Redux Is Dead, Long Live Redux
A quick recap on why Redux isn’t dead and why you should not always listen to others

Starting with the conclusion
Mainly because it’s the most important bit of this article, but also because I’m painfully aware that very few people will read yet another one of those “Redux is not dead” monologues through to the end 😅
Choose whatever solves your specific problem and works best for you, your team and your specific setup.
That’s it. That’s all you need to take away from all of this. All solutions have their benefits and trade-offs, depending on what the exact use case, requirements and restrictions are. Anyone trying to tell you that you have to use a specific solution, without knowing your requirements and the specific problems you’re hoping to solve, is not acting in your best interest.
A bit of background to Redux
Before we dive into the details, let’s do a quick recap to see what Redux actually is and what it’s trying to achieve.
When Dan Abramov introduced Redux in 2015 at React Europe, he spoke about the motivations behind creating it, as well as the problems it was aiming to solve. If you haven’t seen the talk yet, I seriously recommend you do so. Besides being an excellent talk, it really helps understand what Redux actually is and does.
According to Dan, the main motivations to write Redux were:
- state management that works with hot reloading
- predictable flux like state management with (ironically) less boilerplate
- tooling like time travel for better DX
State management that works with hot reloading
The problem: local state and other existing state management solutions often had trouble when it came to hot reloading, e.g. utilising webpacks hot module replacement functionality. Hot reloading allows the dev server to only replace chunks of code related to the files that changed, without needing a whole page refresh, meaning the rest of the application stays untouched.
Redux works really well with this because the state lives in an external store, which keeps track of state and actions. Also, any time reducers change, Redux can simply re-run all actions that happened so far, which means: not only does your state not get lost when you edit files, even better, your app will pick up changes to reducers for past actions, which is super powerful during debugging.
Predictable flux-like state management with less boilerplate
Flux is Facebook’s very own solution for state management, which was and still is pretty popular. If you haven’t looked at it yet, do. You’ll notice it’s very (very) similar to Redux. And that is no accident.
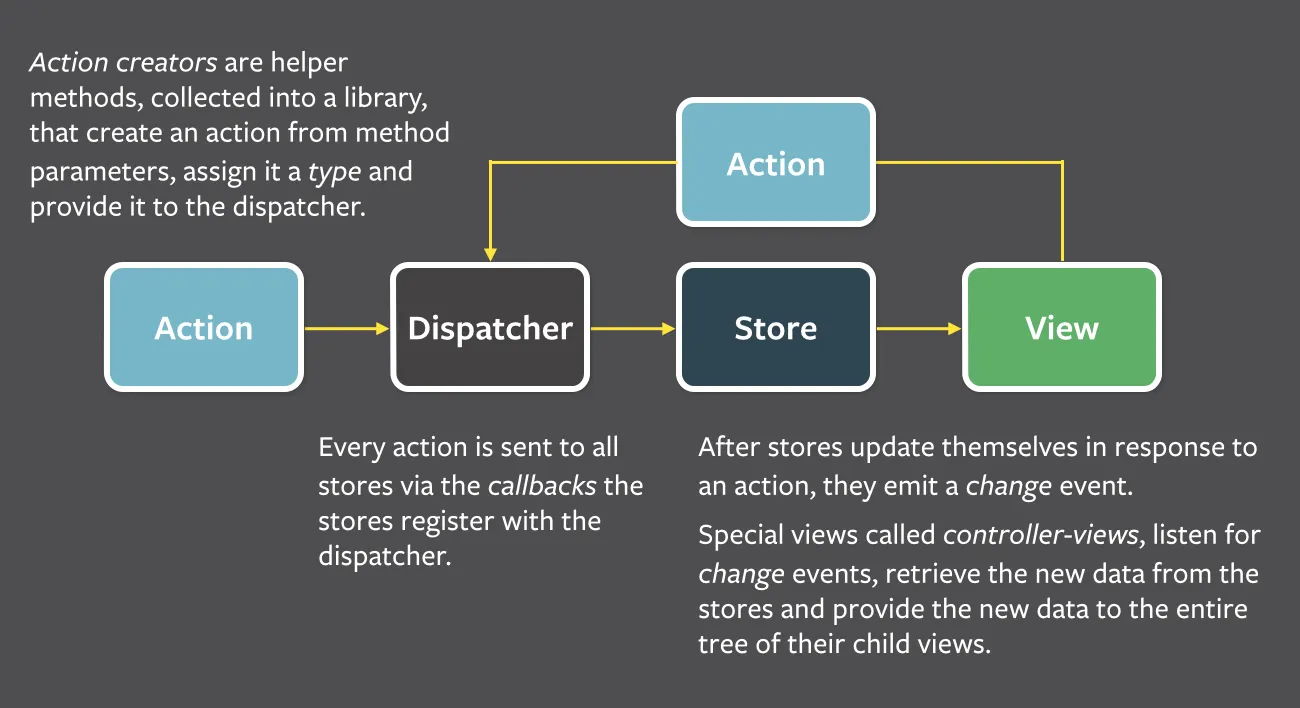
According to Dan Abramov, Redux was supposed to be the implementation of the flux pattern, but with less boilerplate. Yes - as ironic as that might sound, given what everyone in the community these days seems to be complaining about, originally Redux was there to cut down the code needed for predictable state management. And as you can see him demonstrate in his talk, he definitely achieved that.
