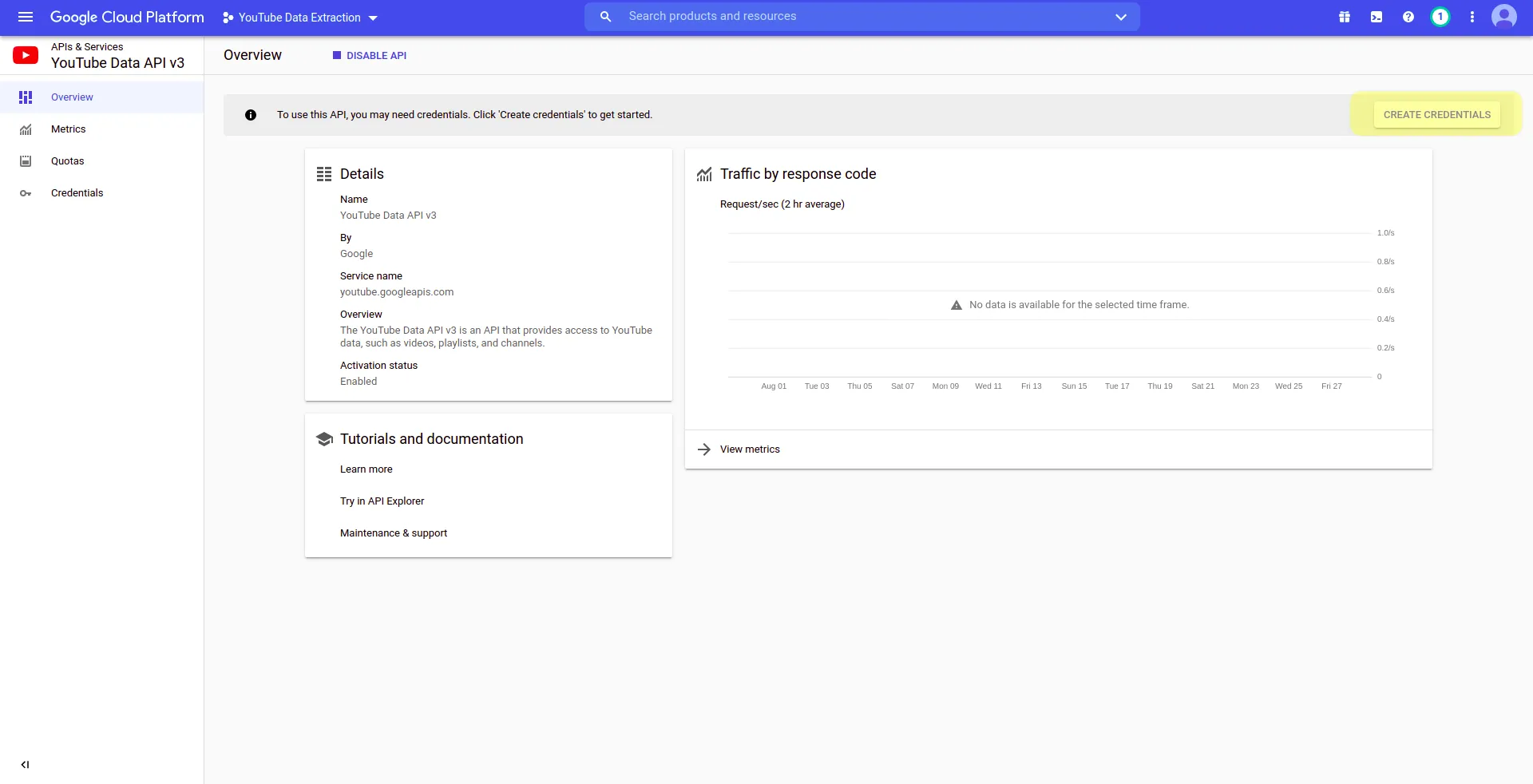
The Create credentials form will be shown. Select YouTube Data API v3 in the Select an API dropdown menu and check the Public data radio button, then click on NEXT:

Finally, your API key will be displayed. This key is mandatory in order to use the API in your programs:

