Resource optimization in Node.js
In this article, we explore the possibilities of maximizing Node.js’s capabilities and understand the benefits of resource sharing, disproving the assumption that every request must be isolated. Join us as we uncover the full potential of Node.js and discover how resource optimization can enhance the performance and efficiency of your applications.
We all know Node.js is fast, single-threaded and non-blocking, but are we taking the most out of it? In the majority of cases the answer is simply, “No.”
Because its single-threaded, we tend to forget that we still have several lines of execution that resemble… threads! So we can improve the way our code executes, making the resource obtained by a thread available to others, thus reducing the load on these precious resources.
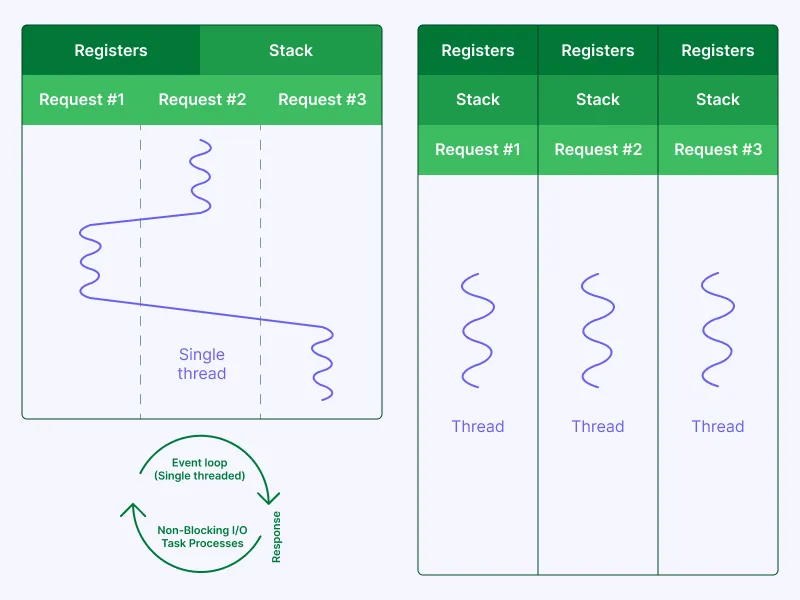
Let’s imagine we have an endpoint that calls an API, and that endpoint is called concurrently by many customers. So, when a request arrives needing data and calls that API, then a second request arrives also calling the exact same API the first request is already waiting for, why not share it?
Developers often make the incorrect assumption that when working on Node.js servers, each request must be completely isolated from other requests and every single one needs to do its calls and database requests while isolated from the rest.
This is simply not true.
A request can share the same resource if some conditions are met:
- it’s not customer-specific data or we are not making use of a customer authentication token (we should never mix these requests due to accountability, meaning we need to know who made the request)
- the request data is exactly the same
- we make sure that errors, if they happen, don’t leak information to other customers ( causing GDPR issues), which can be avoided by logging the original error and throwing a generic one to all awaiting promises
- finally, it needs to be a frequently made call, preferably one that takes some time to execute, so resource sharing is proven to be beneficial to multiple executor requests — otherwise the benefit will be almost unnoticeable.
Regarding how requests flow, check out the graph below where each row represents a request and each colored bar represents the time spent using a resource. Because each request is fully independent, we’re not sharing resources, which is usually critical when we have applications making thousands of concurrent requests and cannot be easily solved.
