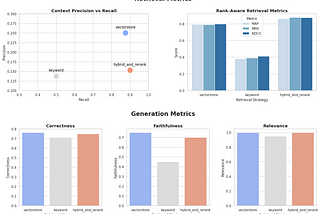
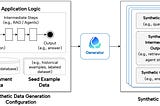
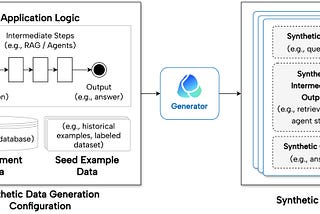
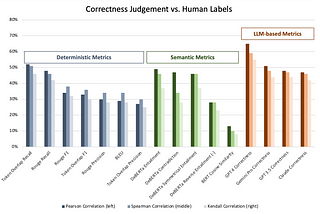
Yi ZhangCase Study: Using Synthetic Data to Benchmark RAG SystemsEnd-to-end example of generating synthetic data using continuous-eval to evaluate and benchmark RAG systems.7 min read·May 30, 2024----
Yi ZhangGenerate Synthetic Data to Test LLM ApplicationsLearn how to generate large-scale application-specific synthetic data to test LLM applications. Try for yourself with RAG and Agent…8 min read·May 7, 2024----
Yi ZhangHow to evaluate complex GenAI Apps: a granular approachThe blog post explains how to evaluate complex, multi-step GenAI application pipelines. It walks through an example using continuous-eval.6 min read·Feb 27, 2024--1--1
Yi ZhangCase Study: Reference-free vs Reference-based evaluation of RAG pipelineSeries of blog posts to share our perspectives on how to evaluate and improve your LLM and RAG Pipelines6 min read·Jan 29, 2024--1--1
Yi ZhangHow important is a Golden Dataset for LLM pipeline evaluation?Series of blog posts to share our perspectives on how to evaluate and improve your LLM and RAG Pipelines5 min read·Jan 29, 2024----
Yi ZhangA Practical Guide to RAG Evaluation (Part 2: Generation)Series of blog posts to share our perspectives on how to evaluate and improve your LLM and RAG Pipelines9 min read·Dec 20, 2023--2--2
Yi ZhangA Practical Guide to RAG Pipeline Evaluation (part 1)Series of blogs on how to evaluate and improve your LLM and RAG Pipelines. Deep dive into pros & cons of deterministic and LLM-based…11 min read·Dec 11, 2023--2--2