How To Escape Hype And Unlock The True Value Of Data Science

Who should read this?
Entry level or Intermediate Data Scientists or Newbie Analysts or Enthusiasts or Business Leaders looking to implement Data Science in their processes.What will you get?
You will be able to decode the various nuances of the field, start a few Data Science projects in your organization and possibly work towards establishing a strong footprint in the industry as either practitioners or evangelists.How will this really long story help you?
You will be able to understand the taxonomy of the industry, unravel the devil in the details, know how to approach data science projects, get a pulse of the progress made and separate signal from noise.
You should have heard a lot by now that with abundance of data, computing power and other drivers, we are back from the AI winter, and are in a bright new age of possibilities.
Again, the likes of Stephen Hawking and Elon Musk have warned on the impending doom to humanity that might be caused by a Skynet-like group-mind and artificial general intelligence system, in stark contrast to today’s sweet talking virtual assistants.

Regardless of which camp you are on, I would like to clarify that all this talk and hype has shadowed out the clear-cut benefits of Data Science and Analytics which can be realized today or in the immediate future.
Moreover, the hype has overflown into all related fields, out of which one is Data Science, where the confusion, and the risks of wrong decision making that ensues from it, is putting a huge dark cloud (pun intended) on the future applications of such technologies within the enterprise.
If you observe carefully, a lot of hype is not related 1:1 with Data Science but have has come from fluff that people have spread about the current state of AI. That’s why I started with the term — AI.
Rather than just talking about AI’s wonders or saying that it’s all marketing , let’s address the confusions and have a better understanding of what all this really means, and how any organization can drive value by efficiently approaching data science projects.
I believe there’s a lot of noise in our field and separating it from signal has started to become a real challenge. Firstly, just think of the confusion that still rests among all of us about the terms themselves- AI, ML, DL & Data Science.
Demystifying the semantics
Our terms have a lot of pixie dust over them. They inspire people to dream of a world beyond imagination and advance humanity, but at the same time lead to an increasing hype bubble, misrepresentation and improper communication amongst industry professionals.
So, let’s start by clearing out the semantics. What exactly is:
Data Science — Simply put, Data Science is about extracting knowledge from data. Thee underlying science relies heavily on Mathematics, Statistics and Optimization.

I view data science as a scientific discipline(like any other e.g. Biology), albeit a bit pseudo. There are others who believe there is no science at all in it. Well, let’s just move on, considering we can agree to disagree if we can model the digital world as a projection of the natural and physical world. Data Science encompasses a set of ideas, theories, methods, and tools and experimentation is common.
The practice of data science involves marrying code with data to build models. This includes the important and dominant initial steps of data acquisition, cleansing, and preparation. Data science models usually make predictions, prescribe best practices and explain or describe our domain for us.

It can be difficult to differentiate Data Science from Statistical Analysis.
Statistical analysis is based on samples, controlled experiments, probabilities, and distributions. It usually answers questions about likelihood of events or the validity of statements. It uses different algorithms like t-test, chi-square, ANOVA, DOE, response surface designs, etc.
A key pivot here might be that Data Science models are applied in production to take in new input settings by the thousands, over time, in batches or streams, and predict responses. This definition is not fool-proof but I hope we captured the essence here.
Machine Learning — ML is an archaic term and goes back to 1950s.Yes, that far! It is a toolset or a class of techniques for building the models mentioned above.
Instead of humans explicitly programming the logic for the model to learn, machine learning enables computers to generate (or learn) models on their own. This is done by processing an initial set of data, discovering complex hidden patterns in that, and capturing those patterns in a model so they can be applied later to a new dataset in order to make predictions or give explanations. The data sets may be labelled (that enables supervision for the algorithm) or unlabelled and thus, machine learning is mostly divided into three categories by learning method— Supervised, Unsupervised and Semi-Supervised.

The “magic” behind this process of automatically discovering patterns lies in the algorithms. Algorithms are the workhorses of machine learning. Common machine learning algorithms include the various neural network approaches, clustering techniques, gradient boosting machines, random forests, and many more.
Deep learning- DL is a class of machine learning algorithms that uses neural networks with more than one hidden layer. It is a subset of Machine Learning that creates knowledge from multiple layers of information processing.