You can always check the key from the Credentials screen. You can access this screen from the hamburger menu at the top left corner of the Google Cloud Platform interface:


How to install Google API Python Client Library
To perform this installation you just need to type a single instruction in the command line:
Anaconda
Pip
API Quota
Before you continue, there is something you must know. Even though the use of this API is free, there is a restriction in its usage, this constraint is called the API Quota. It is imposed to ensure quality service not allowing unfair access to greedy users, which may have a potential negative impact for other developers. The quota allocation for everyone is of 10,000 units per day. The consumption of this units is based on the methods you execute and the result size does not matter. As stated in the Quota Calculator page, a query to list videos costs 1 unit no matter if you retrieve 1 or 50 items (the maximum number of items per query in this case), so the quota allocation is pretty fair and, in general, it should be enough.
Tip: Maximize your quota credits
If you are worried about this issue, I will give you a tip: to get the maximum power register the twelve projects allowed in Google Cloud Platform, activate the API in every single one and generate twelve API keys. In this way, you will have 120,000 credits per day. If this is still not enough, you can request a quota extension but I have heard Google takes too long time to reply.
API documentation overview
The most valuable resource developers have when trying to learn a new tool is always the official documentation. You can find YouTube Data API v3 documentation here. They provide guides, samples and general references about the API functionalities. In this section I will try to explain as best as I can how to read the documentation in order to perform queries as well as to understand their structure, since it was for me a little bit tricky to get.
For our purposes, the most important part of the API documentation is the Reference tab.
As you can see at the left side of the page, there is a list of all the entities (named Resources) you can retrieve using the API.

Note that each and every single resource tab is a dropdown menu, and Overview is always the first option. For example, if you expand Channels, Search and Videos resources you will see the following:

Options below Overview (highlighted in light purple) are the supported methods of each resource. Since the goal is to retrieve data, we will focus only in list methods, but note that you can do more than that using insert, update or another available method.
Overview section
In the Overview sections you will find information on what the resources are about and the list of their available methods. However, I think the most valuable subsection is the Resource representation. For example, Videos resource looks like this:

Just below is the Properties subsection, as the name suggests, there you can find the explanation of every single property.
You can see this JSON as the dictionary of the characteristics (and their data type) of each video resource the API will provide you. There are lots and lots of properties, depend on your purposes maybe you will be interested just in a few of them, this section will be helpful for you to select only the relevant features you need.
List section
list methods will allow you to retrieve data of a given resource, hence this is the most interesting part for us. For example, if you select list method for search resource from the list of resources you will see the following:

First of all, the quota impact will be shown, not only in list method, but in the majority of methods; this is important to estimate your quota usage.
Just below, for some resources as Search and Videos you can find Common use cases subsection where code snippets for specific usage of the method will be provided in different programming languages such as JavaScript, Java, PHP and Python.
Parameters and Response subsections
The most important subsections are Parameters and Response. Parameters subsection includes the required and optional parameters to execute queries. For example, the Parameters section for Videos resource list method:

On the other hand, Response subsection shows you the dictionary of properties the query responses will include. Resources whose match with the query parameters will be contained in the items property of the response. list method of videos resource section looks like this:

The usefulness of this subsections will be clear in the practical examples.
Summary
If you are a new user of this API you may find all this information cumbersome (don’t worry, I felt the same way as you). Here, a summary about what I have just discussed:
Resources: YouTube's entities from which you can extract information.Methods: Functions which can be applied to the resources in order to extract their properties or modify them.List methods: This is the method of our interest since it can be used to retrieve collections of resources and then extract information about each one of them.Overview section: Where the resource is explained. The most interesting part here is theResource representation subsection. It will be useful since from there you will select the particular properties you want to retrieve from the resources you request.list section: Where thelist methodfor each resource is explained.
— In theParameters subsectionyou can see the required and optional parameters that can be used in order to customize the queries.
— In theResponse subsectionyou can see theResponse representationwhich includes the properties the query response has. It is important because you can also retrieve or ignore attributes of the responses.
Query template
All queries have the same structure and only few parameters will change depending on the resource you are requesting for and the method to be executed. When you select a method for any resource from the resource list, a section titled Try this API will be displayed at the right side of the page.
You can execute a query directly from this page, but I want to show how to do it from a Python script. For example, when you click in list method for videos resources you will see the following:

