Designing gateways for greater good
How to develop gateways that are a joy to use and easy to extend.

Communication. It’s part of our nature. We start practicing it as soon as we are born into this world. We get better and better at it. We enrich our lives through it. We communicate because we aren’t alone.
Software applications aren’t any different. With the rise of the divide-and-conquer architecture (call it SOA, microservices, or any other term you like), applications are no longer alone, hence they need to communicate. They make questions and demand answers. They tell stories. They are part of something bigger than themselves.
Here at Onfido, our applications do not live in isolation. They need to message other Onfido applications, and also third-party applications.
We like to apply the Clean Architecture principles when developing software. That includes the Gateway pattern, that Martin Fowler describes as “an object that encapsulates access to an external system or resource”.
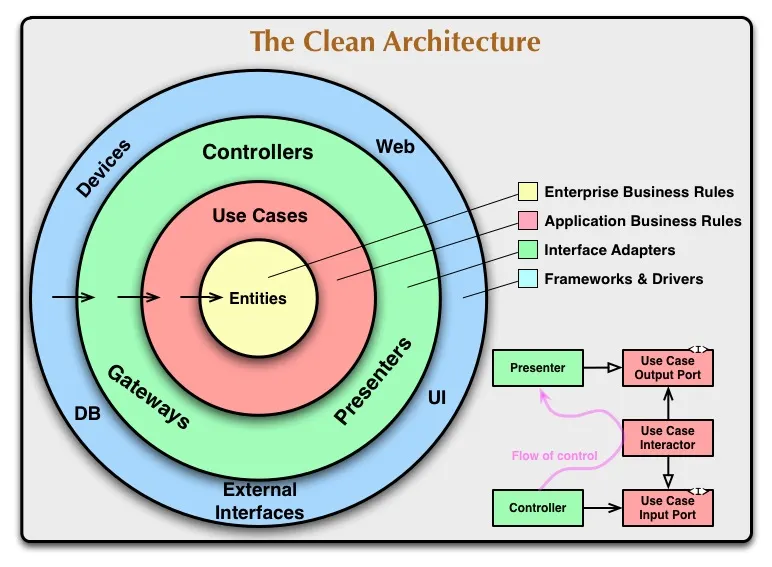
During my career as a software engineer, I can safely say that I handcrafted dozens of gateways. Furthermore, I had to modify a similar number of legacy gateways. In most cases, it wasn’t fun work. Gateways seem to be a magnet for responsibilities that shouldn’t be theirs. It’s common to find logic in them that has nothing to do with the application they want to communicate with, but instead with the application where they live. That is wrong, a clear violation of the single responsibility principle. Allow me to illustrate some common pitfalls with a very simple example.

This is a very simple gateway, representative of some of those I encountered. So, what’s wrong with it?
Starting in line 3, we have an input validation. Not only it would have been wise to move that into its own method, avoiding giving method #call more than one responsibility, but raising an ArgumentError without any description also isn’t very useful to the caller.
On line 14, we see that the value for header PRIORITY depends on whether the current user is a supervisor or not. This logic has nothing to do with the external system! Sure, the external system receives the PRIORITY header, but it’s not the gateway who should figure out what value to put there. This value should be passed to the gateway as part of its input.
On line 17, we see the request being serialized into JSON, therefore method #send_request has more than one responsibility.
All programming best practices obviously apply to gateways, so keep your code SOLID. Furthermore, always keep the following mantra in mind:
A gateway’s only concern is the external system.
From my work in this space, I started to identify a list of steps that gateways seem to share.
- Validate the input
- Build the request object
- Marshal the request object
- Validate the request envelope
- Send the request envelope
- Validate the response envelope
- Unmarshal the response envelope
- Build the response object
Let’s go through them in detail, one-by-one.
1. Validate The Input

Feedback. Good quality feedback. That is the reason why we should validate the input given to a gateway.
We have all been there: passed some data to a gateway, only to be greeted with a NullPointerException or similar. What went wrong? Good luck figuring it out.
I’ve seen lots of gateways featuring dozens of defensive validations, checking all data upfront, only to return an IllegalArgumentException or similar, without any meaningful description of what was wrong. That’s one step above running into a runtime exception, but still very far from where we want to be. We should inform callers about which validations failed, and why they failed. Reading age is invalid is of some help, but reading age is invalid (input: 16); must be greater or equal than 18 is what we should aim for.
Be mindful that if you use hash tables as your gateway’s input, then optional fields can be your doom. Check for the presence of unknown keys and raise an error if that happens. It’s very easy to make a typo on the name of a key (been there, done that), so protect callers against that scenario.
There’s just one good excuse to skip this step: when your request validations (step 3) provide good enough feedback. My experience says that’s rarely the case, as most often than not, the structure of the input differs significantly from the structure of the request. Nevertheless, it’s something to keep in mind when facing tight schedules.
Finally, be careful when writing your validations. You can end up blocking perfectly valid requests from going through if your validations block something that the external system accepts. When in doubt, I tend to go against the robustness principle, loosening my input validations.
Input: the data for the request.
Output: the data for the request or an error.
2. Build The Request Object