Deep Learning solves a basic problem in representation (or feature)learning by making use of representations that can be expressed in terms of other, simpler representations. The way we represent the world enables the computer to build complex concepts out of simple concepts.

Deep learning can be applied to a variety of use cases including image recognition, chat assistants, and recommender systems. For example, Google Speech, Google Photos, and Google Search are some of the original solutions built using deep learning. Here are some good places to get started on deep learning.
Artificial Intelligence- AI is probably the most broad and abused term of our times leading many business leaders to state that it actually doesn’t exist and we use it for the purpose of references. This might be our “emperor has no clothes” moment. We have the ambiguity and the resulting hype that comes from the promise of something new and unknown.

Might be, AI is a category of systems which have the defining characteristic that they are comparable to humans in the degree of autonomy and scope of operation.

If I am allowed to extend my analogy then, if data science is like biology and machine learning is like genetic engineering, AI is like disease resistance.
It’s the end result, a set of solutions or systems that we are striving to create through the application of machine learning (often deep learning) and other techniques.
Busta-Chimes — One by One
People use AI much too often. Marketers blast it all around the park adding to the hype. Most of the “AI Solutions” actually just lie on the slides of presenters. Quoting Veronica from Better Off Ted — ““products are for people who don’t have presentations”.
- Deep learning is not AI. It is one technique that can be used as part of an overall AI solution.
- Most data science projects are not making AI solutions. A customer churn model you have is not an AI solution, no matter if it uses DL or logistic regression.
- A self-driving car might be an AI solution. It is a solution that operates with complexity and autonomy that approaches what humans are capable of doing.
There are many cryptic statements floating around the market which make it difficult for someone who isn’t deep into the field to figure out exactly what is going on under the hood. Let’s look at some then:

Pickup-Line: “Our goal is to make our processes AI-driven within 4 years.”
True-Speak: “We would want to have some machine learning models in production within 4 years.”
Pickup-Line: “We need to make ourselves better at machine learning before we can think of investing in deep learning man!”
True-Speak: “We need to train our staff on basic data science principles before we can try our hands at some deep learning approaches to solving our problems.”
Pickup-Line: “We use AI to predict any fraudulent scenarios so that our users can spend with peace.”
True-Speak: “The logistic regression model we used to detect and predict fraud has been working well for years and we can now consider it to be ‘mature’.”
Pickup-Line: “One study found that enterprises who invest in AI see a 20% boost in their revenues.”
True-speak: “Enterprises that make use of predictive models in their processes see a 20% revenue boost.”
This ambiguity of taxonomy can be especially damaging in the early planning phases of a data science project when a cross-functional team assembles to articulate goals and design the end solution.
According to a recent Gartner study, 85% of data science projects fail.
This confusion and hype is also causing the following:
- “Masters of the Universe”-level expectations from Data Scientists
- Wrong decision making due to over-expectation from the “magic” of Data Science
- Mistrust in the community
Where’s the hype exactly coming from?
Hype is originating from multiple sources:
Unsupported claims of superiority — “The leading text classification…”, “the most accurate clustering algorithm…” — No evidence, no explanation whatsoever. The reality might well be that there is entire sea of algorithms that are just as good.
Exaggeration about what the algorithm does — For example if a neural network is used, you might read about how the approach is similar to the workings of the human brain , along with some fancy illustrations. A sales presentation to individual with no Data Science background might seem like something from a sci-fi movie. Unfortunately, it might also raise expectations to sci-fi levels.
Unrepresentative results and use cases — Algorithms tailored to a specific data set and a specific scenario are advertised as broadly applicable solutions.
Unrealistic expectations are generated and the reality of the field is intentionally misrepresented along the way to make a sale. However it is essential to remember that what will make a sale needn’t essentially scale.
Navigating around the Hype

