Parsing poor-context documents with AI, a major challenge for the freight industry

TL;DR: Freight is generating several legal documents for every shipment. They are both mandatory and full of useful information. Being able to retrieve automatically this data would make the experience of freight smoother and more insightful for our customers. Enabling to handle customs, doing analysis on transport cost per product or giving a forecast of stock are jobs that we could do for our customers by parsing these legal documents.
We have studied the general framework needed to parse such poor-context documents using machine learning. This framework focuses on three aspects of this challenge : recognizing the text from the image, understanding the layout and getting the meaning of each word.
Following this long study, we are very proud and happy at Ovrsea to deliver our first feature with the automated reading of commercial invoices for the stock vision!
The high interest of parsing documents
In the freight industry, a bunch of documents are often generated alongside a transport. You will deal with a Bill of Lading or an Air waybill, customs, packing lists, commercial invoices … the list is quite long. And all these documents will allow your container or goods to check every requirement to arrive safely at your warehouse.
They are both necessary and full of useful data such that being able to retrieve information automatically would make the experience of freight smoother and more impacting for our customers. We could think of many use cases that would benefit them:
- Provide a stock vision to the buyer by reading the packing list
- Simplify the customs by reading the HS codes of every product
- Give an analysis of shipment price cost per item by reading the commercial invoices
According to the feedback collected by our Product team from our customers, automatically retrieving these pieces of information from freight documents is an amazing feature!

But if it is mandatory data, when the freight is going to be fully digital we could get rid of all these documents, right? Well, it is not that easy. Or at least not going to happen anytime soon.
As described in most of the articles we have read about this topic, the entire freight eco-system is still very late in digitalisation and while many actors try to catch up the race, we can’t really expect the market to stop using pdf document soon [1] [2].
The challenges of extracting information on poor-context documents
Notion of poor-context document
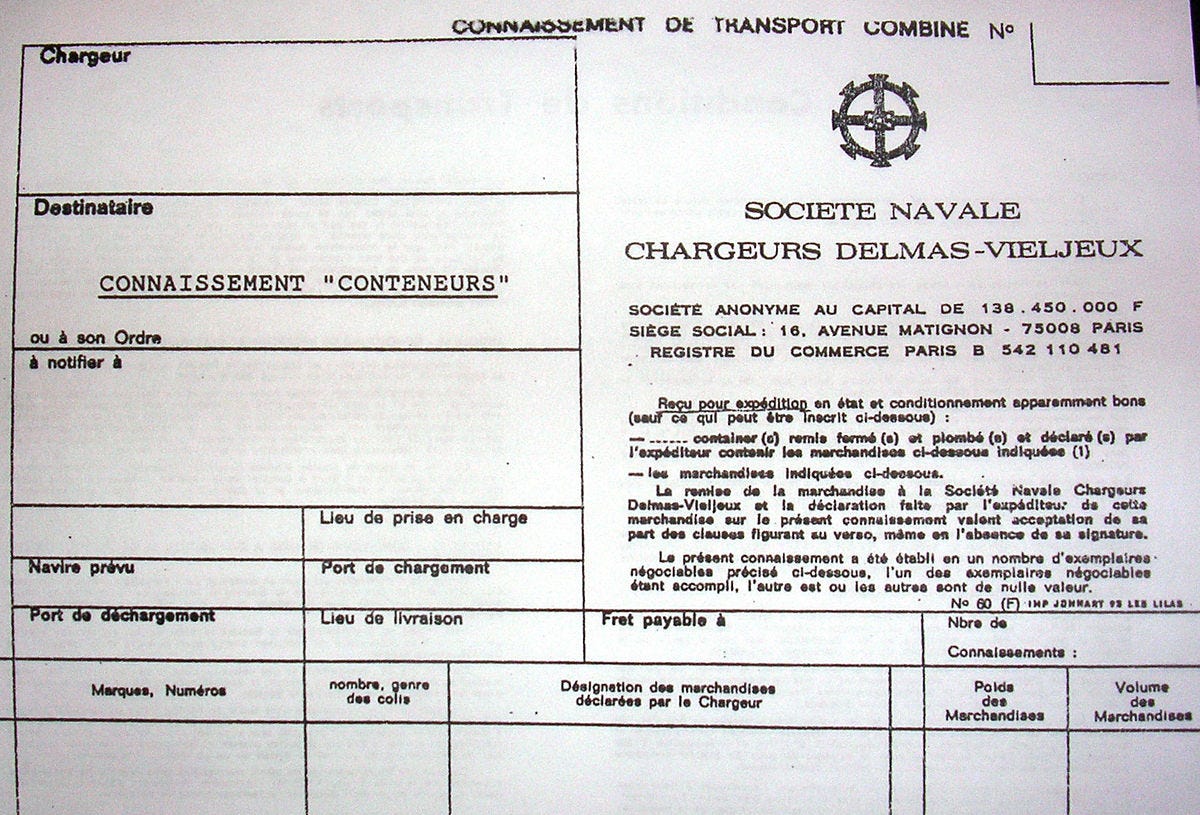
But what exactly are these documents ? In fact the freight documents are pdf often stored as images. They are not written in full sentences and their layout is often built around approximate tables or forms that contain the minimal viable information. Thus each word is not surrounded by others that would explain what it actually means contrary to a standard sentence. And tables may be very complex with multiple entries as shown in the Image 2. This is why we call them poor-context documents.
So, how can we extract information across diverse documents with various templates and structure these information in a database to enable our customers to use them?
Let’s say we are able to transform the image into a text — we will talk later about it. Since most of the data we want to retrieve are in a table, we might think this should be a child’s play. Well … not exactly. Due to the way the machine learning technologies have developed, this is in fact much more complicated to retrieve information from several tables than from text with semantic. Let’s try to popularise a bit!
Artificial intelligence on text
The Natural Language Processing (NLP) is one field of AI that aims at understanding the semantic behind the text. Two majors breakthroughs have been done in this field by Google and OpenAI (supported by Microsoft) respectively with the BERT transformer and the GPT in the last 10 years [3] [4]. By relying on massive quantity of data, they have been building models that are -kind of- understanding our languages.
I will not dig deeper into this topic, but if you want to take a look, you can try OpenAI API or even … simply write a query on google search ! This is how Google is able to understand when you are typing your search query as it was a question you would ask a friend.

