Combating human trafficking using machine learning: Part 2.

Hey! Welcome to the Part 2 of this series, if you haven’t read the first article you can read it here. As I mentioned in the previous post, in this article I present the features that we seek to extract from our dataset based on previous research literature on this topic. In addition, I show how we can represent our dataset as a graph and motivate its importance.
Let’s begin!
But… what we are looking for?
In first place we have to have an idea of what are the risks factors that law enforcement and NGOs look for in these kind of advertisements. A good baseline and starting point to understand this is given by the UNODC (2020) report on human trafficking and by Giommoni, L. & Lkwu, R. (2021) which provides a list of human trafficking patterns commonly identified in this type of online advertisements.
The indicators proposed in both references seek to find patterns related with the evidence of groups of people under control of others, lack of control in the amount of payment or condom usage by the victims, origin of the victim (country or city), keywords of interest, places where the service is taken (in-call/out-call) and the type of sex offered.
On December 2021 with the help of Fundación Pasos Libres, I was able to have two meetings with two Peru prosecutors that work in the office of human trafficking in that country. With their help, we were able to corroborate these set of human trafficking patterns proposed in both references and also to determine an initial list of features that Chain Breaker seeks to find in these advertisements, which now I present to you:
- There is evidence that groups of people are under the control of others.
- The advertisement uses third or first-person plural pronouns
- Same phone number cited in more that one advertisement with different people
- High degree of similarity between sex workers advertisements
- Sex workers offer risky or violent sexual services
- Multiple people in the same advertisement
- Reference to a website or a spa massage website
- Condom usage (victims might no be able to demand the usage of condom)
- Victims have tattoos or marks (some of this criminal organization use tattoos as a "property" signal)
- Victims faces are hidden (criminal organization hide victims faces so is harder for law enforcement to identify missing people)
2. Receive little or no payment.
- Advertisements promote inexpensive sex services
3. Show signs that their movement is being controlled by others or they have restrictions to move
- Sex workers offering in-call services only
- Sex workers moving to different locations along with other sex workers
- Sex workers moving frequently across several locations
4. There is evidence of possible cases of underage sex workers
- Advertisements use words of phrases of interest that allude to the youthful characteristic of the sex workers.
- Stating a dress size that is typical of a underage women
- Person weight
5. There is evidence of possible cases of human trafficking with populations at risk such as immigrants.
- Countries of interest
- Ethnicities of interest
- Advertisements use words of phrases of interest that allude to the origin or ethnicity of the sex workers.
Depending on the website were the advertisements are extracted it might be more or less troublesome to compute the proposed features (for example, some websites include a specific field for the ethnicity of the person promoted). However, most of the times we will require smart regular expressions patterns or good natural language understanding algorithms for computing them.
In addition, there are some human trafficking patterns that require a way to analyze the images contained in the ads, such as the identification of tattoos or marks, the recognition of hidden faces and sometimes the identification of multiple people promoted in the same advertisement (unless we can determine this using the advertisement text). Unfortunately, nowadays Chain Breaker does not extract image data, since I don’t have a way to store this kind of information.
Additionally, as you might notice, some of these features proposed can be computed using a single instance (for example, we can determine whether an advertisement is written or not in third person only using its text), and others require to usage of the underneath network structure of the data (for example, if we want to determine if the same phone number is being use in several ads).
Exploiting networks
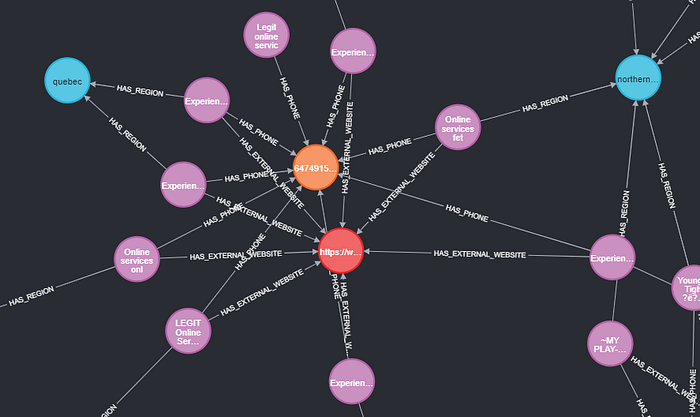
Most of the research on human trafficking in listing websites ignore the underlying graph structure of the data, so they only focus on learning and predicting on individual advertisements. This approach from my point of view is quite troublesome, because law enforcement and NGOs most often seek to find networks of suspicious ads rather than individual instances. In addition, the graph structure of the data has a lot to say about how this criminal organizations operate and thus is easier to identify their activities.
In the first article of this series I mentioned that Chain Breaker stores the information in two databases: MySQL (relational database) and Neo4j (graph database). The former focus on storing relationships between the columns of data tables, while the latter focus on storing relationships between individual data points. Hence, for storing the advertisements extracted from the Canadian listing website I considered the following entities and relationships (Figure 1 shows an example graph of a community of advertisements identified in our data):
# Entities
- Ad
- Phone Number
- Region
- External website (some advertisements include URLs to other sites such as Only Fans, Twitter, Instagram accounts or private websites).# Relationships
- HAS_PHONE (link between Ad and Phone)
- HAS_REGION (link between Ad and Region)
- HAS_EMAIL (link between Ad and Email)
- HAS_EXTERNAL_WEBSITE (link between Ad and External website)
Thus, using the graph information of the data, my approach will focus on the identification on risky communities rather that the identification of risky advertisements. However, this doesn’t mean we have to ignore the information that each individual advertisements can provide (quite the opposite!). In fact, I will use this information to characterize the identified communities in terms of size and aggregate risk based on the individual risk of each one of its advertisements.
What’s next?
In the next post, we dig into the problem of feature engineering and transformation of the Canadian escorts advertisements dataset using the graph structure of the data as well as the individual advertisement data.