Organizations that buy into the hype are turned off from investing any further into Data Science, once reality sets in. Many argue that reality has already surfaced its ugly face. However, there are many examples of businesses taking the bait. The question that arises then is how do we navigate around this hype.
So, the research community does assemble around benchmark datasets that essentially allow for a commonly accepted standard over which improvements can be measured. Such datasets might not be entirely representative of the real-world, but can be a significant starting step to organizations busting out their budgets and ultimately conceding that Data Science is actually not something that they are ready for, or that it is of no use to their organizations.
Platforms with benchmarking datasets for every kind of problem can be privately or community driven, and can provide transparency in at least the vendor selection step, or the step where an algorithm’s precision needs to be tested, before pouring in money and time over it. Such initiatives can validate claims of superiority.
The second thing might be to set proper expectations which are far away from overly optimistic daydreams, of having a shiny orb-like CXO brain placed in a meeting room, talking to you like an oracle, and taking decisions.

Thirdly, whenever someone talks to you about how their algorithms are changing the world, ask them questions like:
- What are the exact scenarios you tested it on?
- What are the data sets that were used?
- What was the sample size and how did you collect it?
- How do you know your models aren’t biased or overfitted?
This means acquainting yourself with the fundamentals of Machine Learning and Data Science so that you know how to ask the right questions to uncover a high level idea of what’s under the hood and how you will benefit. There are a lot of courses available for the same, and this mind-map blog might be a good place to make a checklist of things you would like to know for identifying opportunities for your organization.
So, now that we know how we can navigate around the hype and focus on deriving business value through the use of what is available today, let’s start discussing the approach for doing the same.

How to go about Data Science Projects?
First and foremost, if you are just starting out on your data science journey, focus on entry level techniques against real problems, to see whether they are able to give you a considerable uplift in efficiency.
An applied example would be to start with simple things like K-means Clustering, SVMs, Random Forests, Decision Trees and Ensembling rather than directly jumping into Deep Reinforcement Learning, etc. although the latter might be more attractive.
Next, focus only on problem solving instead of solution glamorization and approach your case in SMART phases (Specific, Manageable, Attainable, Relevant and Time based).
As a key stakeholder, you should to understand how the Data Science Model creation cycle works and how can you efficiently utilize resources, else you are setting yourself up for failure. As a budding data scientist, you should know what’s expected from you in terms of key roles and responsibilities.
Below is a diagram from Gartner which quite comprehensively captures the process of developing, deploying, maintaining and improving models:

As is evident, the cycle goes through the initial steps of data collection and creation, munging and creating frameworks for continuous ingestion. Then, we do some exploratory data analysis to derive key insights that can help us engineer more features over the existing set of features and train our machines to discover patterns useful to predict on test data sets. Typically, an 80:20 partition of train data to test data is preferred, which may be adjusted in some specific scenarios.
Once we have our models ready, it’s time to put them in production alongside existing business process, measure value and optimize. This goes on and on, and results in improved performance over time.
Now, a data scientist needs to be involved in all the stages of this cycle as they have to understand business problems, understand the kind of data needed, what tools and technologies are needed to create the models, test and deliver.
However, from an operational perspective you would want them to spend majority of their time in the exploration, model building and testing. So, we should be able to fill the gaps with other resources who can handle different parts of the cycle.

