Dialogues on a digital library: Co-designing the Atlassian Research Library
Opening a new library is a moment to celebrate and even though no ribbons were cut, nor doors flung open, it was a delight to recently open the Atlassian Research Library. This digital library currently records research content created by Atlassian’s Research & Insights team. Atlassians can use the library to find research of relevance to their work and to share relevant content with other Atlassians.
Before a library
When I arrived at Atlassian in January 2022, Atlassians could only find research by asking researchers directly about existing research. Many Atlassians would not know how to find a researcher and no researcher was aware of all Atlassian research. While researchers did their best to answer such questions, this approach was inefficient, unreliable, incomplete and rarely covered research content beyond research reports. Recognising connections between research content discovered in this haphazard manner was very difficult. This approach left Atlassian liable to losing knowledge of research undertaken over time.
We sought to address these issues by creating a digital research library which consistently recorded all research content, enabling the content to be searched and browsed in a single space. We wanted Atlassians to easily discover all research content relating to their work.
A Proof of Concept Library to spark conversation
To ensure the library worked with Atlassian content and for Atlassian users, we needed to know what attributes of research content Atlassians would be looking for and what library capabilities would be particularly useful to Atlassians.
Having not previously designed a library, it was difficult for our researchers and other Atlassians to articulate what they needed in such a library.
I therefore built a proof-of-concept library as a basis for meaningful conversations on what was needed in the library.
Of course, assumptions about some aspects of the library had to be made when creating the proof-of-concept library. However, it was made clear that all assumptions were open to being challenged by Atlassians, which they certainly were!
Based on over 20 detailed conversations with individuals and teams both within the Research & Insights Team and beyond, we came up with this structure for the Atlassian Research Library:
A library of record
The Atlassian Research Library records content, including the URL for each item of research content. It houses no content.
This means:
- Research content remains in its original context.
- The content recorded in the library is not duplicated for library storage, so there is no risk of ending up with two different versions of the content, a static, outdated library copy and a dynamic original.
- The content can be created and stored in any software — and it is. We already have research content recorded in the library created and stored in at least eight different platforms. As long as the content has a unique URL, it can be recorded in and found through the Atlassian Research Library.
- Library staff focus on the skilled task of describing the content well, so that it can be easily found, rather than on the relatively unskilled task of converting content for the library into a common format and storing that content in the library space.
One record for each research project
Our proof-of-concept library contained one record for every item of research content.
In this model, it was hard to see the connection between different items of research content arising out of the same research project. Content such as researcher shareback videos and slides or research plans was crowded out by the predominance of research reports.
During our discussions, colleagues expressed a strong desire for all research content to be meaningfully included in the library. While finding research reports in the library was vital, colleagues wanted the library to be more than a repository of research reports. Other content, such as de-identified raw data and shareback videos on research was often shared with teams via instant messaging when a project was finalised but such content was especially difficult to subsequently relocate. Yet this content was valuable because it gave people a variety of ways in which to interact with and better understand the research project.
Therefore, in the Atlassian Research Library, one record is created for each research project, with links in the record to all the research content created as part of that project. This content can include:
- de-identified raw data, often synthesised,
- A research plan,
- A participant recruitment plan,
- A research report,
- Researcher shareback videos and slides and
- Other unique content created for each project.
The user is presented with a complete research project in each result. They engage with the content from the project most relevant to them, whether the research report, a shareback video or perhaps a backgrounder on the personas related to the research project.
Taxonomies, not tagging!
Our discussions on the proof-of-concept library confirmed it was important for Atlassians to find all research content relevant to their work.
Providing colleagues with a proof-of-concept library with some suggested fields prompted much discussion about the fields we could use to describe the content. My colleagues’ ideas led to the creation of new fields in the Atlassian Research Library including a description of research participants, the program of work associated with the research project and the research type.
To ensure all content on a relevant topic could be found by a library user, we chose to populate most fields in the library using consistent language, controlled by taxonomies or term lists created in house, to describe the content.
A term list is simply a list of terms permitted for use in a specific field.
