Medical Imaging Downloader for CornerstoneJS and Orthanc
An advanced medical application solution comprises several routines and advanced image processing, as well as reading complexity. This article discloses a possible solution for a Medical Imaging Downloader within the use of both CornerstoneJS and Orthanc [1, 2] technologies.

Introduction
In the last article named “Using CornerstoneJS and Orthanc to Support Deep Learning Projects”, we explain the importance of tools such as CornerstoneJS [3, 4] and Orthanc [1, 2] to support our Artificial Intelligence (AI) algorithms. Briefly, these tools are of chief importance to our projects, allowing us to empower our clinicians to provide us with datasets by interacting with those tools [8]. In the end, the datasets will feed our AI models, providing us with the autonomous outputs that clinicians need [5, 6, 7]. The use of these tools will allow the application of Machine Learning (ML) to the Medical Imaging (MI) field. This is addressed in our “Applying New Paradigms in Human-Computer Interaction to Health Informatics” article. The following description will be a technical, yet comprehensive piece of information for any kind of reader.

Solution
A cloud-based solution like the presented architecture is showing a simplified way to retrieve and download sets of medical images. In our solution, a cloud-based platform to the proposed architecture was implemented and deployed as a Demo to serve the purpose of this article. The source code is presented on our GitHub page. Our source code is licensed over the MIT License. For more details and information, follow the wiki page of the repository.
Instructions
From our repository, first of all, you need to clone our source code. Then you need to follow the seral stages of our instructions to achieve both article and repository goals. The instructions are simple to follow, however, if you have any question feel free to ask in the comment section of this article or open a new GitHub issue so we can help you with that.
Clone
To clone the hereby repository, follow the guidelines below. It is easy as that.
1.1. Please clone the repository by typing the command:
git clone https://github.com/opprDev/medical-image-downloader.git1.2. Get inside of the repository directory:
cd medical-image-downloader/1.3. To install and run of the source code, follow the next steps;
Install
The installation guidelines are as follows. Please, be sure that you follow them correctly.
2.1. Run the following command to install the library set using pip:
pip3 install -r requirements.txt2.2. Follow the next step;
Run
The running guidelines are as follows. Please, be sure that you follow it correctly.
3.1. Run the sample using the following command:
python3 src/core/main.py3.2. Enjoy our source code!
Dependencies