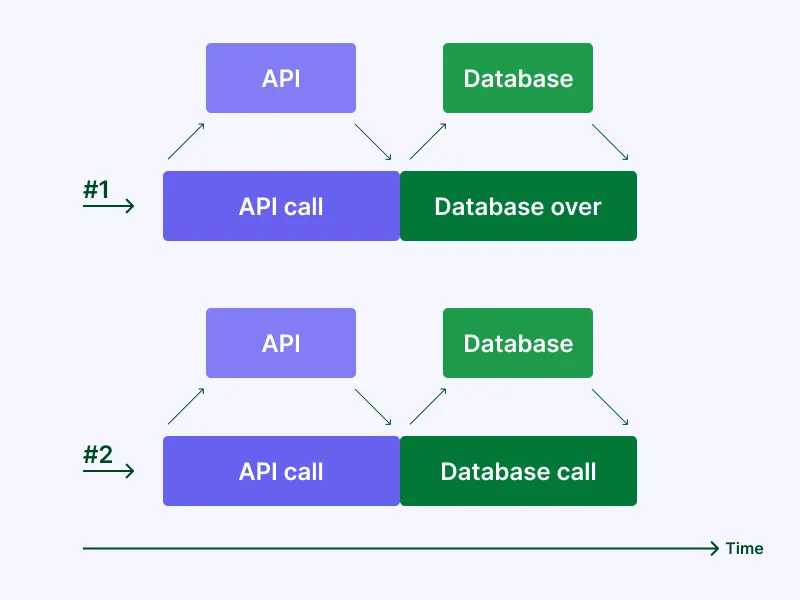
When we have very specialized services we could also have several requests asking for the exact same resource — an opportunity to make our application better.
Notice below that some of the calls were replaced by Promises. This happened because the same resource was already being fetched, so we decided to share it instead of calling it again, which reduces the load on those resources.
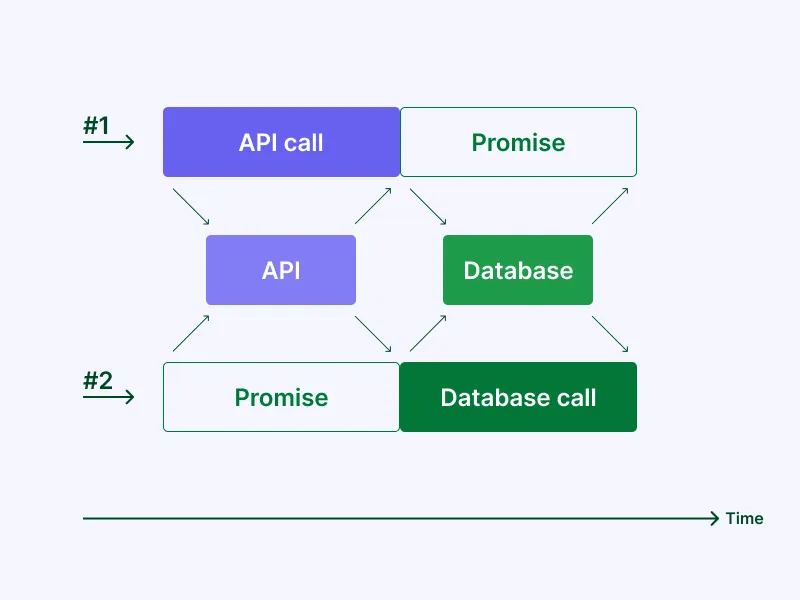
In languages like Java, developers use synchronized methods to control access to resources. The benefit with Node.js is that there isn’t the need to make system calls for mutexes or semaphores, which are expensive, due to Node.js’s architecture, which makes it even faster.
Of course, in this example I’m talking about a single instance of a service. Doing this over multiple instances of a service is a little trickier, although the concept is similar (I’m working on more advanced distributed patterns).
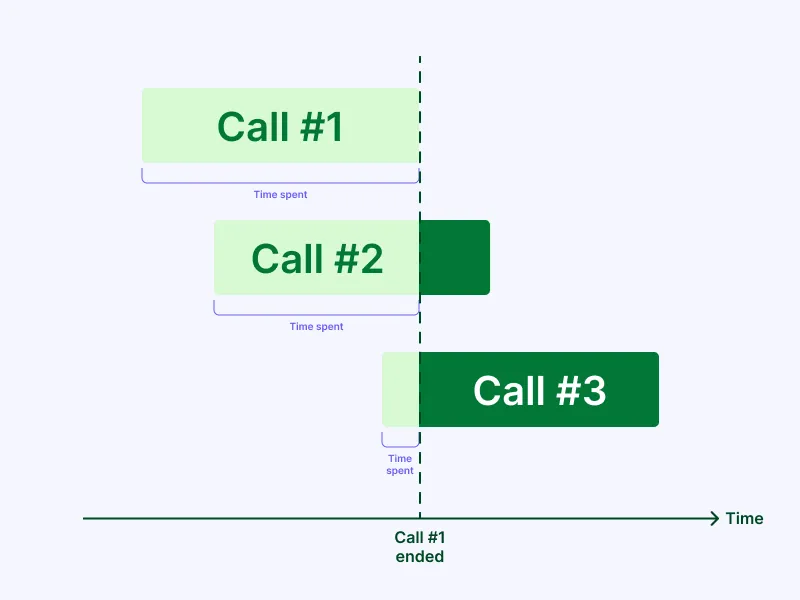
The interesting thing about this topic is that it’s not only about saving resources> In reality, it makes your application even faster. “How?” you may ask? Well, let’s assume an operation takes 200ms, and any subsequent requests for that same operation reuses it. That means that any incoming request during those 200ms will reuse that outcome, even if it starts 1ms after the beginning of the initial operation or 200ms after, so on average reused operations take 200ms/2=100ms.