A hierarchical taxonomy takes a broad concept, such as Discovery in the example below, and breaks that concept down into increasing levels of specificity. Any term at any level in the taxonomy may be used in the field with which the taxonomy is associated. We created hierarchical taxonomies to control language in our Subject field and our Participants field.
Applying consistent language to most fields means that the user can be certain they have found all the content in the library on a relevant topic. In fields where hierarchical taxonomies are applied, content closely related to any term can also be easily discovered by browsing the taxonomies.
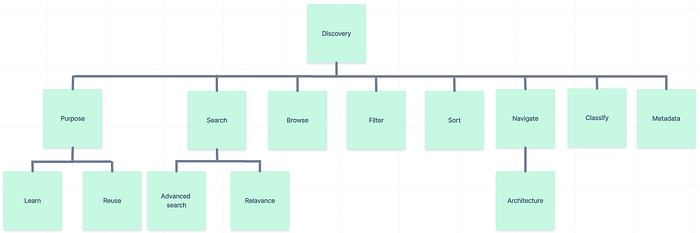
These taxonomies and term lists were created in house, with reference to other term lists and taxonomies already available at Atlassian. They will change, grow and develop as the content in the library changes and as we become more aware of the language naturally used by Atlassians evidenced in our library platform’s search logs.
Making space for free text
While users want the capability to find everything on a given topic, they can sometimes be helped towards finding relevant content via the availability of searchable, free text fields.
To this end, our library contains a number of free text fields, including the title, summary and notably a field entitled “Author contributed tags”. When research content is submitted to the library, the author can tag their work with any terms they think are useful to describe their work and they do so enthusiastically. These author contributed tags are included in the library record and they, like all free text fields, are searchable. This gives space for unique terminology that may be applicable to no other content in the library to be applied to a record and used to discover that content.
Specifications first, then a platform
We did not consider any platform options for the library until we had developed the structure for the library based on the many conversations with users. This structure determined the key specifications for the library platform, which included:
- Excellent discovery capability including search, advanced search, browse and filter
- Highly flexible fields capable of holding many different types of data
- Space to house and manage hierarchical taxonomies and term lists
- Capability for users to interact with the term lists and hierarchical taxonomies as another pathway to content discovery and
- Ease of maintenance.
Based on these specifications, I considered a range of platforms designed for:
- Library management;
- Research management;
- Taxonomy management with some content describing capability; and
- Knowledge management.
We short listed two platforms and at this point, I engaged with eight courageous researchers to consider these two platforms with me and help make the final decision.
This turned out to be a really smart move because, having seen available capabilities in the systems on offer, these researchers came up with two further very detailed but essential specifications, which were the capability to:
- display content in reverse date order down to the day of publication, and
- create alerts on new content on subjects of interest.
We selected KnowAll Matrix by Bailey Solutions, a library management platform with high flexibility in the fields’ format and content. Its design encourages interaction with the taxonomies and term lists managed and applied within the system, as well as providing a wide range of discovery options and a straightforward user interface. Users can easily share and save content and set up alerts for new content of relevance. It is easily maintained by this sole librarian.
Where to with the Atlassian Research Library?
It is very early days for the Atlassian Research Library but an enthusiastic uptake over the first few weeks of the library being open to all Atlassians indicates a pent up demand for such a tool at Atlassian. Already, when researchers are asked about what research exists on a given topic, they’re responding with “Search the Atlassian Research Library”, which is definitely a success!
We are imagining ways to grow the scope of the library. A high priority is the inclusion of research content produced across Atlassian, rather than just the research content produced by the Atlassian Research & Insights Team, as is currently the case. This may present some logistical challenges for this sole librarian but will add significantly to the utility of the library.
As we incorporate the library into our daily work at Atlassian, it will enable Atlassians to discover all research we have on any given topic, raise awareness of research content across Atlassian and automate the sharing of relevant research content in a timely fashion. Thanks to its diverse discovery capabilities, the Atlassian Research Library will help us discover previously unseen connections between research content from different research projects, thereby surfacing new connections and insights.