If you scroll down Try this API section you will see the SHOW CODE button, click on it and you will be able to see code snippets for different programming languages. For example the code snippet in Python to execute list method of Search resource, using only API key as credential (without Google OAuth 2.0), is this:

By simplifying the code a query template can be extracted:
Maybe you have not realized yet, but query execution is very intuitive. As I wrote in the previous code snippet, request variable needs to be changed depending on the resource and method you will use. To perform list method on different resources you just need to rewrite the resource name. Here some examples:
Pretty easy, isn’t it?. If you want to use a different method rather than list, the structure will be similar.
Throughout the following practical examples all the previous concepts will be demonstrated.
Example 1: Searching videos
We will start from the most basic action to perform on YouTube’s platform: Search videos. Since this is the first example, I will try to explain it with all details you need to maximize your understanding. For this purpose, you need to focus on Search list method. I recommend you to keep this site opened in your browser while you are following this reading.
Difference Between Search Resource and Video Resource
I need to clarify something to avoid confusions. Search resource and Video resource are strongly correlated but they are different. As you can see in their Overview sections, a Search resource "contains information about a YouTube video, channel or playlist that matches the search parameters specified in an API request"; while a Video resource "represents a YouTube video". So, in order to get only search results, as the ones you can see when you search some term through YouTube's search bar, then Search resources will be enough; on the other hand, if you want to retrieve the particular attributes of one video such as statistical information (likes, dislikes counts), content details (duration, definition), etc, then you will need Videos resources. For this particular example search resources will be enough. Having said this, we can begin.
Part Parameter
As you can see in the Parameters subsection of list method for search resource, there is just one mandatory parameter named part (this is required in most of cases) along other optional parameters. All this parameters must be included in the request variable.
part parameter is the most important because through this you will request exactly the properties you want to get for a particular resource. As you can see in the documentation, this must be a "comma-separated list of one or more search resource properties" . Do you remember the Overview section? well, there is where you will find these search resource properties.
In general, when you want to use list method, you need to check the Overview section for that particular resource in order to obtain the properties you need to write in part parameter.
Below is the Search Resource JSON structure, I will explain how to read it and how to set the part parameter properly.
You can see it as a Python dictionary. There are four different keys: kind, etag, id and snippet. At the same time, id and snippet contains each one a dictionary as value. First two keys (kind and etag) will be always included since every single object has these two identifiers.
Suppose you just want to retrieve title and description of the videos you will search. As these properties are included within snippet dictionary, you must set part="snippet". Similarly, if you want to get only videoId, then you should set part="id" since the property you are requesting for is contained in the id dictionary. Also, you can request properties from two or more different keys at the same time. For example, suppose you want to retrieve the following properties:
From id part:
videoIdchannelId
From snippet part:
publishedAtchannelTitletitledescription
Since you are requesting properties from id and snippet dictionaries, then you need to write: request="id,snippet".
Optional parameters
The part parameter is related to the items you want to retrieve, but optional parameters are needed in order to customize the query. Suppose you are interested in retrieve publishedAt, videoId, channelId, channelTitle, title, and description of short HD videos about Spider-Man. Then, you can see that the following optional parameters will allow you to perform this particular query:
type: To only retrieve videos and not channels nor playlists.q: To specify that the term to search is: "Spider-Man".videoDuration: To get only short videos (less than 4 minutes long).videoDefinition: To extract only HD videos.
The code to retrieve a single item, using maxResults parameter is the following:
Customize the desired attributes to be retrieved with ‘fields’ parameter
I have formatted the result of the previous query to make it more readable, but it still looks chaotic:
This happens because the API provides you every single property the search response has, including the items whose match with the given parameters. Recall: items response property is a list of search resources, and each of them includes all the properties of their id and snippet parts since they were previously requested using part parameter of the request.