The data scientists should be able to guide the Data Engineer, Domain Experts and Developers, and over time transfer their knowledge to up-skill analytically-driven people to build a strong Data Science team. This team can leverage and improve built models to consistently deliver value.
I am very concerned about the trend that we, as an organization and mainly the decision makers, rely heavily on the data scientists to do the end to end work. It overwhelms the resources (read a real account of a Data Scientist suffering from Imposter Syndrome), and is not sustainable in the long term.
Along with the critical focus areas of Data Scientists, their involvement in other parts of the cycle should be entirely dependent on the size and strengths of the organization, and the skills of the person. If you are a small team, you might need to split your team in a complementary way so that the Data Scientists are responsible for model creation and deployment, while the others are focused on the business problems, and both teams collaborate on the Data Collection and Creation steps. That said, I would re-iterate that Data Scientists should have an understanding and presence throughout the cycle.
An important advice for a person entering into the field would be to lay out a strong foundation from the start by being well versed in maths, statistics and coding. It is not essential that you come from a Computer Science or Maths & Computing background. I have seen many exceptional data scientists in my career and on the news who have come from branches such as Mechanical Engineering, Chemical Engineering, Metallurgy and the likes.
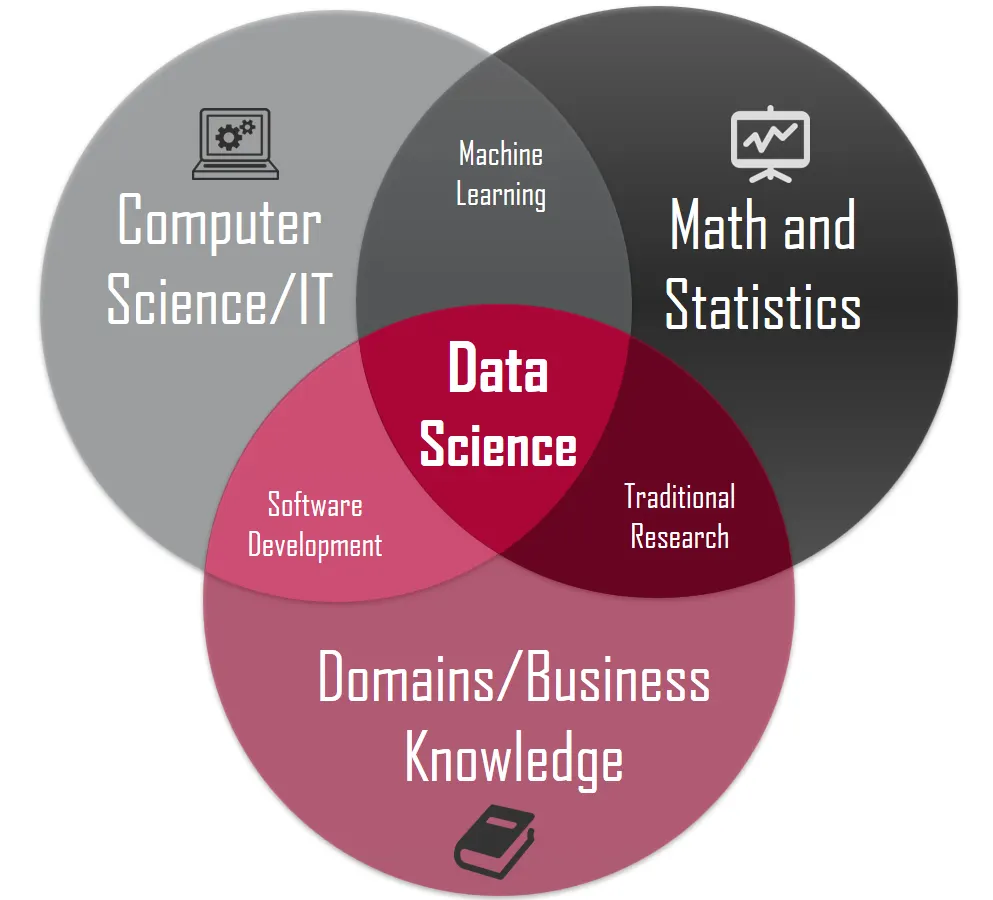
However, to make your bread and butter, and be a long distance runner, the above three disciplines are non-negotiable. You might also want to go through this blog which takes into account the view point of over 30 Data Scientists who work across industries and come from different academic disciplines.
Also, there’s a serious skills crisis that is being approached with time where the people who are coming out as Data Scientists are not actually living up to the industry standards.
This is happening mostly because of outdated courses, educational vendors using the hype cycle, exposure to problems that are merely for concept disambiguation or the emerging trend where new talent is less concerned with the fundamentals due to the abundance of platforms that do the math for you, pre-trained models, etc.

