Reimplementation of Hogwild!: A Lock-Free Approach to Parallelizing Stochastic Gradient Descent
Authors: Rachit Dubey, Yuting Yang, and Darby Haller. COS 518, 2020
Background
In a typical machine learning problem, given the training data, the goal is to learn the parameters of a function that best fits the given data. Learning this function is useful as it allows us to make future predictions about the data. To achieve this goal, generally, we train a model to minimize the error function — a function that captures how far away the model predictions are from the ground truth.
A popular algorithm used to minimize error functions is the gradient descent algorithm. In gradient descent, we begin from a random estimate of the solution and then update the estimate by taking a finite step along the slope of the function (i.e. the gradient). This process is repeated iteratively until the minimum of the function is reached. Gradient descent is especially useful for convex functions, as it is guaranteed to minimize the error function for a convex function after a finite number of iterations. However, for more complex functions, gradient descent requires many iterations before reaching a good solution.

Stochastic Gradient Descent
The stochastic-gradient descent (SGD) algorithm is a variation of gradient descent that addresses some of the limitations of the gradient descent algorithm. In SGD, during each iteration, a random point from the training data is sampled and then a gradient-descent like update is performed with respect to that single point. One of the biggest advantages of SGD is that it has a very small memory footprint and a rapid learning rate thereby making SGD extremely popular for a variety of machine learning tasks.
However, SGD is inherently a serial algorithm: it updates the parameters after seeing every example. Thus, SGD’s scalability is limited by its inherently sequential nature; it is difficult to parallelize as each thread must wait for another thread to update before the next iteration.
Hogwild! Parallelizing SGD by a lock-free approach
The Hogwild! algorithm was one of the first proposals that showed how to implement SGD in parallel. It was developed by Niu et. al. [1], and it is a strategy to run SGD in parallel without locks. The main idea of Hogwild is to remove all thread-locks from parallel SGD i.e. threads can overwrite each other by writing at the same time and then computing gradients using a stale version of the “current solution”. Interestingly, Niu et. al., showed that along with having benefits of multiple threads, Hogwild doesn’t have any negative effects on the mathematical efficiency or performance of SGD.
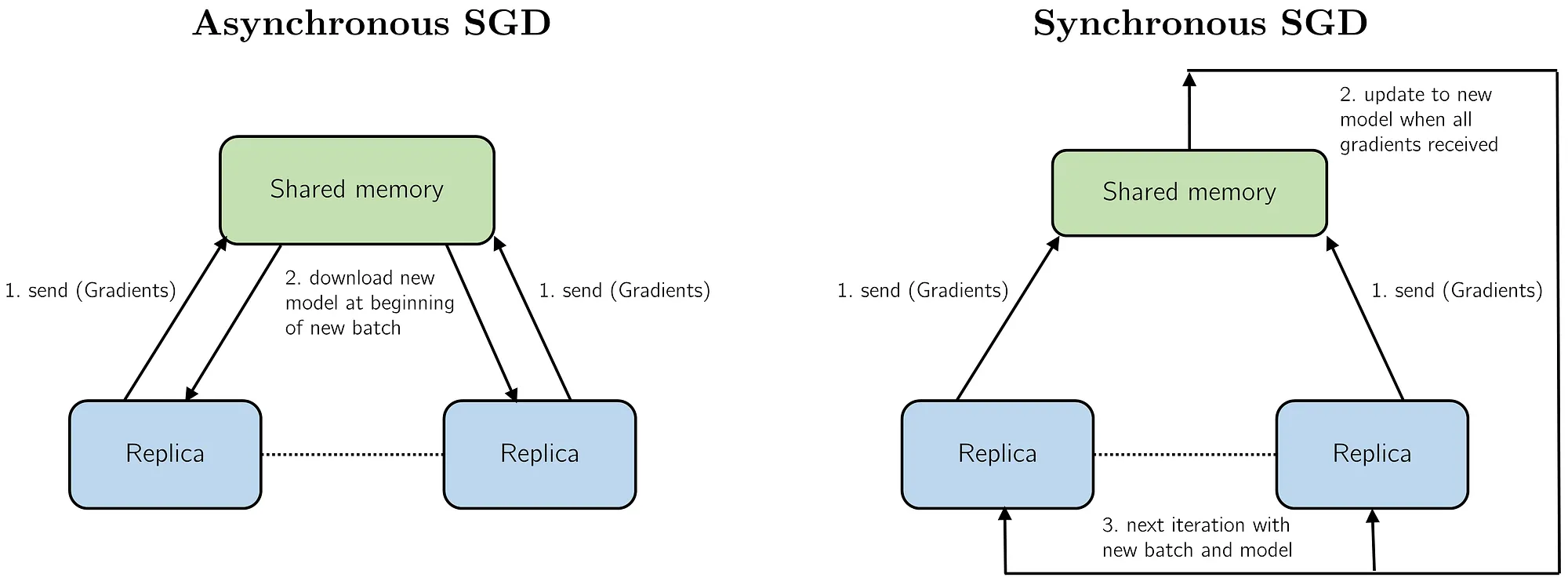
Asynchronous vs. Synchronous SGD
Hogwild! was influential in starting a trend in the use of asynchronous SGD for model training. In asynchronous SGD, replicas work at their own pace, without waiting for other replicas to finish computing their gradients (also shown in the below figure). However, in asynchronous SGD, because replicas update the parameters independently, scenarios can arise where the global parameters are updated with old versions of the parameters. Thus, this can lead to poorer performance/ slower convergence of the SGD as more replicas are added.
An alternative approach to parallelizing SGD is using synchronous SGD. In the synchronous setting, all replicas average all of their gradients at every timestep (also see the figure below). This is advantageous as the computation is now completely deterministic and it is fairly easy to debug and analyze the model training. However, in synchronous SGD, because all the gradients are updated at every timestep, even if one of the replicas is slow, then all the remaining replicas will remain idle as they have to wait for that replica to finish its update.
The current project
In this project, we reimplement and perform a comprehensive evaluation of the Hogwild! algorithm [1] by conducting several experiments. In Experiment 1, we test the effectiveness of Hogwild for learning support vector machines (SVM) on a synthetic dataset. Furthermore, we also compare its performance against Synchronous SGD as well as a round-robin baseline on this synthetic dataset. In Experiment 2, we test the execution and performance of Hogwild on a more realistic dataset: the popular image classification benchmark, CIFAR10. Finally, in Experiment 3, we test the performance of Hogwild on a linear regression task. Through these experiments, we aim to replicate the main findings of the Hogwild! paper and also hope to gain some insights on the advantages of synchronous vs. asynchronous SGD.
