Arockia Nirmal Amala DossFortifying Your Database Migration: A Journey Towards Secure Transitions!As a database developer/architect, one of my most critical challenges is ensuring data security during database migrations. These…Mar 21Mar 21
Taranjit KaurInner Join and Intersect: Bridging Data in SQLExploring INNER JOIN and INTERSECT in SQLOct 27, 20231Oct 27, 20231
Mete Can AkarIntroduction to Creating Unit Tests for PySpark Applications Using unittest and pytest LibrariesTL;DR: Software testing, and in particular, unit testing, is a crucial step in modern Data Engineering. Pytest and unittest are great tools…Oct 22, 20232Oct 22, 20232
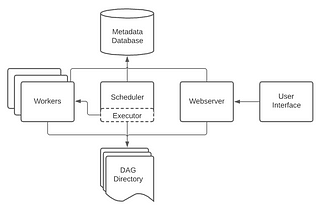
Garvit AryaBuilding Robust Data Pipelines with Apache AirflowApplications of Apache AirflowOct 16, 2023Oct 16, 2023
Chandrashekar MBackfilling Data in Big Data: Uncovering the Depths of Data Consistency and ImpactIn the dynamic realm of Big Data, ensuring the accuracy and completeness of your datasets is an ongoing challenge. Backfilling data is…Oct 13, 2023Oct 13, 2023
Ayşegül YiğitDatabase Storage TypesWhen considering the functions of an Enterprise Data Warehouse (EDW), there is always room for debate regarding how it should be…Oct 13, 2023Oct 13, 2023
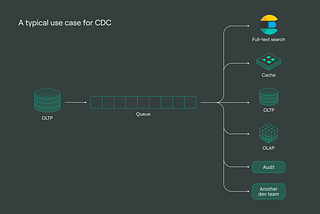
Andrei TserakhauCDC from zero to heroHow to master cross-system data transfer with CDCOct 13, 2023Oct 13, 2023
Ayşegül Yiğit📚 What is a Data Warehouse?A Data Warehouse (DW) is the process of collecting and managing data from various sources to provide meaningful insights about a business…Sep 27, 20234Sep 27, 20234
Ravish KumarDrowning in Data: Why more data doesn’t equal more valueSometimes quality is better than quantity!Sep 27, 2023Sep 27, 2023
Vivek ChaudharySpark AQE- Dynamic CoalescingThe Objective of this article is to understand a newly added feature in Spark 3.0 that is AQE (Adaptive Query Execution) to enhance Spark…Sep 27, 20232Sep 27, 20232