We all know that in time, even this field will be commoditized and a lot of the work that is being done by Data Scientists will be automated. However, if you go by that and do not make yourselves comfortable with maths and coding, you won’t be able to customize models to your problems, discern the true meaning of results, and above all, contribute something new to the community.
Original inventions come from original thinkers who know the rules and break them like its art. Others are just consumers.
As per Ernst and Young, 56% of senior “AI professionals” (you should be done with this by now” believed that the lack of qualified AI professionals was the greatest barrier to implementation of AI (again :P) across business operations.
As we look to the future, we must realize that technologies won’t be able to shape our world for the better without talent. In a recent report, Accenture states that if G20 countries are unable to adapt the supply of skills to meet the needs of the new technological era, they risk forgoing up to USD 11.5 trillion in GDP growth over the next 10 years. The “Skills Crisis” could be the next big economic disaster since the “Financial Crisis” of 2008.
Therefore, quality is scarce and extremely expensive, which can only be afforded by companies with deep pockets and the cash flows to endure multiple miserable failures.
From our experience, the first phase of exploration of resources should be distributed across Academia, Core Data Scientists, Citizen Data Scientists who can utilize off-the-shelf Data Science platforms and experts from different consultancies. A significant amount of grooming would also be required but that can be done if we are able to maintain a harmonious balance between the different pools.
In due time, you would want resources with a minimum level of analytical and statistical skills or even some interest in problem solving to join your Data Science group. These resources can be up-skilled by knowledge transfer from existing work and resources. Although, this is a time taking and intensive task, the pitfalls of hiring the wrong people or choosing the wrong partners could be magnanimous.
Organizations can also explore other methods of disrupting existing business with Data Science without taking up the burden of hiring resources. Typically, the common methods we have today are either to Build or Buy or Outsource. The advantages and disadvantages of the same are described below:

- Buy: Such delivery methods are generally faster to market, relatively cost effective and easy to use. However, customizations are difficult and they rarely help up-skill your resources. This is hence unfavourable as a sole delivery model in case your organization has larger plans for the application of data science to business processes.
- Build: Starting from scratch is extremely demanding in terms of resources and costs and is time taking. However, you have a lot more control and can truly transform your workforce to enable a digital revolution in your otganization. With a bit of consulting, you can be more confident of the solution quality specific to your problem as well.
- Outsource: Outsourcing to specialist mid-size and local consultancies, and specialist mid-size technology enterprises has been seen to fare well in terms of granularity of control, costs, time, risk mitigation and quality of solution. Your pool of analysts could collaborate and over time learn Data Science themselves, as most of these consultancies also offer services to train your workforce.
Whatever might be the approach you follow, as torchbearers of the digital transformation process, you should be aware well in advance about the common challenges that come in the way. This also holds true for aspiring data scientists.
Let’s look at some that are known knowns and can be watched out for or completely avoided.

- Scope Creep — A lot of stakeholders get really excited on different possibilities of Data Science and Machine learning and keep on rolling out a lot to the scope without really focusing on implementing one successful project and learning from experience that could benefit other projects.
This leads to having multiple failures and ultimately, sanctions on experimentation.
2. System Issues — A data scientist working in a startup pretty much as a green field and the opportunity to best establish the entire product architecture from scratch, but to fit a machine learning model into a legacy architecture is a lot trickier than what it seems.
You need someone who knows the existing system limitations and is progressive enough to scale up to the level of data scientist, and bring the best possible results to existing tech stack.

This exposes another limitation for data scientists too. They are good with languages like Python, R and my SQL, but not every organization has these applications and databases natively present, so a separate application architecture needs to be put in place, so that data science becomes part of the analytics module in a bigger picture or application architecture.
This is a job for engineering or development team that pretty much every organization has, so rather than putting a data scientist on a pedestal, it’s better to blend them with the rest of the team so that cross-learning can happen.
3. Culture and Territorialism — Whenever you start with Data Science projects, resources might think this is going to cause layoffs as they are not doing good work and technology is here to replace them.
Even in mature data driven organizations, certain users using certain tools that have served the purpose so far can give demonstrate a lot of inertia in adopting new technologies. So, building that case for change and transformation and educating the workforce could lead them to enthusiastically contribute to the change and hence seamlessly transform business processes.
4. Siloing of Resources — Many companies are creating new departments of data analytics, which I feel will again end up creating silos within the organization. Data science need to be a horizontal service for all verticals rather than being a vertical of its own.