Why is Redux predictable? Because the state is read-only and can only be changed via pure functions, which are triggered by actions. This provides us with a guarantee that the same initial state with the same actions will always lead to the same outcome, no matter what.
Tooling like time travel for better DX
Dan’s goal in general was a better developer experience (DX), but in his talk he particularly pointed out his ideas around time travelling. He was able to create and show off a proof of concept demonstrating how to take advantage of the core principles of Redux (state manipulations through actions and pure functions), in what turned out to be an early glimpse at the Redux dev tools we know today. It allowed him to scrub back and forward through the store’s state history, skipping and batching actions to help with the coding and debugging process.
Redux Principles
To this day, Redux follows three fundamental principles:
- single source of truth
- state is read-only
- changes to the state are only done by pure functions
Single source of truth
All state is handled by the store (you can have multiple stores, but it’s generally discouraged, since it defeats this core pattern). Also, all actions go through this store, which means everything related to state management goes through the store as its single source of truth.
State is read-only
Exactly what it says. State in Redux is read-only, which means it cannot be directly changed or mutated. This ensures that following the next rule keeps the state predictable and therefore easier to debug and maintain.
Changes to the state are only done by pure functions
The only way to change the state is to dispatch actions, which then trigger pure functions. This will lead to predictability, which is exactly what you want when it comes to state management (especially the more complex the state you try to manage gets).
These pure functions are called reducers. They take the current state and the action with a payload, and provide the new state in return.
Fun fact: this is also where the name comes from, reducer and flux 🤯
What are the benefits?
All the above are the restrictions of the framework, not the benefits. This is a very important distinction, especially when looking at it from the angle of determining the pros and cons of using certain solutions.
The restrictions Redux puts in place will help you to get to the benefits, but they themselves are part of the trade-offs and should be treated that way. No solution for state management will work for all use cases and scenarios. There are always trade-offs, and some trade-offs are worth taking for some scenarios while not for others and vice versa.
Keeping that in mind, the question “what solution should I use?” crumbles really quickly. The answer always depends on the problem you’re actually trying to solve and what your specific use case is!
To be able to judge whether the trade-offs are worth it, it always helps to look at the benefits Redux brings:
- state management that works with hot reloading
- predictable flux like state management
- tooling and large community
- easy to persists (due to having the whole state in a single place), e.g. using local storage
- easy to make use of server or web sockets to share state across multiple users/machines
This is by no means an exhaustive list, it’s just some common benefits off the top of my head. We’ve already touched on some of these, but I’ll try to give some more context around the others.
Tooling and large community
The wide adoption of Redux in the beginning meant the birth of a huge number of open source libraries dealing with a range of different problems. So whatever problem you have, unless it’s really edge-casey, you are very likely to find a library that deals with it or at least something very similar.
The fact that Redux itself was introduced with a focus on improving DX means that the tooling is pretty exceptional. Even if you don’t use the time travel capabilities of Redux, the dev tools are still super useful to see what’s going on within your store and to debug issues.
Due to structure easy to persist
By “structure”, I mean the fact that your whole state can be represented by the store’s current state at any given time (single source of truth) so this is all you really need to store when you want to persist things and rehydrate when the app starts, making the problem space much easier to deal with.
This also ties in with the large community. You’re likely not the first one running into a requirement like this, so libraries like redux-persist make it really easy.
