Performance Delivered a New Way
Authors: John Bruno, Founder and SVP System Engineering and Sriram Dixit, Product Marketing Lead

The Heartbeat of the Cloud
The demands on the modern data center continue to grow exponentially, impacting virtually all aspects of everyday life. We have become dependent on the cloud as it has become an indispensable part of how we work and live. Communication, media and entertainment, commerce, healthcare, education, the list goes on and on, and the need is growing faster than we can power it. The heartbeat of the cloud is the server CPU, which provides the fuel for the growing set of experiences we now depend on every day.
The server CPU has evolved at an incredible pace over the last two decades. Gone are the days of discrete CPUs, northbridges, southbridges, memory controllers, other external I/O and security chips. In today’s modern data center, the SoC (System On A Chip) does it all. It is the central point of coordination for virtually all workloads and the main hub where all the fixed-function accelerators connect, such as AI accelerators, GPUs, network interface controllers, storage devices, etc.
As workloads have grown in breadth and diversity, the right architecture has become a topic of intense debate. Is the workload compute-heavy? If so, which kind, integer or floating-point? Is the workload memory bandwidth limited? Is it I/O limited? What is the maximum allowable power dissipation? What are the physical constraints of the environment? These are some of the questions we continually ask ourselves at NUVIA. We work with our partners and customers to help answer these questions as we look at the workloads of the future and how to deliver them with maximum performance.
As we collect and analyze all these requirements, there is one factor that firmly remains unchanged as a significant metric to solve for: and that is the amount of performance delivered within a tightly controlled power budget. The power budget is a critical component of the Performance per Total Cost of Ownership (TCO) metric that most leading cloud providers use to assess their data center needs. Our focus at NUVIA is to develop an SoC that will deliver industry-leading performance with the highest levels of efficiency, at the same time. To do this, we are creating a server CPU that is built in a new way, with a complete overhaul of the CPU pipeline. Our first-generation CPU, code-named “Phoenix” will be a custom core based on the ARM architecture and central to our “Orion” SoC.
X86 and a walk down memory lane
The modern-day server processor landscape demonstrates the winner takes all aspects of this market. A short stroll down memory lane explains how we got here. Intel dominates in volume shipments and server market share today with its Xeon product line. A contributing factor to their continued leadership position in recent years has been due to the longevity of the “Skylake” CPU microarchitecture, which underpins the latest Xeon offerings in-market.
Intel released the Skylake microarchitecture in 2015, based on their 14nm process node. It is commonplace in the industry that a CPU microarchitecture is typically developed 3–4 years before first customer shipments. What this means is that modern-day Xeons are running with a CPU architecture that is more than eight years old and a process node that is over five years old. This longevity is an unusual phenomenon in an industry where the pace of innovation typically allows an architecture to last for 2–3 years before it is superseded by the next generation. Why and how did this happen? Several factors, including lack of competition and challenges ramping 10nm manufacturing.
For many years, Intel’s primary competitor was AMD. But after delivering a transformational product with its K8 “Hammer” architecture, the company faced challenges for nearly a decade due to a series of uncompetitive products and lost most of the gains it had made versus Intel. Things started to change for AMD in 2017, with the introduction of its new CPU microarchitecture called “Zen.” Zen was a significant CPU redesign which returned AMD to more traditional monolithic cores that closed the single-threaded performance gap with Intel. A new product line code-named “Naples” was launched into the server market and featured the new Zen CPU microarchitecture. As impressive as Zen was, it still failed to make significant inroads in market share. Despite closing the performance gap and having more cores, the AMD solution was still challenged in several single-threaded and multi-threaded workloads. In the server market, performance-per-watt is king, and if you plan to disrupt an incumbent, there needs to be a substantial increase. AMD continued to improve its position with its next-generation 7nm “Rome” server platform with its Zen 2 architecture. The introduction of Rome closed the performance gap further and put AMD in a position to go toe-to-toe with the competition due to an increase in cores at an equivalent TDP. Even with those improvements, AMD hasn’t gained significant market share yet.
