Boosting- Ensemble meta Algorithm for Reducing bias
Ensemble learning Series…!!!

{kind=link}
Unity is strength you can already know that we have already listen the story in our childhood. if you haven’t listen the story don’t worry below is the video just listen. So, you can understand better what is concept all about.
Finally, you understood after watching this video right. Let me tell you if you are together work for something it’s like team work which build your strength. what this story is all about. that’s why I used word. Unity is power. Let me explore now about boosting, what we all are here to discuss.But before this if you haven’t read previous article series go below links and read.
Ensemble learning Series — (Happy Learning…!!!)
- Ensemble Learning Relation With Bias and variance
- Ensemble Learning- The heart of Machine learning
- Bagging — Ensemble meta Algorithm for Reducing variance
- Boosting- Ensemble meta Algorithm for Reducing bias
- Stacking -Ensemble meta Algorithms for improve predictions
- Ensemble learning impact on Deep learning
Boosting- Give the power to weak learners
Unity is the power. Yes, This proverb we had listen in our childhood right. But How its related to boosting, What is boosting? this all the question are raising in your mind.
Boosting, is a provide the strength of weak learner and help machine learning model to prevent under-fitting and over-fitting. It is a process that multiple weak learners(machine learning models) train and combine their output to create strong learner from it. It is used to prevent under-when single machine learning model is not working well and also used to prevent over-fitting when machine learning model is not working well on the validation data-set.
Primary use :
- Prevent Under-fitting when you have less number of training data.
- Prevent Over-fitting when you have enough sample for training data-set still, it is not giving a good result on the validation data-set.
There are many algorithms used by the data science community for classification and regression problems such as Adaboost, XGboost, Gradient Boosting, and so on.
How does it work?
It is beginning with bootstrapping of data, which process we do in bagging as well. then we start different machine learning models training which is known as weak learners. Now main question is what is weak learner right?

Let’s explore the concept of the weak learner.
- The weak learner is not fully accountable for final results, but they have hands in a small part to make final results.
- For making the final decision, these weak classifier are aiding toward the final result. These classifier are known as weak learners.
Example :

Let us say I have to formulate one prediction model for my friend. He is studying in 7th standard. I want to know how he will be getting an A+ Grade in this term exams. For analysis we are going to ask this same question to all his others friends who are studying with him. and they are providing the opinion(Answers) about his as below:
- Friend 1: Andrew will get A+ if he reads for 4 hours a day.
- Friend 2: Andrew will get A+if he watches less YouTube videos.
- Friend 3: He can get A+ if he takes classes regularly.
- Friend 4: He can only succeed if he gets good tuition.
What do you think about this? I think all of the aforementioned answers will be required for good term results, but none of his friends have a complete answer about him. Do you know why? The answer is quite straight forward. they are not maestro; They are not mature enough and every child has its own opinion about Andrew. Still, if you associate(combine)their opinion (Answers). You will get complete answer about this.
Here Andrew’s friends are our weak learners. Everyone has given us partial information, and then we can combine them all and draw the conclusion.
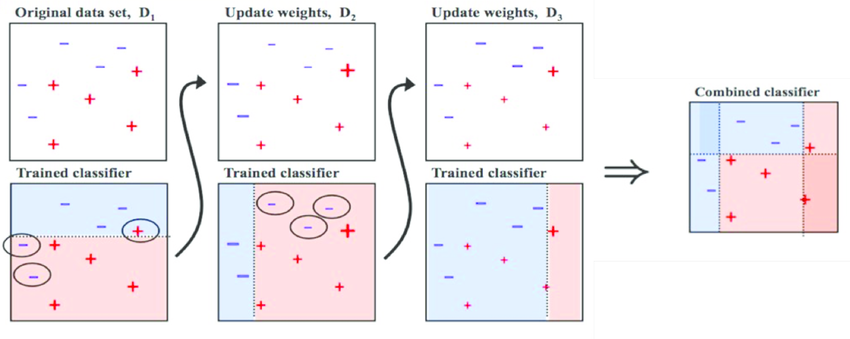
Boosting is supervised learning algorithms which is a kind of frameworks that comprise many weak learners in cascade. It is training model continue sly on training data-set and updates their weights based on the variations between predicted and actual results. The weight updates based on algorithm we used for updates. In the case of boost by majority algorithms, mis-classified learner gets a weight gain and a learner with true classification loses weight. So, the classifier gives less attention to the true classification, which helps in faster convergence of the classifier.

Boosting Process Steps:
- First, generate Random Sample from Training Data-set.
- Now, Train a classifier model 1 for this generated sample data and test the whole training data-set.
- Now, Calculate the error fir each instance prediction. if the instance is classified wrongly, increase the weight for that instance and create another sample.
- Repeat this process until you get high accuracy from the system.
:) Boosting Code Implementation
Now, Let’s move to the implementation section. here we can use sklearn inbuilt iris data set to train a model.
After training the preceding model, we obtain an accuracy of 96.6% on our test data, which shows that our classifier is well trained on the training samples.
Thanks for reading…!!! I hope you enjoy this article…!!!
References :