Empowering Your Django Backend with GraphQL: A Powerful Combination
An overview of GraphQL CRUD operations with Django.

Utilizing cutting-edge technology and tools is essential to stay ahead of the game in today’s continuously changing world of web development. Django has long been a popular option for creating reliable, adaptable, and effective backends for online applications. But what if you could enhance your Django backend even further? That’s where GraphQL comes in.
In this article, we’ll explore the powerful combination of Django and GraphQL and how they can take your web development projects to the next level.
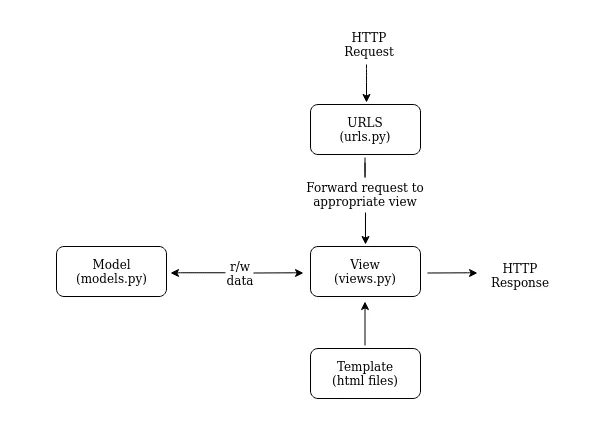
Understanding Django and its Benefits
Before we delve into GraphQL, let’s briefly introduce Django and highlight its key benefits. Django is a high-level Python web framework renowned for its simplicity, scalability, and rapid development capabilities. It follows the Model-View-Template (MVT) architectural pattern and promotes code re-usability and maintainability. Django’s batteries-included approach provides an array of built-in tools and features, making it an excellent choice for developing web applications of all sizes.
Introducing GraphQL
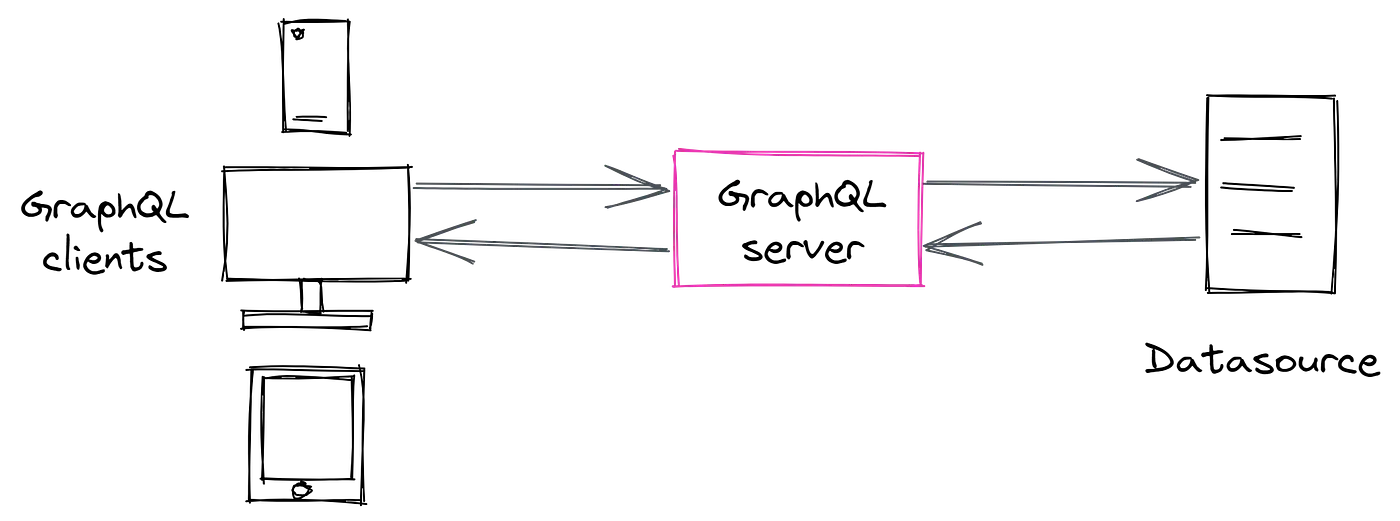
GraphQL is a query language for APIs and a runtime for executing those queries with existing data. It was developed by Facebook to address the limitations of traditional RESTful APIs. GraphQL offers a more efficient and flexible approach to data fetching by allowing clients to specify the exact data they need. Instead of multiple REST endpoints returning fixed data structures, GraphQL enables clients to retrieve multiple resources and their relationships in a single request.