Implementation
Design choices
We implemented our framework based on python’s multiprocessing library for managing multiple workers and the numpy library for vector/matrix computation. As in Hogwild!, all of our experiments are launched on a single multiprocessor machine with shared memory, therefore the process that runs the main program (which we call the master process ) naturally serves as the parameter server. This allows us to not worry about network communication between different workers.
For synchronous SGD, each worker does not update the training model themselves, instead, they receive the model and the training samples from the master process after which they return the computed gradient to the master. Therefore the master keeps the model local and passes a read-only copy to all the workers. In contrast, for Hogwild! (or equivalently asynchronous SGD), because workers need to update the training model after they compute the gradient for a mini-batch, the model must be shared among all processes or else the local changes will not be seen by the other workers or the master. We, therefore, used a shared memory array to store the learning model and passed the array location to all workers.
Another design decision that was vital to the performance was how the training examples were passed to the workers. The most naive way would be to directly pass mini-batch tensors to the worker processes. However, due to python’s multiprocessing job creation system, the function that the job calls as well as the input arguments to each worker are all pickled before instantiation. This means that although python almost always passes by reference in its prototype, it passes a copy of the input object to each of the multiprocess workers. This limitation introduces performance degradation as the size of the training dataset increases. To solve this problem, we again leveraged the shared memory array wherein all training examples were stored in a read-only array that was shared across all processes. Therefore, only the array location and indices to training mini-batch were passed to each worker. This resulted in greatly reducing the input argument size as well as increasing the performance of parallel training.
For asynchronous SGD, we also empirically explored multiple design possibilities on how to pass mini-batches (indices) to the worker processes. Note that the design choice for synchronous SGD was more straightforward because the workers need to report back to the master at the end of each mini-batch. We experimented with three choices for asynchronous SGD.
(1) Instantiate workers per epoch and pass the indices of mini-batches containing all examples appearing exactly once.
(2) Instantiate workers only once for the entire training process and pass the indices of mini-batches that contain examples occurring irrespective of the total epoch number.
(3) Use a queue server to continuously put training indices together with the correct epoch-related hyperparameters (e.g. learning rate) while each worker reads from the queue.
Intuitively, (2) should be strictly better than (1) as it saves time to instantiate new workers at the beginning of each epoch. However, empirically we found the choice 2 was only marginally faster than (1) while (2) lost the flexibility of scheduling hyperparameters per epoch as well as monitoring the training progress per epoch. (3) is more flexible in passing parameters and should incur lower worker instantiation overhead as the system with N workers can start training as long as there are N items in the queue, while in (1) and (2) the multiprocessing library has to first unpickle the input arguments whose size is related to the size of the training dataset. However, empirically we found that (3) was much slower than (1) and (2), possibly because the learning tasks that we are experimenting with (SVM and linear regression) have relatively fast gradient computation compared to the time that puts item and retrieves from queue. Additionally, (3) also has the downside that it is unable to monitor per epoch training progress. Because of these considerations, we used (1) to instantiate workers at the beginning of each epoch.