Easy to make use of server or web sockets to share state across multiple users / machines
This refers to the way Redux deals with state updates via actions and the fact that everything is predictable. It means that you don’t need to worry about constantly syncing your whole state or store across, all you need to sync are the actions. The clients are then responsible to run them on the current state, which will result in the same final state. And again, you’re not the first one having to deal with this problem 😊
What are we using Redux for?
Some of the use cases I commonly see are:
- prevent prop drilling
- UI state (e.g. themes, tab and toggle states, etc.)
- form data
- API data
- persist and automatically rehydrate state (e.g. local storage)
Again, this is not an exhaustive list of examples, but just some specific use cases I can relate to having used (or still using) Redux to help achieve them.
Prevent prop drilling
This is probably the most common use case, and when you think about it it’s kind of the root motivation for most of the other use cases as well. And it’s absolutely valid - Redux allows you to make data available to deeply nested component trees without having to pass it through all the levels as props. However, this is also the most misunderstood use case in my view.
Since it’s very vague, people constantly use it to claim “you don’t need Redux for this, just use Context” - which is generally true (Context solves very much the same problem), but this statement ignores any further circumstances which might add more requirements and restrictions to your solution.
There are a lot more considerations that should go into the “prevent prop drilling” use case, such as: how often does the data change? How many components rely on the data, how deeply nested is your app , how complex are your individual state slices, how many state slices are there …?
UI state
UI state refers to non static UI values, such as theme variables, tab and toggle states, etc. With these, there are similar considerations to be made: how many components rely on this UI state? Does it need to be persisted or at least kept on a top level independent from the component(s) that use it? Basically, could you even get away with using local state because the state is very isolated to the specific component?
Form data
I think it largely comes from redux's initial popularity that related libraries such as redux-form, dealing with state management for form state, has become so popular as well. It obviously benefited from the whole "redux all the things" movement a year or two ago.
I’m repeating myself here, but the questions you should ask yourself are: how many components actually care about the form state, and are these actually that far apart in the component tree? What benefits do I get from storing the form state in Redux vs. what trade offs am I dealing with?
One common issue with form state in Redux are suboptimal selectors when connecting any components to the store. This becomes especially problematic if you trigger an action on every input change (e.g. on every key stroke for text fields), not only adding a lot of noise to Redux, but also triggering A LOT of unwanted re-renders in your app. While that is not really Redux’s fault, making the store itself simpler can help dealing with and solving these problems.
From my personal experience, at Rexlabs we rarely need the form state for anything else other than the actual form. So, a lot of the benefits we get with Redux don’t really apply to it.
API data
This is probably the most controversial. I personally don’t think Redux is the best place for API data. That being said, I use Redux for API data in pretty much all apps I’m working on. Not because it’s the ideal solution, but mostly because it’s one of the better options.
API data flow is usually pretty isolated; there are not many other state parts that rely on or act upon API actions. Therefore, you don’t really get many benefits from having the data in your store.
Beyond that, Redux is not made for async actions out of the box. It supports them, and there are libraries that help with it, but on its own things can become pretty verbose quickly. On top of that, you run into similar issues as with the form data, where a lot of events are fired, usually at least 2 events per API call. If you have a bunch of API calls for a specific screen, that means a lot of Redux actions, which means a lot of re-renders when selectors are not properly implemented.
The reason why you’d put your API data into Redux is pretty obvious. It’s a handy place to store the data decoupled from your components, which means you can share the data between all your components. You can also easily keep the data when your components unmount, saving future API requests (though keep in mind that this comes with its own problems of cache invalidation and garbage collection in most non-trivial apps, but that’s another story 🙈). You can easily persist the data to make your app work offline if needed. It helps with optimistic updates, treating the store as the source of truth and updating the data on the server in the background (again, potentially helping with offline scenarios).
These are a lot of the benefits you get from using Redux. Depending on your app and your setup, they might easily outweigh the problems and trade offs. If so, good for you - Redux is definitely a solid solution for you. In case they don’t, the question remains what alternatives are there that give you similar benefits without the trade offs?
One of the biggest problems with API data, which to be fair has nothing to do with Redux itself, is loading and error states. Usually your goal is to normalise the API data, to allow you to reuse the data for components with the same or similar requests. Dealing with loading states for multiple consumers for the same data source can easily become tricky. In general, having to store loading and error states on its own can be pretty painful, always giving me the feeling we’re doing something wrong here.