To avoid this mess, you can indicate which exactly properties you want using fields parameter. In this case you do not need any search response property (such as nextPageToken, regionCode or pageInfo). In other words, you just need the items property. Besides, from each search resource item you only want:
id.videoIdsnippet.publishedAtsnippet.channelIdsnippet.channelTitlesnippet.titlesnippet.description
In the code, you need to write it as follows:
Is more easy if you think this parameter as: “I want the items field. For each item, I want to extract videoId value from their id property. Also, from their snippet property, I want to extract publishedAt, channelId, channelTitle, title and description values". The code for this query is:
Then, the response will look like this (again, i have formatted it):
Now, you have only the information you are interested in.
How to request responses properties along items attributes
Often you will need additional response properties. A common scenario is when you need nextPageToken value to keep retrieving data concurrently without duplicated items. To get this response property you just need to indicate it in field parameter. This is the code:
The result:
Now you can get this token value and assign it to the pageToken optional parameter in the next query to get a completely new set of items. This is an example:
This way you will have two different sets of unique items. If you want more items than the queries can provide at the same time, then tokens usage will be helpful.
How to access to query responses data
As you can see responses are Python dictionaries, then you can access them easily. For example you can access the previous results like this:
Example 2: How to get videos statistical information and store the data using Pandas library
At this point you are more familiar with documentation, how to build a query and how to access the obtained data, so we can advance a little bit faster.
Pandas installation
For this particular example, Pandas library will be used. The installation can be done executing the following instruction in the command line:
Anaconda
Pip
For this example suppose you are studying which pet is the favorite on US, cats or dogs. As part of your research, you will take a sample from YouTube’s most relevant videos about “kitties” and “puppies”, then you will extract their statistical information such as likes, dislikes and views. If you do so, then you can apply some data analysis techniques on this results in order to try to find which pet is the preferred one. The strategy will be:
- Search the 50 most relevant videos about cute cats in the US
- Search the 50 most relevant videos about cute dogs in the US
- For each video get the publish date, title, number of views, likes, dislikes, comments and favorite count.
For steps 1 and 2 you will need to execute search.list method; once you have this search resources, you can get the videos ids from them.
In step 3 you will use the obtained videos ids to execute videos.list method. By doing this you will be retrieving videos resources from which you can finally obtain the statistical information you are interested in.
Setting the parameters to execute search.list method
From the previous example you know how to query search resources. The following parameters will be needed. You can check this in search.list method parameters
part(required): You will need just the videos ids, sopart="id"type: To retrieve only videos and not channel nor playlistsregionCode: To get only US videosorder: To get only the most viewed videos ("relevance" is the default value, but it will be included anyway)q: To specify the terms ("kitties" and "puppies")maxResults: To get 50 itemsfields: Since you are only interested invideoId, property withinid partofsearch resources, thenfields=items(id(videoId))
The search.list method execution will look like this:
At this time, you will have 50 elements in items key of both cats_videos_ids and dogs_videos_ids dictionaries.
Setting the parameters to execute videos.list method
Next step is to use the ids to query the corresponding videos and extract their particular information; for this purpose you will need the following videos.list method parameters :
part: Remember you have to set this parameter based on videos resource properties. All statistical information withinstatisticsproperty is needed (viewCount,likeCount,dislikeCount,favoriteCountandcommentCount). To make this more interesting, alsodurationattribute will be retrieved, it is contained incontentDetailsproperty. Thuspart="statistics,contentDetails".id: In this attribute is where you will put the previously retrieved ids.fields: You just need theitemsfield, this is, you do not need anyvideo responseattribute; in addition, recall you need allstatisticsproperties, but you just needdurationattribute fromcontentDetailspart, this for each item. Hencefields="items(statistics, contentDetails(duration))"
The videos.list method execution and the code to store the information will look like this:
For me, the first 10 rows of cats.csv look like this:
Example 3: Retrieving chat messages from live videos
