Tuning Fluentd: Retries — Avoiding Duplicate Documents in Elasticsearch
We are working hard at Redbox to rebuild our existing platform into a truly cloud native platform to support our new streaming platform — Redbox On Demand. In a previous article, we mentioned how we use Fluentd to treat logs as a scalable event streams. If you haven’t, check out the article:
Fluentd is an open source data collector, which lets you streamline data collection, routing and aggregation. As with any system, tuning and operationalizing is a moving target. You need to ensure you have accurate observable metrics and usage data to properly tune your systems based on your workloads. This article addresses an issue we encountered using Fluentd with Elasticsearch (namely duplicate logs) and how we solved it!
Go-Live Day
At Redbox, developers are empowered to build the custom metrics and monitoring, in partnership with SREs, they need to ensure their service is operational. A good example of this is our Go-Live dates. On every Go-Live of a new service, developers are actively monitoring their infrastructure with both application logs in Elasticsearch/Kibana and Time Series Metrics using Prometheus — more on this soon.

Recently, we launched a new service and we anticipated heavier load due to an increase in traffic and general usage patterns. Despite the additional load, our new service launched successfully and was resilient enough to handle the expected and unexpected traffic. While our customer facing story was a success, our internal monitoring tools (in specific our logging aggregator) said otherwise. Reports of severely delayed log processing, duplicated logs events, and large I/O spikes were reported by our developers who were actively monitoring their systems.
Investigation

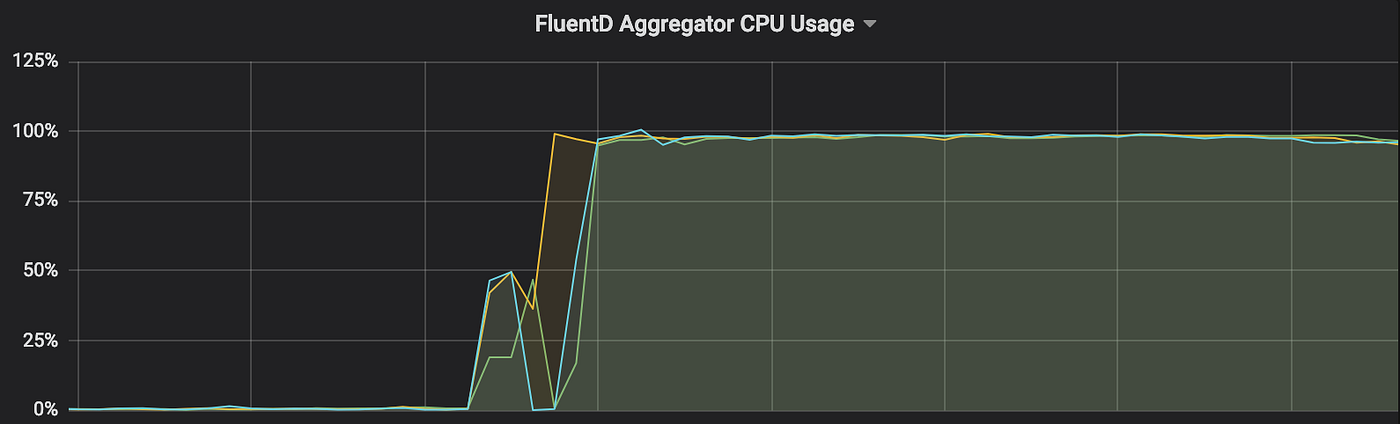
Upon investigation, the Cloud DevOps team noticed a huge set of inconsistent peaks of network traffic egressing to our Elasticsearch endpoint. In addition, autoscaling kicked in for Fluentd due to high CPU usage on Fluentd aggregators. It was consistent and never settled down. Furthermore, new servers that spun up to handle the load also quickly ramped up to 100% utilization as well. Something was definitely off.
While investigating the issue further, we also found BufferQueueLimitError warnings/errors in the Fluentd logs.
