#30DaysOfNLP
NLP-Day 28: How To Approach And Choose A Deep Learning Architecture
A general workflow and some key network architectures

In the last episode, we gently introduced Tensorboard. A tool that allows us to gain insights and a deeper understanding of the various models we implemented.
Considering the fact that this series is slowly approaching the finish line, it’s time to take a step back.
In the following sections, we’re going to take a look at the rearview mirror. Not only highlighting the importance of a general workflow but also revising the key network architectures we already encountered and implemented for ourselves.
So take a seat, don’t go anywhere, and make sure to follow #30DaysOfNLP: How To Approach And Choose A Deep Learning Architecture
A simple tool
Within only a few years, deep learning has achieved tremendous breakthroughs. Especially in the field of machine perception, working with unstructured data like images, videos, sound, or text.
Given enough training data neural networks are capable of extracting nearly the same amount and quality of information from the data as a human could.
However, deep learning is just a tool.
And simply having a tool at our disposal won’t suffice.
In order to solve problems, we need a general workflow. We need to understand the key network architectures, enabling us to choose the right tool for a well-defined task.
A general workflow
It’s not building a model.
The difficult part is everything that lies before designing and training a model. Understanding the problem domain or knowing how to measure success, unfortunately, isn’t something TensorFlow or Keras can help us with.
There simply isn’t a plug-and-play function, thus we need a workflow:
- We need to define the problem and know what data is available. What are we trying to predict? Do we need to collect more or manually label the data?
- How can we reliably measure success on our goal? Perhaps a simple metric like accuracy is sufficient or do we need to define a custom, domain-specific metric?
- We need to prepare the validation process to evaluate our model. This means we should define a training, validation, and test dataset.
- Vectorize the data. We need to shape and preprocess (e.g. normalization) the data into a form that makes our model happy and smile.
- Create a first baseline that beats a common-sense approach. This way we ensure that the network can learn anything at all.
- Refine our architecture gradually. We can tune hyperparameters and add regularization to improve the model’s performance and generalization ability.
- We can deploy our final model in production and keep monitoring and refining it.
Key network architectures
The key architectures can be divided into 4 different categories. Densely connected, convolutional, recurrent networks, and Transformers.
Each architecture has individual needs in terms of input data and makes different assumptions. Data, underlying assumptions, and the architecture must match in order for the model to be able to learn.
Image data, for example, can be processed by 2-dimensional convolutional neural networks, whereas sequential data is rather processed by recurrent neural networks.
Densely connected networks
Contains stacks of dense layers that are meant to process vector data. Dense networks assume no specific structure in the input features. They’re called densely connected because each unit is connected to every other unit. Thus, creating a dense net of connections.
The dense network attempts to map relationships between any two input features and can be mostly used for categorical data or as a final layer for a classification or regression task.
Convolutional neural networks
Convnets look at spatially local patterns by applying the same transformation to different patches of the input tensor. The results are translation invariant, making convnets highly data-efficient and parallelizable.
Convolutional neural networks can be either 1, 2, or 3-dimensional. We can process sequences (e.g. words in a sentence) with a 1-dimensional network. 2-dimensional networks are best suited for image data.
The network consists of several stacks of convolution and max-pooling layers.
Recurrent neural networks
RNNs process sequences one timestep at a time while maintaining a state throughout. For sequential data, they should be preferred over 1-dimensional convnets, especially if the data contains temporal order e.g. time-series, words in a sentence.
We can rely on the Keras API to provide us with several implementations: SimpleRNN, GRU, and LSTM.
Transformers
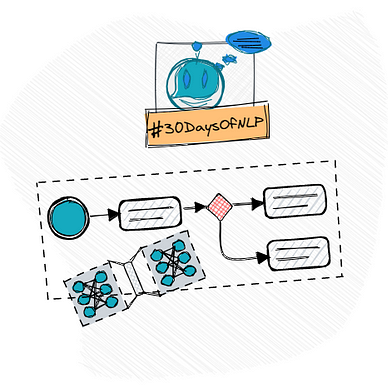
Transformers leverage an attention mechanism to transform each input vector (e.g. a word) into a representation that is aware of the context. We can also use positional encoding to make the Transformer aware of both the global context and the order.
Transformers are more effective than RNNs or 1-dimensional convnets and they especially excel at sequence-to-sequence-related problems.
Transformers are made up of two parts: The TransformerEncoder and the TransformerDecoder. The encoder transforms an input into a representation that is aware of the context and the order, whereas the decoder takes the encoder’s output and a target sequence and tries to predict the next element in the target sequence.
Conclusion
In this article, we took a step back and quickly reviewed the key architectures in deep learning. We also established a general workflow, enabling us to approach a problem in a structured, efficient way.
In the next article, we take a slight detour before finishing the complete series and learn about the basics of regular expressions in Python.
So take a seat, don’t go anywhere, make sure to follow, and never miss a single day of the ongoing series #30DaysOfNLP.


Enjoyed the article? Become a Medium member and continue learning with no limits. I’ll receive a portion of your membership fee if you use the following link, at no extra cost to you.
References / Further Material:
- Francois Chollet: Deep Learning with Python. New York: Manning, 2021.
ML