A new ARM’s Race in the Data Center
For the last decade, much has been written and talked about the promise of bringing the Arm architecture and instruction set into the data center. Several promising start-ups have come and gone due to lack of performance, infrastructure readiness, and an immature software ecosystem. In the last few years, we have seen these trends begin to change with companies like Amazon, Ampere, and Marvell, delivering a range of commercially viable products into the data center.
The server CPU market share data clearly demonstrates what the market wants today. With X86 solutions claiming most of the market, only a small percentage of niche customers are willing to accept a lower per-core performance, high core count product. Arguably the most successful Arm-based design today is Amazon’s Graviton. Graviton is a captive design, aimed solely for a limited portion of AWS that values cost over performance. While there will likely be additional growth in this area, the heart of the market clearly demands the highest single-thread performance at TDP and the highest all-core performance at TDP. This is the fastest way to improve Performance/TCO for the most demanding hyperscale customers.
A New Way Forward
While these new entrant’s products show improvements, they still fall short of disrupting their X86 incumbents. At NUVIA, we are taking a different approach, with a clean-sheet CPU design that will deliver an elegant balance of performance leadership and power efficiency that maximizes memory bandwidth and core utilization. Our solution does not need to add extraneous cores to try and make up for a single-threaded performance deficit. Also, there would be no need to employ marketing-inflated boost clocks that are not achievable in any real-world applications of server SoCs, due to running into TDP constraints. In real-world scenarios, server SoCs are designed to be heavily loaded to make the best use of the capitalized hardware and allocated power and cooling budgets. The optimal solution is one where a workload finishes in the shortest time possible while consuming the least possible power. NUVIA is designing the Phoenix core to meet these targets. Built around Phoenix is the Orion SoC and hardware infrastructure specified to support peak performance on real cloud workloads without bottlenecks.
What We Tested
One of the best ways to demonstrate the dichotomy between the X86 and ARM solutions and NUVIA’s approach is to look at the performance versus power charts for each of the CPU architectures. An ideal workload will cover a variety of different types of use cases, both integer and floating-point, scalar and vector plus memory, and ensures that most of the power is consumed within the CPU complex. We believe Geekbench 5 is a good starting point, as it consists of a series of modern real-world kernels that include both integer and floating-point workloads. It runs on multiple platforms, including Linux, iOS, Android, and Windows. It also gives us the ability to conduct these tests on commercially available products that represent the best cross-section of the CPUs with the highest performance and best power efficiency within a thermally constrained environment. You may be wondering how we can make the extrapolation from smartphone and client CPU cores to a server core. In our view, there is no meaningful difference. If anything, these environments now deliver incredibly similar characteristics in how they operate. This has significant parallels to how the server landscape has evolved. In our testing, we run Geekbench 5 without the default pauses between subtests to get an accurate power measurement of the active workload.
Table 1: List of devices tested including Intel, AMD, ARM and custom ARM (Apple)
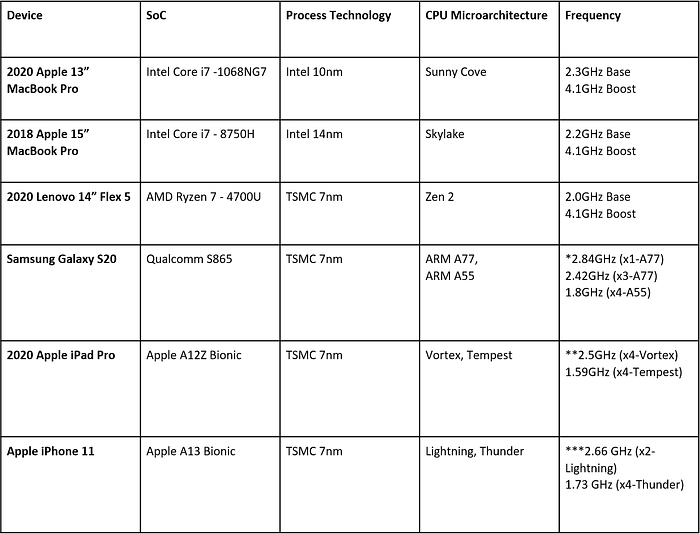
Based on all of the devices tested, a good picture of the current competitive landscape emerges.