[warn]: emit transaction failed: error_class=Fluent::BufferQueueLimitError error=”queue size exceeds limit” tag=”fluent.warn”
[warn]: emit transaction failed: error_class=Fluent::BufferQueueLimitError error=”queue size exceeds limit” tag=”fluent.warn”
[warn]: emit transaction failed: error_class=Fluent::BufferQueueLimitError error=”queue size exceeds limit” tag=”kubelet”Fluentd was unable to write to the buffer queue, but more importantly it also could not clear the buffer queue either. Knowing this, we were able to understand why our boxes were rapidly climbing to 100% CPU.
The issue was we were getting consistent log traffic into our Fluentd Aggregators. Fluentd was not able to clear its buffer causing the buffer to pile up and an exponential amount of retry events. With this in mind, we narrowed the problem to one of our various outputs — in our case, it was a problematic Elasticsearch cluster.
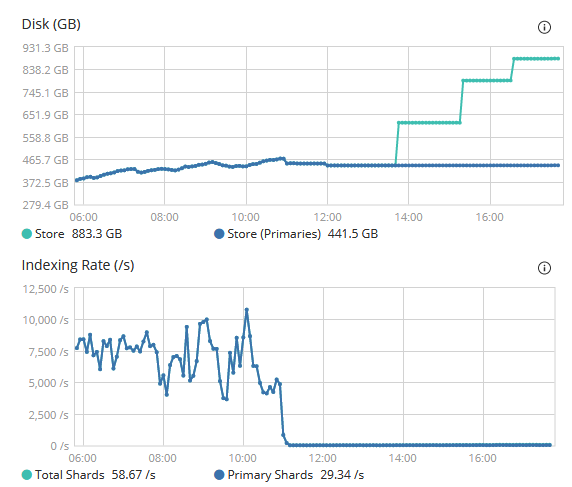
While looking at our metrics for Elasticsearch, it was clear we were seeing a performance hit on our Elasticsearch endpoint due to this large influx of traffic and inability to handle the incoming requests. Digging deeper into the Fluentd logs, we also noticed warnings that said Fluentd "could not push logs to Elasticsearch" (in some cases rejected). However, we did notice that some retry attempts were working as expected.
[warn]: #1 failed to flush the buffer. retry_time=1 next_retry_seconds=[...] chunk="12ab34cd56ef7890ef87ab34ef" error_class=Fluent::Plugin::ElasticsearchOutput::RecoverableRequestFailure error="could not push logs to Elasticsearch cluster"[warn]: #2 retry succeeded. chunk_id="12ab34cd56ef7890ef87ab34ef"
At this point, something was not adding up. We calculated our incoming log network traffic versus our egress network traffic and noticed it did not align to our expected usage. We were seeing about a ~4x difference in egress network traffic (as shown above)! It quickly became apparent that there was clearly an event duplication issue between Fluentd and Elasticsearch which was most likely causing duplication in processing of logs and ultimately the performance issues.
Solution
After doing some research, we found some optimizations we could implement on our buffers — reducing the amount of items in our queue, size of buffer, etc. While these helped in terms of queue size and CPU utilization, they did not solve the duplication issue. After chatting with other users on the Fluentd Community Slack, we discovered our issue.
A thing to know about Elasticsearch is that by default all records inserted into Elasticsearch get a random _id to help index your documents. Fluentd’s output plugin also has the ability to retry failed events. This functionality is extended by the fluentd-plugin-elasticsearch as well.
With that information in mind, whenever Fluentd attempts to retry sending failed events (such as the cluster issues, network failures, etc) to Elasticsearch, it will do so with a new and unique _id value. As a result, a congested Elasticsearch cluster that rejects events will cause Fluentd to re-emit the event with a new _id next time. However, Elasticsearch may actually process all of the attempts (with some delay) and create duplicate events in the index (since each have a unique _id value).
