ACM ICMR 2017 in “Little Paris”

ACM ICMR is the premier International Conference on Multimedia Retrieval, and from 2011 it “illuminates the state of the arts in multimedia retrieval” [more].
This year, ICMR was in an wonderful location: Bucharest, Romania also known as “Little Paris”. This was the most prestigious conference in multimedia ever organised in Romania, and the chairs (Bogdan Ionescu and Nicu Sebe) and all of us were very happy to contribute to foster the scientific activity in the region!
Personally, I love ICMR. The first ICMR in Trento (2011) was my very first conference: since then, I attended almost all editions. Every year I learn something new. And here is what I learnt this year.
UNDERSTANDING THE TANGIBLE
Namely object, scenes, semantic categories: everything we can see.
Objects (and YODA) can be easily tracked in videos. @arnoldsmeulders delivered a brilliant keynote on “things” retrieval: given an object in an image, can we find (and retrieve) it in other images, videos, and beyond? Very interesting technique for tracking objects (e.g. Yoda) in videos based on similarity learnt through siamese networks (more here).

Wearables + computer vision help explore cultural heritage sites. Florence as you have never seen it before! As showed in his keynote, at MICC University of Florence, Alberto del Bimbo and his amazing team have designed smart audio guides for indoor and outdoor spaces. The system detects, recognises, and describes landmarks and artworks from wearable camera inputs (and GPS coordinates, in case of outdoor spaces).
We can finally quantify how much images provide complementary semantics compared to text [BEST MULTIMODAL PAPER AWARD]. For ages, the community have asked how relevant different modalities are for multimedia analysis: this paper finally proposes solution to quantify information gaps between different modalities. In a nutshell:
- Interrelation between textual and graphical information varies: images can augment, generalize or provide details regarding a piece of text.
- Crossmodal interrelations metrics (cross-modal mutual information, semantic correlation) are predictable through deep learning.
Exploring news corpuses is now very easy: news graphs are easy to navigate and aware of the type of relations between articles. Remi and his colleagues presented this framework, made for professional journalists and the general public, for seamlessly browsing through large-scale news corpus. They built a graph where nodes are articles in a news corpus. The most relevant items to each article are chosen (and linked) based on an adaptive nearest neighbor technique. Each link is then characterised according to the type of relation of the 2 linked nodes:
- Near duplicates: little to no additional information between nodes.
- Anterior/Posterior: nodes report events occurred directly before/after.
- Summary/Development: articles provide subset/supersets of information
- Reacts/In reactionI: article in nodes reference each other
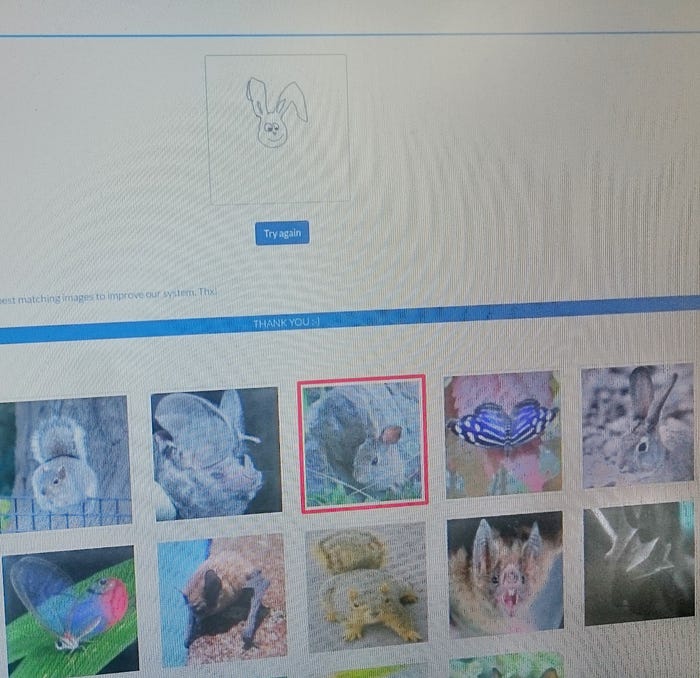
Sketch-based image retrieval can almost cope with my bad drawing skills! The picture below says it all. My personal best poster+demo award goes to Omar Seddati’s Quadruplet Networks ☺
Panorama outdoor images are much easier to localise. In his beautiful work, our friend & former colleague Ahmet from Inria developed an algorithm for location prediction from StreetView images, outperforming the state of the art thanks to an intelligent stitching pre-processing step: predicting locations from panoramas (stitched individual views) instead of individual street images improve performances dramatically!