CPU Performance Per Watt
The data shows that both AMD and Intel demonstrate higher peak performance than the ARM CPU but at much higher power. The Ice Lake and Zen 2 curves are neck-in-neck with no clear leader. That higher power can be anywhere between 6x to 11x the power of the ARM core comparing peak to peak operating points; however, the X86 solutions are only 40–50% faster. The design philosophies are also clearly contrasted. The x86 CPU cores are designed to run at very high operating points, and the perf/W curve clearly enters a flatline area where every last bit of performance is extracted, at the expense of disproportionately higher power consumption. In stark contrast, the ARM CPU cores have very steep curves.
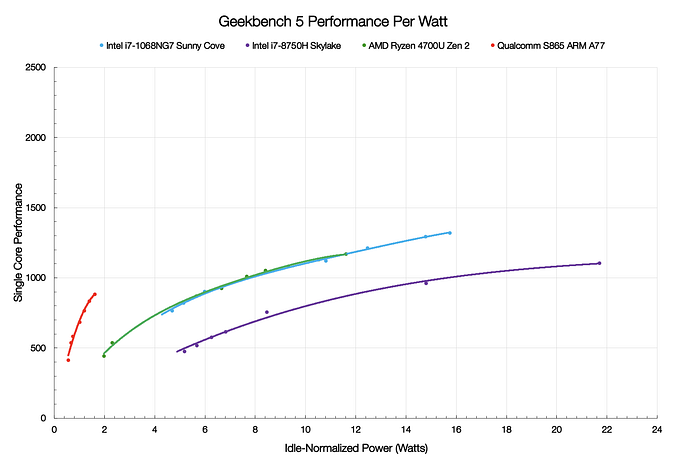
Once the Apple A13 and A12Z curves are added, it becomes clear that a well-designed custom ARM CPU can achieve higher performance than even the best x86 designs and at a much lower power. The combination of high performance at low power is the critical characteristic required to achieve leadership in any SoC that is power constrained.
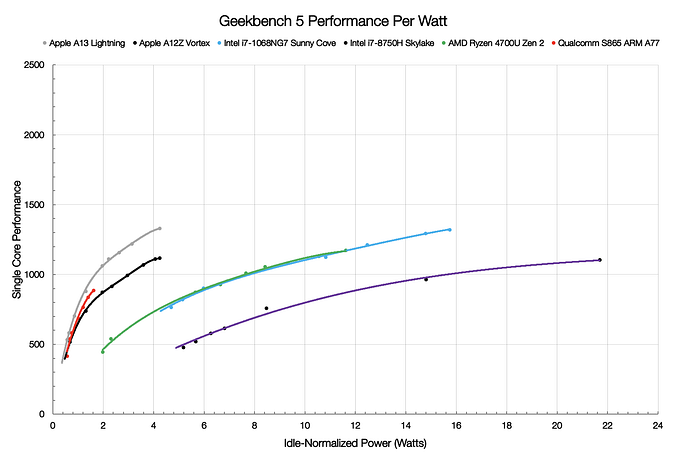
What does all this data mean for the server market? It means a lot. All current and future flagship server SoCs are power constrained, very much like mobile SoCs. This trend is only going to continue as there is a push to integrate even more cores. In addition, the AMD, Intel and ARM client computing cores tested are comparable to their current and future data center products. As core count increases, what is not increasing is the TDP. TDPs are likely going to remain in the 250W — 300W range, which is the maximum power that can be dissipated in an air-cooled environment in a typical datacenter. Hyperscalers and other enterprise data centers still must operate their servers within these TDP limits to optimize the TCO for their data centers. As more cores are added, the power allocation per core shrinks significantly. A rough calculation can be made to determine the high and low bounds of the per-core power allocation in servers. We can assume that future flagship SoCs will have a minimum of 64 cores and a maximum of 128 cores. The TDP range is 250W — 300W, and the power outside of the CPU can range between 10W — 120W depending upon the workload. Taking into consideration these factors, the amount of power that each CPU can be allocated ranges between 1W — 4.5W when heavily utilized, as is the case in a datacenter environment. Drawing a set of vertical bars denoting this power range, it becomes evident why the NUVIA Phoenix CPU core has the potential to reset the bar for the market. No matter which scenario is considered, either unconstrained peak performance or power/thermally constrained performance, Phoenix should have a significant lead. Below is a preview into the planned capabilities of Phoenix, however we have left the upper part of the curve out to fully disclose at a later date. When measured against current products available in-market in the 1W-4.5W power envelope (per core), the Phoenix CPU core performs up to 2X faster than the competition. NUVIA’s Phoenix CPU performance is projected using architectural performance modeling techniques consistent with industry-standard practices on future CPU cores.