Our downloader was made in Python, which is easy to learn while being the go-to language for fast prototyping. For this job, we mainly used pandas, json and urllib libraries. We used pandas to manipulate our data processing and analysis. To read the several JSON files that manage CornerstoneJS the connection with Orthanc, we used the json library. Finally, to fetch the connection between URLs (Uniform Resource Locators), we used the urllib library.
Source Code
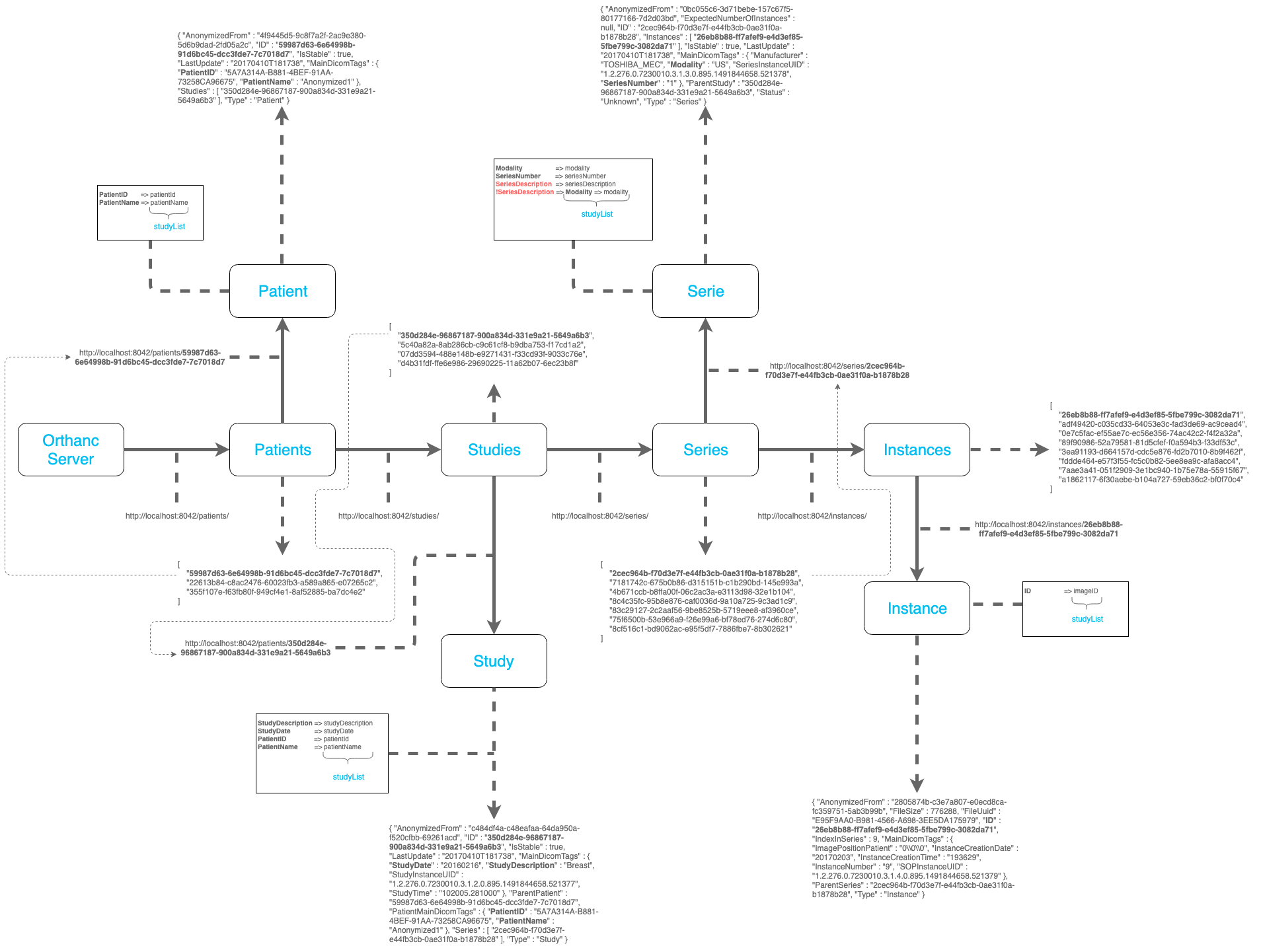
As we stated in our previous article, on a client-server communication, the client-side of the CornerstoneJS searches for studies (cases) or series (digital slides) resources (see Figure) while providing query parameters to filter DICOM objects based on given attribute values. To read the set of values, the urllib library fetches the URL, so that we can interpret the medical image structures. The schemas are in the JSON format. Therefore, we used the json library to interpret the schemes.
Folder Structure
Our project will have the following folders:
src/
├── core/
├── methods/
├── notebooks/
├── tests/
└── variables/The full source code is inside the src/ folder. The folder has several other sub-folders organizing our code in sections. The first section is the core/ sub-folder where we have the main.py file. The main.py file is the principal file, working as coordinator. The methods/ sub-folder is where we have the set of methods to download the medical images, or to support the process. As we are using Jupyter Notebook, we created the notebooks/ sub-folder to place them in. Each project must have its own set of tests so that we can guarantee the validity of our source code. In the tests/ sub-folder, we placed our tests for the project and in the variables/ sub-folder, we have our used variables and constants.
Methods
Inside the src/ folder and inside the methods/ sub-folder, we have the accessing.py file. This file has the main method to download the medical images that are shown in the CornerstoneJS viewer and stored on an Orthanc server.
But first, let us explain how to achieve each functional goal. The first part is to request the URL by using the urllib library.
dataStudyList = urllib.request.urlopen(mainServer).read()Secondly, we need to interpret the data (see Figure) coming from the request. For that, we used the json library which will read the answer coming from the Orthanc server, loading it to a JavaScript object.
outputStudyList = json.loads(dataStudyList)Now, we are on the way to trigger the schemas of the medical images. By looking at our Demo and Prototype Cornerstone examples, there are two important endpoints: (1) the studyList.json file; and (2) the studies/ folder. The studyList.json file is where we have the patients’ list. While the studies/ folder is where we have the details for each patient.