Artificial intelligence on poor-context documents
In our case, we can’t rely directly on such technologies. Indeed, poor-context documents don’t contain sentences that would rely on semantic syntax. The information is much more diluted across three main factors:
- The text itself as a word without context
- The geographical position of the text in the document
- Lines and geometry that define layout
Now that we have seen why parsing document is a challenge, let’s explain how we tried to solve it!
AI tools to deal with poor-context document
As this problem is a complex one, we need to rely on multiple technologies. As explained in our previous article, our goal at Ovrsea’s Data team is to define the right level of R&D between home-made and off-the-shelf technologies. While working on customs solutions, we have also been exchanging with different start-ups to define our own solution.
We are going to present you the general tools to tackle such a challenge. Notice that they are many ways to solve it and this framework may not cover every one of them!
1. Recognize the text with Optical Character Recognition (OCR)
The first brick of every possible solution should be OCR. Indeed, the input here is an image. Depending on the type of pdf, some can be read directly as xml file, but most of them will only be uploaded as images like png or jpg that should then be transformed into actual text. OCR that stands for Optical Character Recognition is a technology that is able to detect and automatically read text from an image. Many OCR solutions exist on the market, either free or not such as Amazon Textract or Tesseract (sponsored by Google). From the OCR benchmark we have been doing, they are still very much all focusing on latin languages.
By analyzing the document and the characters, they are able to reconstitute the text and give its absolute position on the document. The output of OCR is often a bounding box that embeds the text of the document (see bounding box in Image 4). But the OCR needs training to be able to recognize coherent groups of words as one token. For example it should not mix the title with the first sentence of the text, and be able to create two bounding boxes.

However, even when you have the text and its position, it doesn’t yet help you to fully understand it. For that, you need to get what is the underlying structure.
2. Understanding the layout with Deep learning and statistics
In poor-context document, the understanding of the layout is one of the key information we need to get. Here we will be defining the layout analysis as any information that helps us understand the structure of the document and the relationship between tokens of word recognized but the OCR.
The general desired output for layout understanding is often to be able to label the box surrounding each token of text to define its possible type — see Image 4. Is it the answer to a question? A general information over the document (date, reference number etc)? A table of interest?
If the document doesn’t contain too much diverse templates, then a simple statistics analysis with a basic machine learning algorithm such as random forest could help us get the information we need. For example by looking at specific words in a pre-defined position of the document, we might be able to retrieve a specific information such as a due date for instance.
However, in many situation, this is not sufficient as documents’ structures are very complex and diverse. A statistical analysis may not be able to understand it enough. This is where deep learning comes into play. Over the last two years, a lot of huge breakthroughs have been done in this field. This topic — known as Document layout Analysis — is still way behind traditional NLP, but by relying on the same mechanism, deep learning algorithms are almost able to understand the document structure.
The foundations of deep-learning document layout analysis : Transformers and attention
These deep learning algorithms often rely on the transformer architecture that has been created with the release of the algorithm BERT in 2017 by Google. This architecture is trained to encode and decode information (it can be images, texts, …), by using “attention” which is a mechanism that enables your algorithm to understand the link between your inputs. We will not dig deeper into this technology since it is not the purpose of this article, but if you are interested, I advise you to read “Attention is all you need” [5].
The original transformer architecture has been adapted since 2017 and is very much used for layout understanding. To give you some examples :
- Microsoft is currently working on the algorithm LayoutLM that is both using OCR and computer vision for images to be able to understand them [6] [7] [8]. Just to give you an overview, a scheme of its architecture is shown below.
- Another algorithm developed by Microsoft is DiT (Document image Transformer) that is based on Google Bert and that is relying much more on computer vision than on OCR [9] [10].