Machine learning details
Asynchronous SGD trains on the examples epoch by epoch until convergence, modifying the model parameters at each step to better fit the training data. At each epoch, we split up all of the examples, and randomly assign an equal portion of them to each replica. Then, without any coordination, each thread iterates over its assigned examples one by one, using whatever the model parameters currently are to try to classify a training example, and then sending a message to the central coordinator (or equivalently the master process) to move the model parameters in a certain direction. There is no attempt made to guarantee that the move will be made before the model parameters are used to make another prediction. In an imagined strawman scenario, this means that the model parameters could be used to make a prediction, the correction according to that prediction sent back to the central coordinator, but before that message reaches the central coordinator and the update is applied, those same old model parameters are used to make a different prediction on a different replica, which then would send a message to move the model parameters in a similar direction. If N is the number of replicas, N many such “duplicate” messages could be generated, having the effect of making the batch size stochastic (when such duplicate messages are sent, it is as if all of their examples were processed in the same combined batch).
Synchronous SGD follows a similar pattern, but with one key difference. It also trains on the examples epoch by epoch, but instead of splitting up the examples on a per epoch basis, it splits them up on a per batch basis. Each replica also calculates an update for each example one by one, but instead of immediately applying this update, it accumulates all of the updates for all of its examples into one super-update and returns this super-update to the central coordinator. Then, the central coordinator waits until it has received super-updates from all of the replicas. Then, it combines those super-updates into an update which represents all of the training examples in the batch and uses this combination of the super-updates to move the model parameters. Therefore, synchronous SGD is equivalent to vanilla SGD in terms of the update it will compute off of each batch but is faster as it is scalable.
Evaluation
Experiment 1: Evaluating SVM implementation on a synthetic dataset
We begin by testing our SVM implementation of hogwild on a synthetic toy dataset. Using a synthetic dataset is beneficial as it allows us to customize the dataset and evaluate hogwild on a wide range of settings. As in the original hogwild paper, our experiments use a constant stepsize γ which is diminished by a factor β at the end of each pass over the training set. We also compared the performance of hogwild against a round-robin approach [2](as in the original paper) and additionally also conducted experiments on synchronous SGD.
For our first evaluation, we used a 100-dimensional dataset (dataset sparsity=0.2) with the training set consisting of 10,000 data points and the test set consisting of 1000 data points. We ran each algorithm for 200 epochs and compared the performance of each algorithm for a different number of workers {1,2,4,8, 10}. The learning rate was set to 0.001, the beta was set to 0.99 and the batch size was fixed to 2 for all the algorithms.
Results
We first see in Figure 1(a) that Hogwild! is able to achieve a speedup of 4 while RR remains pretty much the same as more threads are added. This replicates the main results of the original Hogwild! paper (Figure 2 in the paper).
Interestingly, we observe that synchronous SGD achieves a faster speedup compared to asynchronous SGD i.e. hogwild. However, upon further investigation, we note that while synchronous SGD performs the 200 epochs faster, it fails to converge and learn at the rate at which hogwild does. This is especially notable when we look at the error of synchronous SGD and hogwild on the test set (Figure 1 (b)). We observe that the test error of hogwild remains the same as more threads are added but the test error of synchronous SGD increases as more threads are added. Interestingly, the performance of synchronous SGD is worse when the number of threads is 2 and seems to improve slightly with an increase in the number of threads but it never reaches the performance of SGD when the number of threads is 1.