As an example of the studyList.json file, we have the following:
{
"studyList": [
{
"patientName": "MR/BRAIN/GRASE/1024",
"patientId": "7",
"internalId": "8f14e4",
"studyDate": "19950330",
"modality": "BRAIN",
"studyDescription": "BRAIN",
"numImages": 1,
"studyId": "7"
},
{
"patientName": "Anonymized",
"patientId": "0",
"internalId": "cfcd20",
"studyDate": "20070101",
"modality": "Knee (R)",
"studyDescription": "Knee (R)",
"numImages": 71,
"studyId": "0"
},
{
"patientName": "Case1",
"patientId": "Case1",
"internalId": "a294f5",
"studyDate": "20080408",
"modality": "BREAST IMAGING TOMOSYNTHESIS",
"studyDescription": "BREAST IMAGING TOMOSYNTHESIS",
"numImages": 6,
"studyId": "Case1"
}
]
}As an example of the studies/ folder and more specifically of a patient case from Case1.json file, we have the following:
{
"patientName": "Case1",
"patientId": "Case1",
"internalId": "a294f5",
"studyDate": "20080408",
"modality": "BREAST IMAGING TOMOSYNTHESIS",
"studyDescription": "BREAST IMAGING TOMOSYNTHESIS",
"numImages": 1,
"studyId": "dec7949e-a99467d6-305d0d64-424bfd75-8a1579ab",
"seriesList": [
{
"seriesDescription": "MG",
"seriesNumber": "72100000",
"instanceList": [
{
"instanceNumber": 29,
"imageId": "dd03786b-6cc667d1-a65fa0e9-34101126-6f82ca59/file"
}
]
},
{
"seriesDescription": "MG",
"seriesNumber": "72100000",
"instanceList": [
{
"instanceNumber": 15,
"imageId": "ae407aac-af2c66a3-5801a6c9-ffff4ae9-06496953/file"
}
]
},
{
"seriesDescription": "MG",
"seriesNumber": "73100000",
"instanceList": [
{
"instanceNumber": 16,
"imageId": "062ce5a8-0d015abb-73f65ae3-f95d55e8-9cbdfcb6/file"
}
]
},
{
"seriesDescription": "MG",
"seriesNumber": "73100000",
"instanceList": [
{
"instanceNumber": 30,
"imageId": "6f6f0dc7-db7a6fa0-f3e46a80-8bcda478-194bcf11/file"
}
]
},
{
"seriesDescription": "MG",
"seriesNumber": "73200000",
"instanceList": [
{
"instanceNumber": 30,
"imageId": "e0551a96-ccf93766-a2d57ddf-361c8462-46b8b196/file"
}
]
},
{
"seriesDescription": "MG",
"seriesNumber": "73200000",
"instanceList": [
{
"instanceNumber": 16,
"imageId": "88653231-d6fba822-1af594af-e6f5b30d-dd1ab7f2/file"
}
]
}
]
}To better understand the schema structure it is highly important to read our last article, as mentioned previously. Unless you are already familiar with this PACS structure. To describe the above structures, in short, a seriesList array (see Figure) has a list of series. Each one of the series has a seriesDescription, a seriesNumber and a list of instanceList as arrays with several instances of images.
Now, for each patient, we need to read the respective information of the object. For that, we just go through the studyList of the studyList.json file and extract the patientId to retrieve patient study on the studies/ folder. In our example, we use the “patientName”: “Case1” to retrieve the Case1.json file.
for ptnt in range(len(outputStudyList['studyList'])):
patientIdToCompare = outputStudyList['studyList'][ptnt]['patientId']
pntFileOnServer = lnk004 + patientIdToCompare + ext003
dataStudies = urllib.request.urlopen(pntFileOnServer).read()
outputStudies = json.loads(dataStudies)From there, we can read the information inside the Case1.json file, also as a JavaScript object. Now, we want to parse the seriesList, passing through the instanceList to get the imageId. From the imageId, we can retrieve and download each image.
for study in range(len(outputStudies)):
seriesList = outputStudies['seriesList']
for serie in range(len(seriesList)):
seriesNumber = seriesList[serie]['seriesNumber']
instanceList = seriesList[serie]['instanceList']
for instance in range(len(instanceList)):
image_counter = image_counter + 1
imageId = instanceList[instance]['imageId']
dcmUrl = dicomServer + imageId
dcmFileName = folderToSave + str(image_counter) + ext002
urllib.request.urlretrieve(dcmUrl, dcmFileName)Final method source code of downloading the medical images:
def dwnldMainServImgStorOnDicomServ(folderToSave, mainServer, dicomServer):
'''
Downloading all medical images from your main server
that are stored on a DICOM server.
'''
image_counter = 10000000
dataStudyList = urllib.request.urlopen(mainServer).read()
outputStudyList = json.loads(dataStudyList)
for ptnt in range(len(outputStudyList['studyList'])):
print(c010)
patientIdToCompare = outputStudyList['studyList'][ptnt]['patientId']
pntFileOnServer = lnk004 + patientIdToCompare + ext003
dataStudies = urllib.request.urlopen(pntFileOnServer).read()
outputStudies = json.loads(dataStudies)
print(outputStudies)
for study in range(len(outputStudies)):
seriesList = outputStudies['seriesList']
for serie in range(len(seriesList)):
seriesNumber = seriesList[serie]['seriesNumber']
instanceList = seriesList[serie]['instanceList']
for instance in range(len(instanceList)):
image_counter = image_counter + 1
imageId = instanceList[instance]['imageId']
print(msg004, imageId, msg005, seriesNumber)
dcmUrl = dicomServer + imageId
dcmFileName = folderToSave + str(image_counter) + ext002
urllib.request.urlretrieve(dcmUrl, dcmFileName)
print(c010)Conclusions
In this article, we propose a solution to retrieve and download sets of medical images that are shown on a CornerstoneJS viewer and stored on an Orthanc server. We provide a clear and simple source code well described and documented in this article, as well as on the wiki page of the repository. Furthermore, we show how this solution enables the application of ML methods to the MI field and how to promote such kind of research projects.
