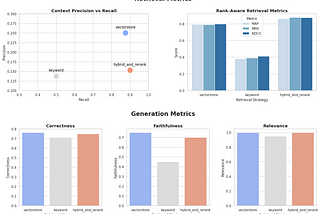
Yi ZhangCase Study: Using Synthetic Data to Benchmark RAG SystemsEnd-to-end example of generating synthetic data using continuous-eval to evaluate and benchmark RAG systems.May 30May 30
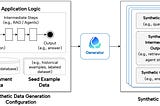
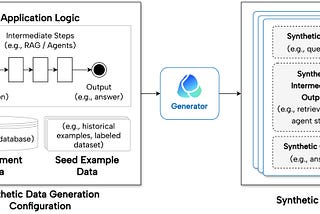
Yi ZhangGenerate Synthetic Data to Test LLM ApplicationsLearn how to generate large-scale application-specific synthetic data to test LLM applications. Try for yourself with RAG and Agent…May 7May 7
Yi ZhangHow to evaluate complex GenAI Apps: a granular approachThe blog post explains how to evaluate complex, multi-step GenAI application pipelines. It walks through an example using continuous-eval.Feb 271Feb 271
Yi ZhangCase Study: Reference-free vs Reference-based evaluation of RAG pipelineSeries of blog posts to share our perspectives on how to evaluate and improve your LLM and RAG PipelinesJan 291Jan 291
Yi ZhangHow important is a Golden Dataset for LLM pipeline evaluation?Series of blog posts to share our perspectives on how to evaluate and improve your LLM and RAG PipelinesJan 29Jan 29
Yi ZhangA Practical Guide to RAG Evaluation (Part 2: Generation)Series of blog posts to share our perspectives on how to evaluate and improve your LLM and RAG PipelinesDec 20, 20232Dec 20, 20232
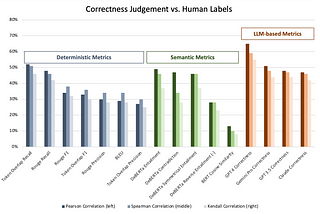
Yi ZhangA Practical Guide to RAG Pipeline Evaluation (part 1)Series of blogs on how to evaluate and improve your LLM and RAG Pipelines. Deep dive into pros & cons of deterministic and LLM-based…Dec 11, 20232Dec 11, 20232