Now that we know why we were seeing duplicate logs, we needed to figure out how to prevent the same log event from being inserted multiple times. Fortunately, a user in the Fluentd Slack found an interesting Github Issue that described exactly what we saw. The best part, it offered two solutions to fix the problem of duplicate _id fields!
Solution: Leverage an external plugin to generate a _hash
If you happen to have a consistent set of unique value fields (such as a transaction id or request id) per event, it possible to use the fluent-plugin-genhashvalue plugin. This plugin allows you to create generate a unique _hash key in the record of each event based on a set of keys that you specify; along with options to include timestamps and tags to increase randomness. This _hash record can be used as the id_key to prevent Elasticsearch from creating duplicate events.
The downside of this solution is a bit more involved. It will enforce that you have a consistent and unique key that has a unique value per event available across all of your logs. Remember, a timestamp is not unique enough in the event of a multiple line event!
Regardless, a sample implementation of this would look like:
# Create a filter
<filter **>
@type genhashvalue
keys sessionid,requestid,put_something_here # example field names
hash_type sha1 # md5/sha1/sha256/sha512
base64_enc true
base91_enc false
set_key _hash
separator _
inc_time_as_key true # add time as a key to increase randomness
inc_tag_as_key true # add the tag as well to increase randomness
</filter># Apply value from filter to id_key field
# Elasticsearch also doesn't like field names with `_` so remove it.
<match **>
@type elasticsearch
hosts elasticsearch.local:9200
[..]
id_key _hash
remove_keys _hash
[..]
</match>
While this solution could work, it did not for us as we did not have the ability to add unique hashes to all of our distributed workloads. Ultimately, we found a better solution we prefer.
Solution: Leverage the bundled elasticsearch_genid filter
As mentioned earlier, the FluentD Elasticsearch plugin does not emit records with a _id field by default. This means Elasticsearch will generate a unique _id as the record is indexed. When an Elasticsearch cluster is congested, Fluentd will re-send the same bulk request resulting in duplicate data. This can result in essentially and infinite loop generating multiple copies of the same data (as seen earlier).
Good news! The Fluentd Elasticsearch plugin comes with a simple bundled elasticsearch_genid filter that can generate a unique _hash key for each record. The key appears to be a random UUID. This generated key can passed to the id_key parameter in the Fluentd Elasticsearch plugin to communicate to Elasticsearch a unique request so that duplicates will be rejected or simply replace the existing records.
Here is a sample configuration of this in action:
## Generate a unique hash of every event to prevent duplicates
# @see https://github.com/uken/fluent-plugin-elasticsearch#generate-hash-id
<filter **>
@type elasticsearch_genid
hash_id_key _hash
</filter># Apply value from filter to id_key field
# Elasticsearch also doesn't like field names with `_` so remove it.
<match **>
@type elasticsearch
hosts elasticsearch.local:9200
[..]
id_key _hash
remove_keys _hash
[..]
</match>
Takeaways
- Leverage observable metrics to check the state of your running applications — both external and internal facing. These metrics allowed us to quickly determine the impact, and triage the proper teams to solve the issue. In our case, fortunately it was our backend infrastructure systems that experienced a bottleneck; however, this is not acceptable. Just as our developers create great services and products for our customers, internal DevOps/SRE teams are on the hook to provide the same experience for our internal customers.
- When in doubt, ask for help. When this issue occurred, both developers and DevOps teams came together to come up with a solution. While the DevOps team worked to solve the performance issues on Elasticsearch, developers actively worked on tuning down their logs and adding compression to allow Fluentd to catch up.
- Community and Documentation. Thanks to a wonderful Fluentd community and open source contributions, we were able to find a common solution. As with any project, it is only as good as it’s user documentation, but more importantly the people around it as well. We hope we pay it forward to others working on tuning their Fluentd environment with this article!
We Are Hiring!
Building a truly cloud native platform requires hard work. We are always looking for great engineers to join us and help build! Feel free to check out our Careers page for job opportunities!