Benefits of Combining Django and GraphQL
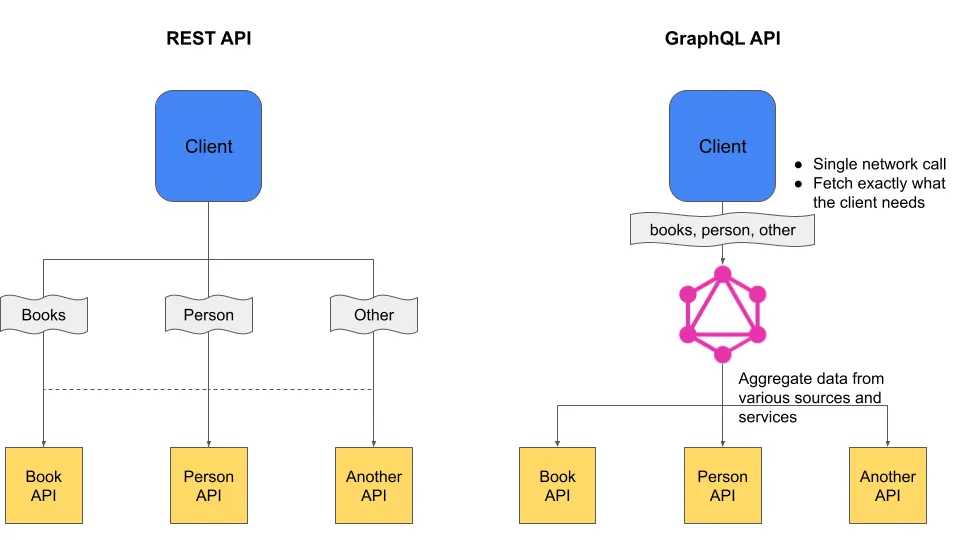
- Flexible Data Fetching: One of the significant advantages of GraphQL is its ability to eliminate over-fetching and under-fetching of data. With GraphQL, clients can precisely define the required data, reducing the payload size and network round trips. This flexibility empowers frontend developers to retrieve only the necessary information, leading to improved performance and better user experiences.
- Reduced Network Requests: Traditional REST APIs often require multiple requests to retrieve related data. In contrast, GraphQL allows clients to retrieve interconnected resources in a single request, eliminating the need for subsequent calls. This reduces network overhead and improves application responsiveness.
- Declarative Nature: GraphQL embraces a declarative syntax, enabling clients to express their data requirements clearly. Clients can request specific fields, filter data, paginate results, and even define custom resolvers. This declarative nature simplifies frontend development and reduces the dependency on backend changes.
- Rapid Iteration and Versioning: With traditional RESTful APIs, introducing changes to the data structure often necessitates versioning endpoints, leading to maintenance challenges. GraphQL’s type system and introspection capabilities allow for seamless iteration and evolution of the API without breaking existing clients. This inherent flexibility enables rapid development and quicker deployment of new features.
Building Blocks for GraphQL
- Schema: A schema in GraphQL is a collection of types that define the structure and behavior of the GraphQL API. It serves as a contract between the client and the server, specifying what operations can be performed and what data can be requested. The schema defines the available types, queries, mutations, and subscriptions that clients can use to interact with the API.