Test Methodology
Ideally, one would take a single CPU core, apply a real-world workload, and measure the power within the CPU complex. In practice, this is not possible unless you have the specific in-house tools and proprietary hardware that the designers have available to them to make such a measurement. What we can do is come very close by selecting the systems and workloads carefully. The goal is to isolate the CPU complex’s power and minimize the power consumption that comes from outside of it. In all measurements, we normalized the static idle power to remove constant system-level power taxes, and baseline idles are tuned to be as low as possible. We enabled all power management features, set panels to minimum brightness, turned off radios, and disabled all unneeded features. Batteries are fully charged and not charging while systems are under test. The power is measured at the battery output via the insertion of a high-precision series sense resistor and includes the DC-DC conversion loss of each platform. Typical high-efficiency buck converters used today have similar conversion losses, and therefore this is a more or less common factor amongst all devices.
Now that we’ve made the best effort minimizing power outside of the CPU complex and plan to normalize the static idle power, the last step is to find an “ideal” workload. The devices tested demonstrate the current state of the art from the majority of the major players, both ARM and X86 based platforms. Intel’s Core i7–1068NG7 Ice Lake based SoC is the highest performance variant currently available utilizing the new Sunny Cove CPU microarchitecture, based on Intel’s 10nm process node. We are also assuming that Intel’s next-generation Ice Lake Server will utilize a CPU core built upon a similar base architecture as Sunny Cove. The Intel Core i7–8750H is the last generation of the Skylake microarchitecture and is more closely related to the CPU core shipping in today’s latest Xeon processors. AMD’s Ryzen 4700U utilizes the latest Zen 2 CPU core on TSMC’s 7nm process node. AMD uses the same Zen 2 CPU core within the CCX chiplet in the Rome EPYC family of processors. Qualcomm’s Snapdragon 865 utilizes ARM’s latest A77 as its performance core and is implemented on TSMC’s 7nm process node. The latest announced Ampere Altra and Amazon Graviton 2 both use an ARM N1 CPU core that is more closely related to the older A76, and both are built upon TSMC’s 7nm process node. Lastly, the Apple A13 and A12Z demonstrate the current fastest ARM-based processors, also both built upon TSMC’s 7nm process node.
In Summary
We realize the companies we have measured against in these tests are not standing still and will have new products in the market over the next 18 months. That said, we believe that even with significant performance gains (20%+) with new CPU architectures, we will continue to hold a clear position of leadership in performance-per-watt. By delivering this step-function increase in performance, NUVIA will provide the foundation needed to power the next era of cloud computing. Over the coming weeks and months, we will share more perspectives in the areas of performance-per-joule and SoC architecture for high-performance CPUs