Acknowledgments
This post is supported by the case studies of MIMBCD-UI, MIDA, and BreastScreening projects at IST from ULisboa. The three projects are strongly sponsored by FCT, a Portuguese public agency that promotes science, technology, and innovation, in all scientific domains. The BreastScreening project is an ARC Discovery Project (DP140102794) in collaboration with IST, Adelaide, and UQueensland. The genesis of this post was a research work between ISR-Lisboa and ITI, both associated laboratories of LARSyS. From these institutions, I would like to convey a special thanks to Professor Jacinto C. Nascimento and Professor Nuno Nunes for advising me during my research work. Last but not least, I would like to thank several important people of this noble organization called oppr. A special thanks to Gustavo Passos de Gouveia, Bruno Oliveira, João Campos, Carlota Galvão de Melo and João Cruz for reviewing this article giving me great inputs. Last but not least, a special thanks to Chris Hafey, the propelling person of CornerstoneJS, who also developed the cornerstoneDemo. Not forgetting the three supporters of the CornerstoneJS library, Aloïs Dreyfus, Danny Brown, and Erik Ziegler. We also would like to give a special thanks to Erik Ziegler who supports several issues during this path. In the end, a great thank to all the Orthanc project team, but especially to Sébastien Jodogne.
Supporters
Our organization is a non-profit organization. However, we have many expenses across our activity. From infrastructure to service expenses, we need some money, as well as help, to support our team and projects. For the expenses, we created several channels that will mitigate this problem. First of all, you can support us by being one of our Patreons. Second, you can support us on the Open Collective page. Thirdly, you can buy one coffee (or more) for us. Fourth, you can also support us on our Liberapay page. Last but not least, you can directly support us on PayPal. On the other hand, we also need help in the development of our projects. Therefore, if you have the knowledge we welcome you to support our projects (e.g., GitHub). Just follow our channels and repositories.
Social
We are on the top social media networks. The links are as follows. Also, you can chat with us. Just follow us to know about our work and news.
List of our social media networks and chats channels:
References
[1] Jodogne, S., Bernard, C., Devillers, M., Lenaerts, E. and Coucke, P., 2013, April. Orthanc-A lightweight, restful DICOM server for healthcare and medical research. In 2013 IEEE 10th International Symposium on Biomedical Imaging (pp. 190–193). IEEE.
[2] Jodogne, S., 2018. The Orthanc Ecosystem for Medical Imaging. Journal of digital imaging, 31(3), pp.341–352.
[3] Hostetter, J., Khanna, N. and Mandell, J.C., 2018. Integration of a zero-footprint cloud-based picture archiving and communication system with customizable forms for radiology research and education. Academic Radiology, 25(6), pp.811–818.
[4] Sedghi, A., Hamidi, S., Mehrtash, A., Ziegler, E., Tempany, C., Pieper, S., Kapur, T. and Mousavi, P., 2019, March. Tesseract-medical imaging: an open-source browser-based platform for artificial intelligence deployment in medical imaging. In Medical Imaging 2019: Image-Guided Procedures, Robotic Interventions, and Modeling (Vol. 10951, p. 109511R). International Society for Optics and Photonics.
[5] Calisto, F.M., Lencastre, H., Nunes, N.J. and Nascimento, J.C., Medical Imaging Diagnosis Assistant: AI-Assisted Radiomics Framework User Validation.
[6] Calisto, F.M., Lencastre, H., Nunes, N.J. and Nascimento, J.C., Medical Imaging Diagnosis Assistant: AI-Assisted Radiomics Framework User Validation.
[7] Calisto, F.M., Miraldo, P., Nunes, N. and Nascimento, J.C., BreastScreening: A Multimodality Diagnostic Assistant.
[8] Calisto, F.M., Ferreira, A., Nascimento, J.C. and Gonçalves, D., 2017, October. Towards Touch-Based Medical Image Diagnosis Annotation. In Proceedings of the 2017 ACM International Conference on Interactive Surfaces and Spaces (pp. 390–395). ACM.

{kind=link}