- Query: In GraphQL, a query is a read operation that allows clients to request specific data from the server. Queries are defined within the schema and serve as a way for clients to fetch data from the server. Clients have the ability to specify the fields they want to retrieve, including nested relationships and any necessary arguments for filtering or sorting the data. In response, the server provides the requested data, following the structure defined in the query.
- Mutation: In GraphQL, a mutation is used to modify data on the server. Unlike queries, which are limited to read-only operations, mutations allow clients to create, update, or delete data. The schema defines the mutations, which often include input arguments that specify the data to be modified. Clients can execute mutations to perform actions that affect the server’s state, such as creating a new user or updating an existing record.
- Subscription: Subscriptions in GraphQL enable real-time communication between clients and servers by establishing an ongoing connection. Unlike queries and mutations, which are request-response-based, subscriptions allow clients to subscribe to specific events or data changes. When the subscribed event or data changes, the server promptly sends the updated information to the subscribed clients. Subscriptions are useful for building real-time features like live chat, notifications, or collaborative applications.
Implementing Django with GraphQL
To integrate Django and GraphQL, you can use a variety of libraries and tools. Let’s explore how you can combine Django and GraphQL using Graphene library.
pip install django graphene-djangoInitiate Django Project and applications inside Project Folder
django-admin startproject core
python manage.py startapp blogAdd installed and local apps to settings
# core/settings.py
INSTALLED_APPS = [
"django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.messages",
"django.contrib.staticfiles",
# local_apps
"blog.apps.BlogConfig",
# installed_apps
"graphene_django",
]Next, define your Django models. For instance, let’s consider our blog application consists ofPost and Author models
# blog/models.py
from django.db import models
class Author(models.Model):
name = models.CharField(max_length=100)
# ... other fields
def __str__(self):
return self.name
class Post(models.Model):
title = models.CharField(max_length=100)
content = models.TextField()
author = models.ForeignKey(Author, on_delete=models.CASCADE)
# ... other fields
def __str__(self):
return self.titleCreate GraphQL schema and resolvers using graphene_django for blog application
# blog/schema.py
import graphene
from graphene_django import DjangoObjectType
from .models import Author, Post
class PostType(DjangoObjectType):
class Meta:
model = Post
fields = "__all__"
class AuthorType(DjangoObjectType):
class Meta:
model = Author
fields = "__all__"
class CreatePost(graphene.Mutation):
class Arguments:
title = graphene.String(required=True)
content = graphene.String(required=True)
author_id = graphene.ID(required=True)
post = graphene.Field(PostType)
def mutate(self, info, title, content, author_id):
"""
The mutate function is the function that will be called when a client
makes a request to this mutation. It takes in four arguments:
self, info, title and content. The first two are required by all mutations;
the last two are the arguments we defined in our CreatePostInput class.
:param self: Access the object's attributes and methods
:param info: Access the context of the request
:param title: Create a new post with the title provided
:param content: Pass the content of the post
:param author_id: Get the author object from the database
:return: A createpost object
"""
author = Author.objects.get(pk=author_id)
post = Post(title=title, content=content, author=author)
post.save()
return CreatePost(post=post)
class UpdatePost(graphene.Mutation):
class Arguments:
id = graphene.ID(required=True)
title = graphene.String()
content = graphene.String()
post = graphene.Field(PostType)
def mutate(self, info, id, title=None, content=None):
"""
The mutate function is the function that will be called when a client
calls this mutation. It takes in four arguments: self, info, id and title.
The first two are required by all mutations and the last two are specific to this mutation.
The self argument refers to the class itself (UpdatePost) while info contains information about
the query context such as authentication credentials or access control lists.