To me, React Suspense seems like the most promising solution (pun intended) to this particular problem, dealing with loading states and, in combination with error boundaries, also error states in a completely new and more intuitive way. Suspense works with cache providers, which ideally keep the normalised data received from the API and can also deal with the concerns of cache invalidation and garbage collection. This comes down to the implementation of the cache provider, neatly consolidating the problem.
Again, your use case might be different, and your setup and team experience might be different - all of which can and should lead to different decisions about what the ideal solution for your specific problem should be.
Persist and rehydrate data
I kind of already hinted at this, but Redux makes persisting state and rehydrating it on initial load of your app fairly easy, providing libraries like redux-persist. However, I wouldn't use the availability of libraries as the main argument (you can easily find similar libraries for local state or context). The core reason why Redux is convenient for state persistence is the core principle of a "single source of truth" mentioned before. This means, that everything you need or want to do regarding persistence and rehydration can be done in one central place. Doing the same with a lot of different local states or contexts can easily grow out of hand.
Again, it obviously depends on what your state actually looks like. If it’s very simple, only covering one or two context providers, doing the same with React Context doesn’t add much if any overhead.
What are the alternatives?
There are loads of alternatives to Redux. And that’s good. Redux solves a very specific problem, which means if your problem is different, you probably should use an alternative solution. Even the creator of Redux famously keep preaching that you might not need Redux - not saying that Redux is useless, but rather that it works for some use cases, while it might not work for others.
The most frequently mentioned “alternatives” seem to be:
- React Local State
- React Context
- React Hooks
- GraphQL and Apollo
- React Suspense
Mostly focusing on the React internal features here. This is another thing that keeps popping up, with people saying that React itself is killing Redux… which they find hilarious for whatever reason 🤷♂.️
React Local State
Often state that ends up in Redux actually doesn’t need to be there. If that is the case, i.e. because the state isn’t shared between multiple components, it’s always a good idea to try and think small before going bigger. Does local state work for your use case? If it does, use it. Not only will it make your state for this particular use case simpler, but it will also make your Redux state smaller (meaning, less complex), helping a lot to keep it sane and maintainable. A win-win situation.
This touches on an unrelated thing I see happening quite a bit: people seem weirdly reluctant to use multiple solutions to deal with different state management use cases and problems. In my opinion, this failure ironically leads to a lot of hacks and workarounds for instances where Redux just doesn’t work that well. It also blows up your store, making it more intimidating and less maintainable. These are the same people who then go out and complain about how complex Redux is 😣.
React Context
This is a weird one, since I feel like there are a lot of misconceptions about it out there. The argument “why use Redux when you can use Context?” seems weird to me. Redux uses Context under the hood. This is like saying “why drive a Tesla when you can drive a car?”. Sure, if a cheaper and simpler car works for you, you should consider buying that instead. But that doesn’t mean that Teslas are generally useless.
By using plain Context without any form of abstraction you lose all the benefits mentioned before, which Redux’ patterns and principles (read: restrictions) enforce. That means your state will likely be less predictable, there won’t be a single source of truth and the debugging experience at scale will potentially suffer.
There are also technical considerations. At its core (in a very simplified view), Redux is basically just a glorified reducer. Especially with the latest useReducer hook, you can absolutely do this with Context without using Redux. But at that stage you're basically re-inventing Redux, so you really should ask yourself what the benefits of that are vs. simply using Redux and build your abstractions on top of that where needed.
Context by itself also isn’t made for frequently changing state, especially when the state is a more complex object and not all components that consume it care about all of it. It isn’t optimised to stop unnecessary re-renders etc, which Redux is solving for you by pulling the store (and the logic for determining whether or not a component connected to the store needs to re-render) outside of the React tree.
With all the above being said, Context is absolutely a valid alternative to a lot of use cases people currently use Redux for, and if you can pull out some of your Redux state into separate contexts to make your Redux state simpler and easier to grasp, you should do so - as long as you are aware of what this will mean in regards to functionality you’ll loose. But it definitely doesn’t (and is not even trying to) cover all scenarios Redux is used for.
