Stable Diffusion Explained Step-by-Step with Visualization

Diffusion Explainer is a perfect tool for you to understand Stable Diffusion, a text-to-image model that transforms a text prompt into a high-resolution image. For example, if you type in a cute and adorable bunny, Stable Diffusion generates high-resolution images depicting exactly that — a cute and adorable bunny — in a few seconds. Diffusion Explainer provides a visual overview of Stable Diffusion’s complex structure as well as detailed explanations for each component’s operations. You can also interactively change text prompts, timestep, and hyperparameters.
Stable Diffusion at the High Level
Diffusion Explainer shows Stable Diffusion’s two main steps, which can be clicked and expanded for more details.
- Text Representation Generator converts a text prompt into a vector representation to guide the image generation.
- Image Representation Refiner refines random noise into a vector representation of a high-resolution image over multiple timesteps.
Text Representation Generator

Clicking Text Representation Generator shows how a text prompt is tokenized into a sequence of tokens. For example, the text prompt a cute and adorable bunny is split into the tokens a, cute, and, adorable, and bunny, and the token sequence is padded with <start> and <end> tokens.
Each token is then converted into a vector representation containing image-related information by the text encoder of a neural network called CLIP. CLIP, which consists of an image encoder and a text encoder, encodes an image and its text description into vectors close to each other. Therefore, the text representation computed by CLIP’s text encoder would contain information about the images described in the text prompt.
Image Representation Refiner

Clicking Image Representation Refiner displays how Stable Diffusion refines random noise into a vector representation for a high-resolution image that adheres to the text prompt. Image representation is gradually denoised by iteratively predicting and removing noise.
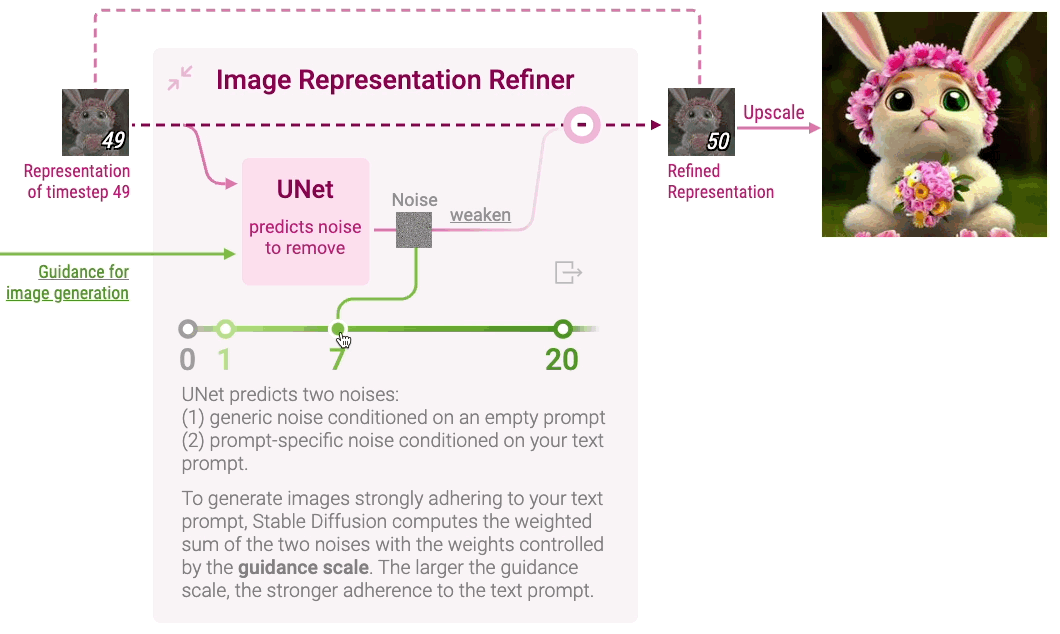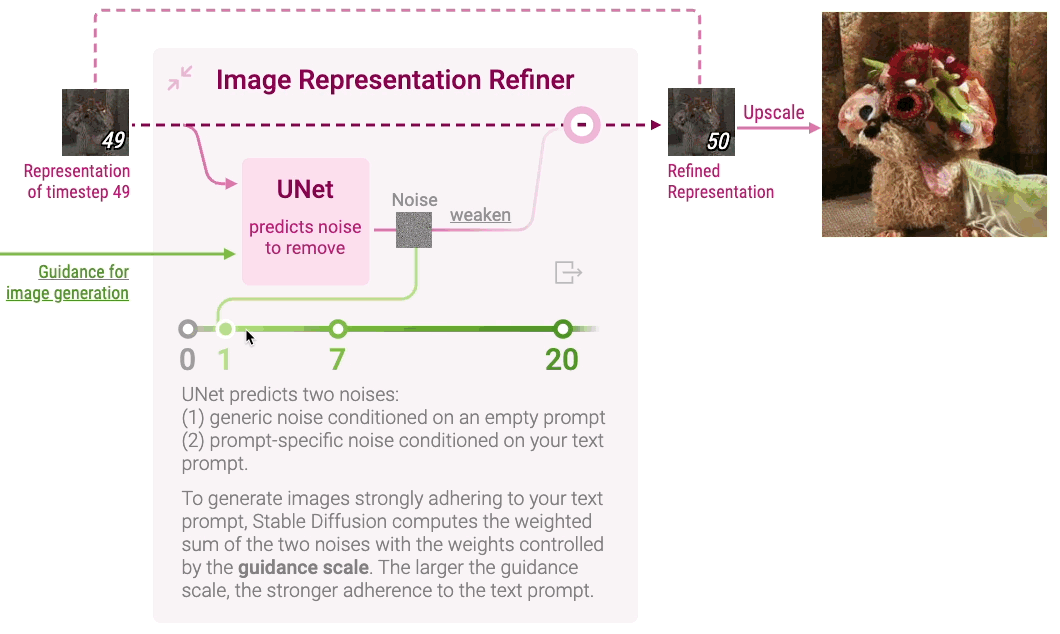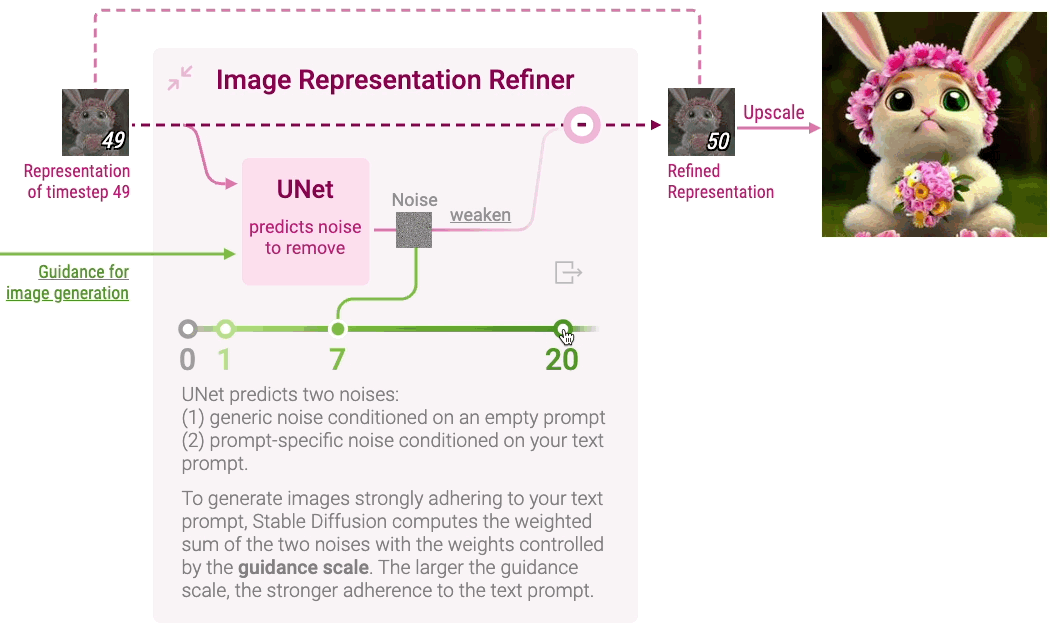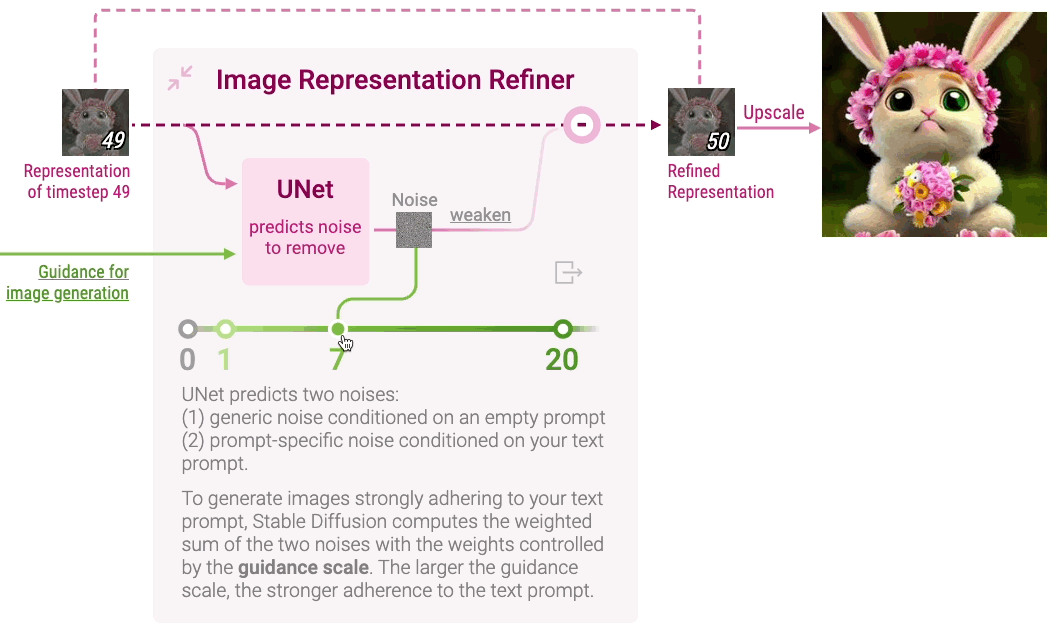
Expanding Image Representation Refiner shows a neural network called UNet that predicts noise in the image representation of each timestep with the guidance of the representation of the text prompt. However, even with the guidance, the adherence of image representation to the text prompt is often very weak. For stronger adherence, Stable Diffusion introduces a hyperparameter guidance scale: a higher guidance scale results in stronger adherence to the text prompt. You can experiment with different guidance scale values on the Diffusion Explainer. Stable Diffusion then downscales the predicted noise and removes it from the image representation.
After iterating for all timesteps, the final image representation is upscaled into a high-resolution image. Check out Diffusion Explainer to see how multiple components of Stable Diffusion work together to create an image that strongly adheres to the text prompt.