:param self: Pass the instance of the class
:param info: Access the context of the request
:param id: Find the post we want to update
:param title: Update the title of a post
:param content: Update the content of a post
:return: An instance of the updatepost class, which is a subclass of mutation
"""
try:
post = Post.objects.get(pk=id)
except Post.DoesNotExist:
raise Exception("Post not found")
if title is not None:
post.title = title
if content is not None:
post.content = content
post.save()
return UpdatePost(post=post)
class DeletePost(graphene.Mutation):
class Arguments:
id = graphene.ID(required=True)
success = graphene.Boolean()
def mutate(self, info, id):
"""
The mutate function is the function that will be called when a client
calls this mutation. It takes in four arguments: self, info, id. The first
argument is the object itself (the class instance). The second argument is
information about the query context and user making this request. We don't
need to use it here so we'll just pass it along as-is to our model method.
The third argument is an ID of a post we want to delete.
:param self: Represent the instance of the class
:param info: Access the context of the query
:param id: Find the post that is to be deleted
:return: A deletepost object, which is the return type of the mutation
"""
try:
post = Post.objects.get(pk=id)
except Post.DoesNotExist:
raise Exception("Post not found")
post.delete()
return DeletePost(success=True)
class Query(graphene.ObjectType):
posts = graphene.List(PostType)
authors = graphene.List(AuthorType)
def resolve_posts(self, info):
"""
The resolve_posts function is a resolver. It’s responsible for retrieving the posts from the database and returning them to GraphQL.
:param self: Refer to the current instance of a class
:param info: Pass along the context of the query
:return: All post objects from the database
"""
return Post.objects.all()
def resolve_authors(self, info):
"""
The resolve_authors function is a resolver. It’s responsible for retrieving the data that will be returned as part of an execution result.
:param self: Pass the instance of the object to be used
:param info: Pass information about the query to the resolver
:return: A list of all the authors in the database
"""
return Author.objects.all()
class Mutation(graphene.ObjectType):
create_post = CreatePost.Field()
update_post = UpdatePost.Field()
delete_post = DeletePost.Field()
schema = graphene.Schema(query=Query, mutation=Mutation)Now, let’s register our schema and resolver from the blog application to the project root
# core/schema.py
import graphene
import blog.schema
class Query(blog.schema.Query, graphene.ObjectType):
# Combine the queries from different apps
pass
class Mutation(blog.schema.Mutation, graphene.ObjectType):
# Combine the mutations from different apps
pass
schema = graphene.Schema(query=Query, mutation=Mutation)Finally, wire up GraphQL with Django by integrating GraphQL route inside URLs file
# core/urls.py
"""
URL configuration for core project.
The `urlpatterns` list routes URLs to views. For more information please see:
https://docs.djangoproject.com/en/4.2/topics/http/urls/
Examples:
Function views
1. Add an import: from my_app import views
2. Add a URL to urlpatterns: path('', views.home, name='home')
Class-based views
1. Add an import: from other_app.views import Home
2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')
Including another URLconf
1. Import the include() function: from django.urls import include, path
2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))
"""
from django.contrib import admin
from django.urls import include, path
from graphene_django.views import GraphQLView
from .schema import schema
urlpatterns = [
path("admin/", admin.site.urls),
path("graphql/", GraphQLView.as_view(graphiql=True, schema=schema)),
]That’s it! Your Django backend is now integrated with GraphQL. Let’s test our GraphQL endpoint by navigating to http://127.0.0.1:8000/graphql/. Once there, you will be able to see GraphiQL interface.

Let’s make our first query to list all Post Titles (assuming you have already added some data in the database)
query{
posts{
title
}
}Response:

To view all fields of the Post, including Author fields, you can write a query like:
query{
posts{
title,
content,
author{
id,
name
}
}
}Response:

Let’s test our Create Post Mutation (assuming you have an author with id=1)
mutation{
createPost(
title:"Test Post from GraphQL",
content:"Added From GraphiQL Interface",
authorId:1
)
{
post{
id
}
}
}Response:

To update a post with id = 6,
mutation{
updatePost(id:6, title:"Post Updated from GraphQL"){
post{
id,
title,
content
}
}
}Response:

Finally, let’s delete the post with id = 6
mutation{
deletePost(id:6){
success
}
}Response:

Things to Take Care of While Implementing GraphQL
- Carefully Design Your Schema: The schema is critical to your GraphQL implementation. Take the time to design a well-structured schema that reflects your data model and aligns with your application’s requirements. Carefully define types, relationships, and fields to ensure efficient and intuitive data retrieval.