At this point you know how to perform custom queries. Now is time to do something more realistic. Suppose you want to perform a sentiment analysis, then YouTube live videos could be useful for you as they have embedded live chats with hundreds of people interacting via text messages expressing their opinions about the video’s topic.
As a project, I have built a script to perform this task automatically named YouTube’s Live Chat Extractor. I will explain the most important details about how it works and how to use it. If you want to check the complete source code, you can get it from this GitHub repository.
YouTube Live Streaming API is part of YouTube API v3, using it you can get access to live videos and their information, also you can create, update and manage live events on YouTube.
It is important to note that you only can get messages from ongoing live videos, it is impossible to retrieve the chat history from ended live streams.
To achieve this objective LiveChatMessages resource will be used.
The strategy will be as simple as this:
- Get the
LiveChatIdfrom the live video. - Extract
LiveChatMessagesfrom the correspondent live chat.
Getting LiveChatId from live video
As you can see in the Videos resource properties they have the liveStreamingDetails property. This will be present only when the video was, is or will be a live broadcast. This property includes activeLiveChatId attribute, is needed to request for it as follows using the live video Id contained in args['videoid]:
liveBroadcastContent within snippet property is requested for validation purposes. This will be None if the video is not a live event or if the live broadcast has ended.
If everything is okay, then you need to extract the activeLiveChatId with:
You need to be careful with this, since activeLiveChatId only will be available if the live video has the live chat activated. You can handle this issue with a try-except block.
After this, you can extract messages until the live stream ends or the daily quota is exceeded, whichever comes first. Also, YouTube’s Live Chat Extractor allows you to stop the execution at any time and all the retrieved messages until then will be stored in a .csv file.
Live chat messages extraction
Recall, to extract messages you will be requesting LiveChatMessages resources using its list method. As you can see in the LiveChatMessages list method parameters, you must provide liveChatId and part parameters. Also, maxResults and pageToken optional parameters will be used, the later to retrieve only non-repeated messages each time the query is executed.
We are interested in the message itself, its publish date and its author. If you take a look at the liveChatMessages resource representation you can see publishedAt and displayMessage attributes within snippet property contains the publish date and the text messages. On the other hand, channelId and displayName attributes in authorDetails property contains the author information. Knowing this you can set part and fields parameters properly. Recall you need the page tokens to retrieve unique messages. Then, nextPageToken will also be requested in fields parameter as follows:
The results of this first query will be stored in a dictionary, at the end of the program execution this dictionary will be converted into a .csv file:
Finally, this routine will be wrapped up into a While loop to keep retrieving 1,000 new messages every 10 seconds until the quota is exceeded, the live video ends or the user interrupts the execution, whichever happens first. You can tune the waiting time along the maxResults parameter to maximize the quota usage:
And that’s it!. Remember, this code is part of the YouTube’s Live Chat Extractor Project. To execute the program by yourself from the command line, you need to do it as follows:
Where
-k / --apikey: (string) A valid YouTube Data API v3 key.-i / --videoid: (string) Id of the live video. For example, if the complete video's URL is: https://www.youtube.com/watch?v=N-80sVfbAno, then you need to set-iparameter as N-80sVfbAno (string assigned to 'v' URL parameter).-o / --outputfile(Optional): (string) Desired name for the output file. If not given, the messages will be saved asresults.csv. The file will be stored in the current directory.-v / --verbose(Optional): (int) Whether you want chat messages to be displayed on console or not: 0=no, 1=yes (by default).
Conclusion
Google and YouTube are huge sources of data. We can get a lot of information from their servers using their tools such as YouTube’s APIs in order to gather massive amounts of a wide variety of data, from videos statistical information, to live text messages; then we can perform data science’s tasks such as sentiment analysis and more.
We have seen APIs are powerful weapons for us the data scientists to achieve data retrieval, one of the most crucial parts of our work in an easy and fast manner.
Finally, I want to say that even though every data scientist must know how to perform data retrieval tasks and should learn fast how to use tools like APIs by themselves, we can always make our contributions. This time I am glad to have made my humble contribution to the wonderful data science community with my YouTube’s Live Chat Extractor, I really hope you find it useful. By contributing we help each other to overcome minor obstacles and boost our colleagues work so great scientific results could be achieved quickly.