How Prompts Affect Image Generation

Diffusion Explainer allows you to understand the impact of prompts on image generation by comparing the image generation of two similar text prompts. For example, you can visually examine how adding in the style of cute pixar character to the prompt leads the image representation to diverge and results in a more cartoony and vibrant image.
Conclusion
We hope you have got a better understanding of Stable Diffusion from Diffusion Explainer! For more details, watch our 2-minute YouTube demo video and check our research paper. Please reach out to us for any comments or feedback.
Authors
- Seongmin Lee (@SeongminLeee) is a PhD student at Georgia Tech.
- Ben Hoover (@Ben_Hoov) is a PhD student at Georgia Tech and a Researcher at IBM Research.
- Hendrik Strobelt (@hen_str) is a Researcher at IBM Research AI.
- Jay Wang (@Jay4w) is a PhD student at Georgia Tech.
- Anthony Peng (@RealAnthonyPeng) is a PhD student at Georgia Tech.
- Austin Wright (@austin_p_wright) is a PhD student at Georgia Tech.
- Kevin Li (@KevinYLi_) is a PhD student at Carnegie Mellon University.
- Haekyu Park (@haekyuparkv) is a PhD candidate at Georgia Tech.
- Alex Yang (@AlexanderHYang) is a Software Engineer at Goldman Sachs.
- Polo Chau (@PoloChau) is an Associate Professor at Georgia Tech.
Acknowledgements
This work was supported partly by Cisco, DARPA GARD, J.P. Morgan PhD Fellowships, and Apple Scholars in AI/ML PhD fellowship.