These technologies are state of the art as both paper of LayoutLM v3 and DiT have been released few weeks ago. While being very powerful, these algorithms still need to be tuned to our own documents and challenges. Indeed, as you can see on the Image 4 above, DiT has been trained to only classify visual token between four labels: “text”, “figure”, “table” and “title”. Similarly LayoutLM v2 has been trained to recognize the labels: “Question/Answer” as well as “title” or “other”. Thus to apply them to certain freight documents you would need to define the information you want to recover and label them in the boxes to fine-tune your transformer model.
3. Grasping the meaning of words with embedding
Once we have the text and labels for tokens, we might still need to understand what is the meaning of each token of word. Depending on the accuracy that you require from your labels, this can be an information to choose between two selected tokens of word.
Due to the poor-context issue, we can’t rely on direct NLP outstanding technics, and this time we need to step back and consider a less state-of-the-art technic but still very efficient: word embedding. The idea behind it is simple: encode any word into a mathematical vector space, such that the difference of two vectors (typically cosine similarity) is defining the relationship between them [11]. This technic will, for example, help us find synonyms, which is useful when we intend to find a same information but present under another name.
To obtain such relationships between words, we need to train them on semantic sentences that should match our own topic of interest. However, once the training is done, we can apply word embedding even if we only have words and not sentence. Many python library exist to do this task such as Spacy, or NLTK with WordNet dictionary [12] [13].
Our first use case: the reading of commercial invoices!
Following this long study, we are very proud and happy to deliver our first feature with the reading of commercial invoices for stock vision. We have been able to develop a feature that is able to detect most of the products and their characteristics from a commercial invoice to have a better stock vision! As this is an R&D topic, we will work on improving this first Beta feature. By testing new algorithms and architectures, we might crack even more the topic of poor-context document parsing !
If you are a customer interested in this new technology, please do reach out to our product team to know more about this feature! And if you are a tech lover, who is craving for Data and want to be part of this terrific journey, apply to our amazing team! We are hiring!
#DataEngineer #DataAnalyst
Bibliography
- Manaadiar, H. Pitfalls of digitalisation in shipping and freight. https://www.shippingandfreightresource.com/pitfalls-of-digitalisation-in-shipping-and-freight/.
- The digitalization of the freight forwarding industry: essential for its survival. https://piernext.portdebarcelona.cat/en/logistics/the-digitalization-of-the-freight-forwarding-industry-essential-for-its-survival/.
- OpenAI API. https://openai.com/api/.
- Lutkevich, B. What is BERT (Language Model) and How Does It Work? https://www.techtarget.com/searchenterpriseai/definition/BERT-language-model (2020).
- Vaswani, A. et al. Attention Is All You Need. (2017).
- Xu, Y. et al. LayoutLMv2: Multi-modal Pre-training for Visually-rich Document Understanding.
- Huang, Y., Lv, T., Cui, L., Lu, Y. & Wei, F. LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking.
- LayoutLMV2. https://huggingface.co/docs/transformers/main/en/model_doc/layoutlmv2#transformers.LayoutLMv2Model.
- Li, J. et al. Work in Progress DIT: Self-supervised Pre-training for Document Image Transformer. (2022).
- Hugging Face. DiT documentation. https://huggingface.co/docs/transformers/master/en/model_doc/dit (2022).
- Bujokas, E. Creating Word Embeddings: Coding the Word2Vec Algorithm in Python using Deep Learning | by Eligijus Bujokas | Towards Data Science. Towards Data Science https://towardsdatascience.com/creating-word-embeddings-coding-the-word2vec-algorithm-in-python-using-deep-learning-b337d0ba17a8 (2020).
- Gubur, K. NLTK and Python WordNet: Find Synonyms and Antonyms with Python — Holistic SEO. https://www.holisticseo.digital/python-seo/nltk/wordnet (2021).
- Revert, F. An Overview of Topics Extraction in Python with Latent Dirichlet Allocation — KDnuggets. https://www.kdnuggets.com/2019/09/overview-topics-extraction-python-latent-dirichlet-allocation.html (2018).

{kind=link}