Next Stop for TRAM
Exploring the Application of Large Language Models
Written by jackie lasky

Are you struggling to keep up with rapidly evolving threats to your organization while still trying to optimize your automation capabilities? In today’s digital age, cybersecurity threats are ubiquitous. They can result in financial losses, reputational damage, legal liabilities, operational disruptions, and more. Our community is constantly identifying and documenting new threats that lead to a volume of cybersecurity information that is increasingly difficult to manage. MITRE ATT&CK® provides a framework to make cyber threat intelligence (CTI) actionable by categorizing and tracking what adversaries are doing, in what ways, and against which targets. This manual process, and the volume and velocity of released CTI information often overwhelms the capacity of analysts.
With all of that in mind, we’re happy to announce that the Threat Report ATT&CK Mapping (TRAM) project is coming back! Our tool, TRAM, is poised to transform your automation capabilities and help you stay ahead of emerging threats. The project is designed to advance research into automating the mapping of CTI reports to ATT&CK. TRAM will enable researchers to refine Machine Learning (ML) models for identifying ATT&CK techniques in prose-based threat intelligence reports and allow analysts to validate and export the ML results. We want to accelerate research into automated TTP identification in threat intel reports to greatly reduce the time and effort required to integrate new intelligence into cyber operations. TRAM aims to shorten the time it takes to analyze a report by assisting analysts with the identification of ATT&CK techniques in reporting. Automated assistance will also aim to improve accuracy of mappings and strengthen agreement between analysts. This will help the cybersecurity community keep up with threats.

Through research into automating the mapping of CTI reports to ATT&CK, TRAM will improve the community’s understanding and adoption of ATT&CK.
A little bit of the past, and a lot of the future…
In today’s hyper-connected digital landscape, companies cannot afford to ignore the critical interplay between automation and cybersecurity. The future of our cyber health will depend on our ability to explore and leverage automation and find ways to incorporate it into our workflow. Cybersecurity is no exception to the commonly faced issue of having “too much data, not enough people to analyze”.
To help with this data problem, TRAM uses a supervised learning classification method, logistic regression, to predict ATT&CK techniques on unseen text in public threat reporting. The weakness of TRAM 1.0 came from using word frequencies as inputs for the classifier, which is why we’re looking to explore other types of models that can help strengthen the overall prediction accuracy. However, with the most recent release of popular Large Language Models (LLMs) such as GPT-3 or BERT, we wanted to explore the potential of classifiers built using these transformer model structures to apply to some of the current problems facing the community.
LLMs are an area of Artificial Intelligence (AI) where systems are trained on an incredibly large volume of textual data which allow them to analyze, process, and generate creative human-like answers to user-defined prompts or questions. Why is this useful for a system such as TRAM or other types of automated text classification? It’s increasingly difficult to keep up with the amount of cyber reporting that gets released as well as have in place the expert annotators to properly tag this data to the ATT&CK model. This could help reduce time spent by the machine learning developers on feature engineering. We’re looking to improve the prediction accuracy by collecting additional training data and by using these models to fine tune TRAM. Ultimately, by keeping up with the volume of CTI data, companies can take proactive steps to identify and mitigate vulnerabilities before they are exploited by malicious actors. This will enable them to be better positioned to protect their digital assets, ensure business continuity, and safeguard their information and reputation over time.
Exploring the Potential of LLMs with GPT-3 & Transformer
With just a small amount of initial exploration into what these models can do, we experimented with OpenAI’s ChatGPT interface by asking for it to read a report and tell us which ATT&CK techniques it contains, as if it were a human analyst reading the report. We selected an open-source report that was used in the original TRAM training set since the labels have already been clearly documented. A PDF report was used, noting that PDFs are traditionally much lengthier in text than vendor site reports. The ATT&CK annotations from MITRE were mapped to version 6.0 of ATT&CK, whereas the current version of ATT&CK is now 12.1. The ChatGPT test run was zero-shot, meaning it was not trained using the TRAM training dataset and still produced surprisingly fruitful results. This makes us optimistic for the type of results we can expect when we test our new models.
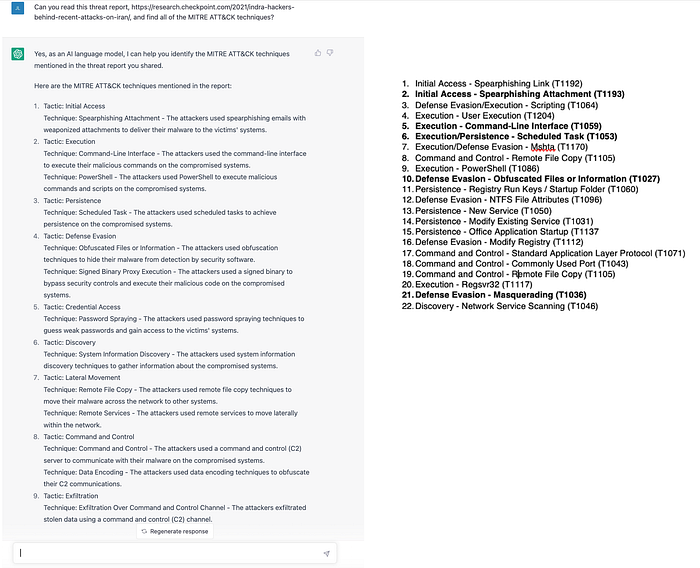
Why is this important for TRAM?
Although ChatGPT didn’t find nearly all the ATT&CK techniques; it shows the potential of LLMs and how they can be leveraged for tuning existing models beyond the supervised learning classification alone. These models might also be able to help with the missing data for techniques that don’t have sufficient examples as well for providing supplemental annotations of ATT&CK techniques to help flesh out those models further. LLMs could also help analysts with the tagging of threat reports. Having an actual human SME to review and approve the annotations will still be needed, but this could produce additional mappings at a quicker speed to tune the logistic regression training models we currently have in place.
Who else is exploring similar ideas around automation of cybersecurity threats and indicators?
There is a lot of anticipation and excitement around the potential of these models, especially if they are applied to cybersecurity problems. Many cybersecurity researchers are exploring ideas around how this can be applied and used to keep up with emerging threats. Limitations do exist around having enough resources to train and run these models, but the results of early research are promising.
There’s high interest in industry to explore this kind of research, for example, take a look at Microsoft’s MitreMap tool. They released a Jupyter notebook that allows you to provide a threat report and it tries to predict the ATT&CK techniques and Indicators of Compromise (IoCs) using the Distil-GPT-2 transformer model. If the Center for Threat-Informed Defense can collaborate to bring together large datasets, AI experts, and ATT&CK analysts, then perhaps we can get closer to keeping up with and solving some of our most challenging cybersecurity problems.

Have data you want to contribute? Want to get involved?
Additional annotated training data is needed to improve the accuracy of the current classification models, so we’ll be focusing our efforts on building out the dataset more.
If you have any form of annotated ATT&CK data that you think might be useful for TRAM, please reach out to ctid@mitre-engenuity.org and contribute!
Stay tuned and follow the Center for more updates as we go!
About the Center for Threat-Informed Defense
The Center is a non-profit, privately funded research and development organization operated by MITRE Engenuity. The Center’s mission is to advance the state of the art and the state of the practice in threat-informed defense globally. Comprised of participant organizations from around the globe with highly sophisticated security teams, the Center builds on MITRE ATT&CK®, an important foundation for threat-informed defense used by security teams and vendors in their enterprise security operations. Because the Center operates for the public good, outputs of its research and development are available publicly and for the benefit of all.
© 2022 MITRE Engenuity. Approved for Public Release. Document number CT0066.