Face detection beyond photos, beyond pictures, beyond paintings: we can detect cartoon faces in Mangas..! From Taiwan University, a beautiful idea adapting face detection algorithms for face detection in the very wild.

Binary patterns encoded in CNNs boost Texture Recognition. TEX-Nets are CNN models which encode explicit texture properties and color information for effective texture recognition in the wild. And results are amazing.
UNDERSTANDING THE INTANGIBLE
Namely artistic aspects, beauty, intent: everything we can perceive
Image search intent can be predicted by the way we look. In his best paper candidate research work, @msoleymani showed that image search intent (seeking information, finding content, or re-finding content) can be predicted from physisological responses (eye gaze) and implicit user interaction (mouse movements).

Real-time detection of fake tweets is now possible from user and textual cues. Another best paper candidate, this time from CERTH. The team collected a large dataset of fake/real sample tweets spanning 17 events and built an effective model from misleading content detection from tweet content and user characteristics. A live demo here http://reveal-mklab.iti.gr/reveal/fake/.
Music tracks have different functions in our daily lives. Researchers from TU Delft have developed an algorithm which classify music tracks according to their purpose in our daily activities: relax, study and workout.

By transferring image style we can make images more memorable! The team at University of Trento built an automatic framework to improve image memorability. A selector finds the style seeds (i.e. abstract paintings) which are likely to increase memorability of a given image, and after style transfer, the image will be more memorable!

Neural networks can help retrieve and discover child book illustrations.
In this amazing work, motivated by real children experiences, Pinar and her team collected a large dataset of children book illustrations and found that neural networks can predict and transfer style, allowing to make “Winnie the witch”-like many other illustrations.

Locals perceive their neighborhood as less interesting, more dangerous and dirtier compared to non-locals, as reported by this wonderful work presented by Darshan Santain from IDIAP, where they asked local and crowd-workers to look at pictures from various neighborhoods in Guanajuato
The beauty of images in the wild web is very different compared to professional images. And that is why computational aesthetics frameworks trained on curated dataset do not work for aesthetic-based ranking of images in the wild. That’s us (Neil O’hare — Yahoo and myself) :) Hello :)

THE FUTURE
What’s Next?
We will be able to anonymize images of outdoor spaces thanks to Instagram filters, as proposed by this work in the Brave New Idea session. When an image of an outdoor space is manipulated with appropriate Instagram filters, the location of the image can be masked from vision-based geolocation classifiers. Best Motivation award: “Stalkers benefit from knowing your location.”
Soon we will be able to embed watermarks in our Deep Neural Network models in order to protect our intellectual property [BEST PAPER AWARD]. This is a disruptive, novel idea, and that is why this work from KDDI Research and Japan National Institute of Informatics won the best paper award. Congratulations!
Given an image view of an object, we will predict the other side of things (from @arnoldsmeulders keynote). In the pic: predicting the other side of chairs. Beautiful.

Best Quote Award
“We are walking on gold..!”
Ramesh Jain, UCI, visiting Mogoșoaia Palace before the Gala Dinner (golden mosaics on the floor)

THANKS!
To the organisers, to the volunteers, to Maria Eskevich for some of the pictures, and to all the authors for their beautiful work :)