We investigate this behavior further by looking at the convergence of the three algorithms on the training set. In Figure 2(a), we see that hogwild converges at nearly the same rate irrespective of the number of threads (although when number of threads is equal to 1, the convergence is slightly faster). This indicates that adding more threads doesn’t impact the performance of hogwild algorithm on the synthetic dataset significantly. We observe a similar trend for the round-robin method in Figure 2(b). However, we see that synchronous SGD performs much more poorly as the number of threads increase (Figure 2(c)). Notably, the performance of synchronous SGD is especially poor when the number of threads is 2 and 4 and shows a slight improvement when the number of threads is 8 and 10 (but it is still less effective than the case where the number of threads is 1).

For our next evaluation, we compared the execution of hogwild as a function of dataset size. More specifically, we ran hogwild on 4 different datasets of size 10000, 50000, 100000, and 500000 respectively. We conducted this evaluation to test the execution of hogwild as the size of the dataset increases. We ran hogwild for 20 epochs for a different number of workers {1,2,4,8, 10} and all other parameters were kept the same as the previous evaluation. As shown in Figure 3, we observe that hogwild becomes more advantageous as the size of the dataset increases. More specifically, when the dataset is of size 500000, hogwild offers a speedup greater than 5 when the number of threads is 10.

Takeaway
Our first evaluation replicates the main results of the hogwild paper. Additionally, we compare hogwild’s performance against synchronous SGD and find that hogwild offers more benefits than synchronous SGD on our dataset as the performance of hogwild is not significantly affected when the number of threads is increased (whereas the performance of synchronous SGD is).
Experiment 2: Evaluating Hogwild! on CIFAR10
While our previous evaluation tested Hogwild! on a synthetic dataset, we now evaluate Hogwild! on a more realistic dataset —the CIFAR10 image dataset. Our training set consisted of 10000 data points and the validation and test set consisted of 1000 data points. For our evaluation, we used the raw image pixels which meant that our dataset was a 3072-dimensional dataset (32x32x3). We then used SVM to perform classification using this feature set. Note that we do not expect SVM to perform very well on CIFAR (especially by just using the raw pixels as features), but that doesn’t interfere with our main goal of this evaluation.
For our evaluation, we ran hogwild! for a different number of workers {1,2,4,8, 10} using batch size = 2 and batch size = 125. Our goal here is to test the effectiveness of Hogwild! on CIFAR as well as test the effect of batch size on the performance of Hogwild!. For batch size = 2, we ran hogwild for 20 epochs and set the learning rate = 0.000001. For batch size = 125, we ran hogwild for 100 epochs and set the learning rate = 0.000002. Note that the learning rate was set after performing tuning on the validation set.
We first observe that with a batch size of 2, hogwild again offers considerable speedup on learning SVM on CIFAR (Figure 4(a)). This suggests that hogwild can be scaled up and used in more realistic settings. Interestingly, when the batch size is 125, increasing the number of threads leads to a decrease in the execution time of hogwild. This suggests that hogwild offers little benefit with large batch sizes. Next, we see that when batch size is 2, the performance of hogwild is not affected greatly when the number of threads is increased (Figure 4(b)). Further, we see that with batch size of 125, the performance of hogwild starts to increase as the number of threads increases however this is not that beneficial as increasing the number of threads leads to slower performance.

Figure 5 additionally plots the training performance of hogwild for batch sizes of 2 and 125 respectively. We note that this in line with results plotted in Figure 4(b), namely that increasing the number of threads doesn’t affect the performance of hogwild especially for batch size = 2. We do note that we could have run hogwild with batch size of 2 for a higher number of epochs to allow for convergence. However, we ran hogwild with the batch size of 2 only for 20 epochs since we were constrained with the number of jobs we could launch and smaller batch sizes need more time to run. This trade-off about batch sizes should be considered by researchers when looking to use hogwild on more realistic datasets.

Takeaway
Our second evaluation shows that hogwild can be used to speed up SGD on CIFAR. However, hogwild is not effective when the batch size is higher and this a trade-off researchers need to consider.
Experiment 3: Evaluating regression implementation
For our next evaluation, we tested the execution and performance of hogwild on linear regression. For this, we constructed a synthetic 5-dimensional dataset consisting of 5000 data points. We then ran hogwild for 100 epochs for a different number of workers {1,2,4,8, 10} with learning rate equal to 0.001. Figure 6 (a), shows that hogwild again offers a good speedup as the number of threads is increased for the regression task as well. Furthermore, we see that while serial SGD (i.e. number of threads =1) converges faster, the performance of hogwild is not significantly affected as the number of threads is increased (Figure 6(b)). This confirms one of the main implications of the Hogwild! paper in that hogwild can be used to speedup SGD for a variety of machine learning tasks.

Conclusion
In this project, we successfully replicated Hogwild! and some of the evaluation carried out by the authors. We were able to get similar results and can conclude that Hogwild! can speed up SGD without significant loss of performance on a variety of machine learning tasks.
Our code is available at https://github.com/yyuting/cos518
References
[1] Recht, B., Re, C., Wright, S., & Niu, F. (2011). Hogwild: A lock-free approach to parallelizing stochastic gradient descent. In Advances in neural information processing systems (pp. 693–701).
[2] Langford, J., Smola, A., & Zinkevich, M. (2009). Slow learners are fast. arXiv preprint arXiv:0911.0491.