Typically we see that some organizations either put Data Scientists only in the Business team or only in the IT team. A better way would be having entry level data scientists in different Verticals or LOBs and the IT department, and having experienced ones in a Data Science Lab that collaborates with all the verticals and the IT department, responsible for delivering solutions and up-skilling.
5. Bias — How do we ensure that the models we make in our lab are ‘fair’ in the real world. It is an inherent tendency to assume that the models will make rationale decisions as they are based on math rather than human judgements. However, that’s never the case.

Bias can come from the way data was collected, or various decisions and assumptions we might make while developing models- conscious or unconscious. Although there’s no direct solution to eliminating bias, the most we can do is have an essential framework in place to mitigate it.
6. Data Quality — I can’t stress enough how critical this aspect of your is! There goes the popular adage that must have been quoted a million times by now- ”Garbage in; Garbage out!”. It is painstaking yet paramount to achieving consistent and true results.

Data should be correct, suited to downstream processing, unbiased and should appropriately represent the entire range of inputs you wish to develop your models for. Poor models resulting out of poor data would lead to mistrust, loss of revenue and reputational damage, among other troubles.
7. Underfitting/Overfitting — A model is said to be good if it generalizes to any new input data, to make proper predictions on data the model has never seen. Underfitting happens when the model fails to capture the underlying trend in the data. This happens when we have less data in comparison to the features or variables we have, or if we are trying to make linear models on non-linear data. The model generated doesn’t have much learning from the data and will lead to inaccurate results.

Overfitting happens when model is too flexible to learn from almost every data point in the training set and thus get close to all of them. This results in the model learning even from noise. So, instead of learning the ‘relationship’, our model memorizes training data. It will not generalize well to test data or new data, and hence would be a bad model. Several methods like regularization, validation and ensemble methods are used for solving the overfitting problem, while underfitting can be tackled by using more data, reducing features, etc.
Here’s a link to a more extensive list of the reasons why a project or team fails:
http://www.acheronanalytics.com/2/post/2017/07/top-32-reasons-data-science-projects-fail.html
So, by now, you should be clear on how you should look beyond the smoke and mirrors of data science by navigating around the hype and deriving value from the what’s available in reality.
It’s excruciatingly painful to see the plethora of noise makers in the market who, instead of allowing the market to slowly thrive, are bringing in the risk of making a large bubble which if burst could again put us into cold storage even after coming this far in research and development.
This is harmful in many ways and I would be really glad if some of my inputs help you in exploring the field and saving your organization from burning their fingers.
Human jobs are not going away to robots anywhere soon but are going to slowly transform over time. By 2020, AI will generate 2.3 million jobs, exceeding the 1.8 million that it will supposedly take. Roles will be more creative and specialized and data will help everyone make better decisions. So, it’s better we embrace technology with the idea to augment and not replace work.
Also, these technologies are far from magic although there’s a significant level of black-boxing involved. However, if a vendor can’t explain how their algorithms work on a high level to solve your problem, don’t buy from them. If an instructor is confusing you with the use of hyped terms and providing little substance into the actual math, code, domain understanding and bottlenecks to implementing solutions, don’t learn from them.

In this era of fear, misunderstanding and hype around emerging technologies, the burden is on your shoulders to look through the lies and gather sufficient understanding to use the solutions that are actually useful. It’s not advisable to miss the bus but neither is over-speeding and crashing into a school gate.
I hope you learned some new insights today. Either that, or you are abusing me for wasting your time.
A lot of effort goes into writing out these long form pieces and for the sake of quality, I have restricted it myself to once a month. I generally write on Technology, Growth and Entrepreneurship.
This article will originally be published on Saarthi’s Publication- The Dialogue.
If you’d like to subscribe to our newsletter, please just leave a few details here.