- Performance Considerations: GraphQL provides a flexible and powerful querying mechanism, but it’s essential to consider performance implications. Be mindful of over-fetching or under-fetching data, as it can impact response times and network bandwidth. Implement data loaders or batch processing techniques to optimize database queries and prevent N+1 query issues.
- Caching Strategies: GraphQL responses are typically dynamic and specific to each query. Implementing caching mechanisms can improve overall performance by caching frequently accessed data or utilizing field-level caching techniques. Evaluate different caching strategies based on your application’s requirements.
- Security Measures: GraphQL APIs are susceptible to common web application security vulnerabilities such as injection attacks, authentication issues, and excessive data exposure. Implement proper security measures like input validation, authentication and authorization mechanisms, rate limiting, and protection of sensitive data. Additionally, consider implementing security best practices specific to GraphQL, such as depth limiting or query cost analysis.
- Documentation: With the flexibility of GraphQL, providing comprehensive and up-to-date documentation becomes crucial. Document your API schema, including types, fields, and their purpose. Consider using tools like GraphiQL or GraphQL Playground, which provide an interactive documentation experience for clients.
Disadvantages of GraphQL:
- Increased Complexity: GraphQL introduces additional complexity compared to traditional REST APIs. Designing and maintaining a GraphQL schema requires careful planning and consideration of data models, relationships, and resolvers. Additionally, understanding and implementing advanced GraphQL features like subscriptions can add complexity to the development process.
- Learning Curve: While GraphQL offers significant benefits, it also requires developers to learn a new query language and the intricacies of the GraphQL ecosystem. There may be a learning curve for developers unfamiliar with GraphQL concepts, tools, and best practices.
- Caching Challenges: Due to the dynamic nature of GraphQL queries, implementing effective caching strategies can be more challenging than REST APIs. Proper caching requires careful consideration of the cache invalidation mechanisms and managing the complexity of caching granular data.
- Potential Over-fetching: GraphQL allows clients to specify the exact data they need, but it’s also possible for clients to unintentionally over-fetch data by requesting unnecessary fields. Without proper query optimization and awareness, over-fetching can impact performance and consume unnecessary bandwidth.
- Lack of Standardization: Unlike REST, which has well-established conventions and standards, GraphQL is relatively new and lacks standardized practices in some areas. This may lead to inconsistencies across different GraphQL implementations or libraries, making it challenging to maintain and collaborate on larger projects.
Key Learnings
- Django and GraphQL: Django is a powerful Python web framework that provides a solid foundation for building web applications. GraphQL is a query language for APIs that enables efficient data retrieval and allows clients to specify the exact data they need.
- Graphene: Graphene is a Python library that integrates GraphQL with Django, making it easy to build GraphQL APIs using Django models and resolvers.
- GraphQL Schema: The GraphQL schema defines the structure and behavior of your API. By defining types, queries, and mutations in the schema, you can expose the available operations to clients.
- Resolver Functions: Resolver functions are responsible for fetching the data requested by the client in GraphQL queries and mutations. They interact with the database or other data sources to retrieve and manipulate it.
Conclusion
In this article, we delved into the implementation of CRUD operations with Django + GraphQL using Graphene. By combining Django’s models with Graphene’s types and resolvers, we successfully built a flexible & robust API.
You can find the source code of this article here.
Thank you so much for investing your valuable time in reading this article!
Here’s what you can do next:
Give 👏 claps on the article and follow the author for more insightful stories.
Read 📚 more valuable content pieces in Simform Engineering Publication.