React Hooks
Well, just no. Hooks by themselves have nothing to do with the problems Redux tries to solve. I don’t really know where this misconception comes from but I assume it stems from the useReducer hook, which allows you to use the reducer pattern in components easily for local state. While reducers were made popular by Redux, the library has in no way invented it and never claimed so. Hooks by themselves won't allow you to share this local state or get any of the other benefits Redux offers. So again, no, Hooks are not an alternative to Redux.
So I guess the myth that hooks kill Redux comes from the fact that you can use useReducer in combination with Context, in which case see above. Yes, this is an alternative, but only for a specific subset of problems. If Context solves your problem, Redux wasn't the best choice even before, and you likely just picked it because of lack of alternatives (with legacy context being actively discouraged by the React team itself) or because of the hype in the community when Redux came out.
GraphQL and Apollo
I won’t say too much about GraphQL and Apollo, mainly because I’m not actively using either and therefore my experience is very limited. What I do want to say is: yes, libraries like Apollo are definitely a good alternative to Redux when it comes to API data! So, again, this alternative is only suitable for a specific subset of problems.
As stated before, placing your API data in Redux is likely not ideal. So, any solution that treats that separate problem on its own seems great. But that still leaves us with a lot of other non-API related use cases that justify the use of Redux. If you have none of those, sure, you don’t need Redux. But that doesn’t mean the same goes for everyone else.
React Suspense
Similar to GraphQL this just addresses the fact that Redux was never ideal for common data fetching scenarios. As mentioned, the way Suspense approaches async data handling in React is revolutionary and will definitely change how we think about data flows in our apps, but again, this only covers the API use case. So alternative, yes… complete replacement, likely not.
Busting some of the myths around Redux
There are a lot of myths flying around about Redux. Here are just some of the most frequent examples I often hear.
Redux is verbose
Well, yes, but so is everything at scale if you don’t abstract common patterns out. To get started, Redux is actually pretty compact, way more so than public opinion will make you believe lately.
As mentioned in the beginning, Redux was originally introduced to reduce the boilerplate needed to implement flux like state management, and it did a really good job for that.
If you find Redux too verbose, it’s either because you didn’t build abstractions where it would make sense, or it’s because your application doesn’t work well with flux like state management to begin with. Either way that’s hardly Redux’s fault.
Redux is slow
No, it isn’t. Redux itself hardly does anything really. If it is slow for you, it’s more likely because your implementation is slow. Probably because your selectors are expensive or even faulty, causing your app to constantly re-render unnecessarily. Again, not Redux’s fault.
On that point, another myth “Redux is slower than plain Context” is simply wrong. Redux does a lot to keep the logic that determines whether or not a component needs to re-render on state changes outside of React, meaning React doesn’t even get involved at all if the component doesn’t need to change. It can’t get much faster than that.
For more details on this, I highly recommend watching Mark Erikson’s amazing talk on it.
Redux blows up your bundle size
Redux comes at a bundle size of ~2.6KB, even React Redux only comes with ~5.6KB. Does that really “blow up” your bundle size? If so, good for you and you should absolutely look for alternatives that do what you need with less footprint.
Realistically, if you use Redux to its full extent, any alternative, including self written solutions based on Context and useReducer, will likely lead to more code than the above. Especially since they then need to be manually optimised for performance and maintainability, tests written, etc. So not only will it still "blow up" your bundle size, you now also have to maintain it yourself.
You don’t need Redux
Maybe YOU don’t need Redux, and that is great. If you can solve all your problems better by just using local state and Context, awesome. You should absolutely run yarn remove redux react-redux as soon as possible.
This doesn’t mean the same can be said for everyone else. You don’t know what other peoples problems are, why they are using Redux and how it works in their use case and with their requirements and restrictions.
So what should I use?
If you’re really expecting an answer here, you either haven’t been paying attention or you skipped everything written above.
I can’t stress this enough: choose whatever works best for you and your team. Please don’t go from there and start preaching to others that they have to use the same solution you did. Rather go out and explain to the world why your solution worked so well for your specific use case. Help people make an informed decision around what to use for themselves.
This also works the other way round. Use the community to gather information about what solutions work for which problems. Don’t strive for approval in the community, especially if they don’t relate to the problem you’re trying to solve. Whatever works for you and your team is, by definition, a good solution.
This article is heavily based on a talk I gave at the Brisbane React meetup. Check out the github repo for some code examples and the slides: https://github.com/julianburr/talk-redux-is-not-dead