Here is where you make the caller’s life easier, by providing them with a great API, while focusing on what the external system consumes.
Naming conventions (e.g., snake case vs. camel case), poorly named fields/actions (e.g., isadt should read “is adult?”, who would tell?), easily derived fields (e.g., driving_license_available must be true if we get a driving license number; based on a true story), data sanitization (e.g., convert telephone numbers to the E164 format). All of these are examples of transformations that should be performed in this step. All of these are examples of good reasons for why the gateway’s input will likely differ significantly from what ends up being sent to the external system.
I want to call special attention to poorly named fields/actions. Propagating those to your gateway is wrong and has no excuse. I’m a bit more forgiving about the names of actions, as their names can be weird but still be part of the context one needs to gain about the external system. With that said, there’s no good reason whatsoever to ask for a field named isadt in your gateway.
Input: the data for the request.
Output: a request object.
3. Marshal The Request Object

JSON, XML, Protocol Buffers, MessagePack, Avro. Well…

As clients of external APIs, we have to comply with their requirements. Life isn’t fair, and whoever promised you that it is, lied. Sorry!
This step is actually quite interesting to me, because its complexity varies a lot with the target serialization format and the programming language that one is using. For example, XML is a bit of PITA to work with in Ruby, but fairly easy to do so in Java (Java was the go-to language back when XML was the cool kid on the block). On the other way around, we probably have JSON as an example, where Ruby absolutely shines.
Regardless of the complexity of the task, this is the step where you encapsulate all the necessary logic to do it. Keep in mind that a request envelope also features headers, it’s not just the payload. If, for example, you have to Base64 encode the value of a header, that must also be performed in this step.
Input: a request object.
Output: a request envelope.
4. Validate The Request Envelope

Do you have a schema for the external system’s API? XSD/WSDL, GraphQL, JSON-Schema (they aren’t all equivalent, but you got my point)? If so, use it here.
Networks are slow, computers are fast. Checking if a request is well-formed is essentially free when compared to the cost of sending it over the wire, only to later find out that it isn’t valid. Furthermore, as I wrote regarding step 1, sometimes the feedback provided by this validation is good enough to be returned to the caller.
Input: a request envelope.
Output: a request envelope or an error.
5. Send The Request Envelope

All things about the transport go here. Authentication? Here. Timeouts? Here. Content-type negotiation? Here. Retries? Here.
The input of this step must be whatever you need to send the request to the external system. HTTP? A URL, verb, headers and a body. FTP? Paths, data and metadata. AMQP? A routing key, headers and a body. Transports have unavoidable specificities, so my advice is for you to not try to create abstractions here. I’ve seen that mistake on a multitude of projects.
Most APIs make use of the transport’s capabilities to negotiate things that aren’t directly related with the request itself, authentication being the usual example. With that said, the world has its fair share of mysteries and bad APIs (being the latter a subset of the former). For example, I’ve seen several APIs that require credentials to go in the payload. In such a scenario, one may ask: is it in this step that should we add credentials to the request payload? To me the answer is no, and I’ll add the credentials to the request payload in step 2. My rationale for these kinds of decisions always ends with me asking myself the following question: if the transport changes, will I need to change this? If the answer is yes, the logic goes in this step. If the answer is either no or maybe, I then write-down a rationale for whatever my decision is.
Input: a request envelope.
Output: a response envelope.
6. Validate The Response Envelope
Just like in step 4, if you have a schema for the response, you may want to use it here. All things break, we all make mistakes, so it’s better to know right away that a response isn’t conforming, than to have to find out later while debugging an obscure bug.
Input: a request envelope.
Output: a request envelope or an error.
7. Unmarshal The Response Envelope
Analogous to step 3.
Input: a request envelope.
Output: the data for the response object.
8. Build The Response Object
We are almost there folks…
Does the response indicate success? If not, we must raise an error, containing as much information as possible. I’ve seen a lot of gateways that leave the responsibility of deciding what is a failure to the caller. That’s wrong.
In case of success, all this effort would be in vain if we now return something with a crappy API to the caller. Focus on programmer happiness, aim for joy. I tend to avoid returning hash tables for the same reason that I pointed in step 1: it’s easy to make typos. Rename fields where appropriate, just like in step 2.
Input: the data for the response object.
Output: a response object.
Wrapping up, evaluate your design with the three following questions:
- As-is, can I make a library out of my gateway? (i.e., it doesn’t contain any code specific to the application where it currently lives)
- If the external system’s API is extended, how hard is to add support for it in my gateway?
- Is my gateway a joy to use?
If the answer to question 3 is anything other than “yes”, then go back to the drawing board.