By reusing ongoing operations, you will save, on average, half of the time of the original operation and that is an awesome gain.
Unless you are running within the scope of a transaction-alike operation, or making an API call that makes use of a specific user token (in which case, you shouldn’t share resulting data), you can share data from a good proportion of your common operations without any concerns.
How can we achieve this? Promises are the answer!!!
When we detect that a call for a given resource has already started, instead of starting another call for it, we just return a Promise for its result (or failure). This way, any concurrent request for APIs, database queries or whatever you need to call can be avoided, reducing the load on resources.
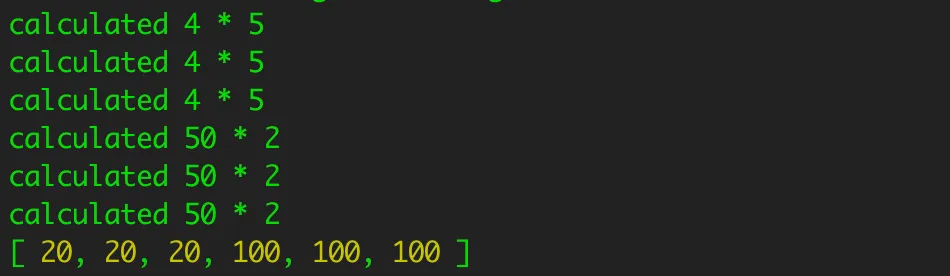
Let’s implement a simple call that takes some time and returns a result. For this purpose, we are going to multiply a couple of values with a 200ms delay that will represent our API call or a database query:
When we execute this code we get what was expected, so no surprises there. We called the function 6 times and waited 200ms for each:
Now, let’s change the exact same code to take advantage of this pattern to improve our application. This time we are going to use an OperationRegistry class to manage our calls for us and, more importantly, we’re gonna create a unique key to identify our operation on the registry.
Once this is done, we call the isExecuting function to see if it returns us a Promise. If it does, this means another execution is already ongoing and we just need to return the Promise waiting for its result. Otherwise, we do the call, propagate the result to all pending Promises and return our value. To pass the result to pending Promises, we use the functions triggerAwaitingResolves or triggerAwaitingRejects, depending on whether the operation was successful or not.
Let’s see what happens when we execute this code a second time:

The result is exactly the same, but our function was only called 2 times instead of the initial 6 — once per unique key. Of course, this pattern will only be beneficial if you hit the same operation multiple times, either because the operations take too much time or because they happen frequently.
But there is a catch: the error and the result are shared by all executions, so be very attentive not to taint the shared outcome, otherwise you might have unexpected bugs. Don’t forget to clone the object if you need to change it.
Conclusions:
- Even though this is not always trivial, for concurrent applications it makes all the difference because resources are a very scarce thing. Moreover, as we have explained in this article, it not only frees those resources up but also improves your application time.
- This will have a huge impact on operations that are called frequently, but more importantly it saves resources and improves system stability. Even a marginal gain helps us to cut out on P99 response times and that is very important.
- If you add a cache on top of this, even better! Just imagine what you could do if instead of saving resources on a single instance, you could save these resources across all instances of a service, because then you have a higher probability of hitting a common resource across multiple instances.
- These small details are what distinguish well-made microservice architectures from poorly implemented ones, because CPU power and memory don’t solve everything and having an optimized service is what distinguishes a winner from a loser.
Thank you
Please share any outcomes resulting from the actions recommended in this article.

