A/B: O surpreendente poder dos experimentos online
Como combinar o poder dos softwares com testes controlados pode aumentar receitas, economizar recursos e melhorar a experiência dos usuários.
Por Ron Kohavi e Stefan Thomke (publicado originalmente aqui, em inglês)
Em 2012, um empregado da Microsoft, que trabalhava no Bing, teve uma ideia para mudar a forma como os mecanismos de pesquisa mostravam as manchetes. Não seria necessário muito esforço para desenvolver — apenas alguns dias de trabalho de um engenheiro — mas era uma das centenas de ideias propostas, e os gerentes de programa consideraram baixa prioridade. A ideia ficou esquecida por mais de seis meses, até que um engenheiro, que viu que o custo para escrever o código seria pequeno, lançou um teste controlado simples online — um teste A/B — para avaliar o impacto. Em algumas horas a nova variação de manchetes começou a produzir uma receita incomumente alta, ligando o alerta do “bom demais para ser verdade”.
Normalmente, esse alerta costuma sinalizar um bug, mas não era o caso. Uma análise mostrou que a mudança aumentou a receita em impressionantes 12% — que anualmente chegaria a mais de US$ 100 milhões apenas nos Estados Unidos — sem prejudicar a métrica chave da experiência de usuário. Foi a ideia mais lucrativa da história do Bing, mas até ser testada, seu valor foi subestimado.
Uma lição de humildade! Esse exemplo ilustra como pode ser difícil avaliar o potencial de novas ideias. É tão importante quanto e demostra os benefícios de poder rodar testes baratos em quantidade e simultaneamente — algo que cada vez mais empresas estão começando a reconhecer.
Hoje, a Microsoft e várias outras companhias líderes — incluindo Amazon, Booking.com, Facebook e Google — cada uma delas conduz mais de 10.000 testes controlados online anualmente, com muitos desses experimentos engajando milhões de pessoas usuárias. Start-ups e companhias sem histórico digital, como Walmart, Hertz e Singapore Airlines também adotaram a estratégia, em escala menor. Essas organizações descobriram que uma abordagem “testar tudo com tudo” tem recompensas surpreendentemente vantajosas. Por exemplo, ajudou o Bing a identificar dezenas de mudanças relacionadas a geração de receita a serem adotadas todos os meses — melhorias que coletivamente aumentaram a receita por busca em 10 a 25% cada ano. Esses aprimoramentos, junto com centenas de outras mudanças por mês que aumentam a satisfação de usuários, são a razão principal pela qual o Bing é lucrativo, e sua participação nas buscas nos Estados Unidos realizadas em computadores de uso pessoal aumentou para 23%, dos 8% em 2009, seu ano de lançamento.
Em um momento em que a web é vital para quase todos os negócios, testes rigorosos conduzidos online deveriam tornar-se um procedimento padrão. Se uma empresa desenvolve as habilidades organizacionais e a infraestrutura de software necessárias para realizá-los, ela vai poder avaliar não só ideias para websites como potenciais modelos de negócio, estratégias, produtos, serviços e campanhas de marketing — tudo com um custo relativamente baixo.
Testes controlados podem transformar a tomada de decisão em um processo científico, orientado por evidências — ao invés de ser uma reação intuitiva. Sem eles, muitas barreiras podem não ser quebradas, e muitas ideias ruins podem ser implementadas apenas para falhar, desperdiçando recursos.
No entanto, vemos muitas empresas, incluindo algumas grandes do meio digital, com uma abordagem de experimentos quase acidental, sem saber como conduzir testes científicos rigorosos, ou realizando muito pouco desses experimentos.
Nós passamos mais de 35 anos juntos estudando e praticando testes e aconselhando companhias em uma vasta gama de indústrias. Nessas páginas, vamos compartilhar as lições colhidas por nós sobre como desenvolver e executar esses testes, garantir sua integridade, interpretar os resultados e enfrentar os desafios que geralmente eles apresentam.
Apesar de focar no tipo mais simples de experimento controlado, o teste A/B, nossas descobertas e sugestões também se aplicam a designs experimentais mais complexos.
Dando valor aos testes A/B
Em um teste A/B, o proponente monta duas experiências: “A”, o controle, é geralmente o sistema atual e considerado o “campeão”, e “B”, o tratamento, que geralmente é uma modificação que busca melhorar alguma coisa — o “desafiante”. Usuários são selecionados para a experiência de forma randômica, e as métricas-chave são computadas e comparadas.
(Testes univariáveis A/B/C e testes A/B/C/D e testes multivariáveis, em contraste, avaliam mais de um tratamento ou modificações de variáveis diferentes ao mesmo tempo). A modificação pode ser um novo feature (funcionalidade) a ser implementado online, uma mudança da interface de usuário (como um novo layout), uma mudança de back-end (como uma melhoria em um algoritmo que, digamos, recomenda livros da Amazon), ou um modelo de negócios diferente (como uma oferta de frete grátis).
Qualquer aspecto de operação que uma empresa ache mais importante — seja vendas, uso recorrente, taxa de clique, ou tempo de permanência em um site — pode receber um teste A/B para aprender formas de otimizar essa operação.
Qualquer companhia que tenha pelo menos milhares de usuários ativos diários podem conduzir esses testes. A habilidade de acessar grandes amostras de clientes, de automaticamente coletar grandes quantidades de dados sobre interações de usuários em sites e aplicativos, e de conduzir testes simultâneos dá às empresas uma oportunidade sem precedentes de avaliar muitas ideias rapidamente, com grande precisão, e com um custo relativamente baixo por teste incremental. Isso permite a essas empresas iterarem rapidamente, falhar rapidamente e pivotar.
Ao reconhecer essas virtudes, algumas líderes em tecnologia dedicaram grupos inteiros a construir, gerenciar e melhorar uma infraestrutura de experimentação que possa ser empregada por muitas equipes. Tal capacidade pode ser uma vantagem competitiva importante — desde que você saiba como usá-la. Eis o que os gestores precisam compreender:
Pequenas mudanças podem ter um grande impacto
As pessoas comumente assumem que quanto maior for o investimento, maior será o impacto. Mas as coisas raramente funcionam desse jeito online, onde o sucesso tem mais ligação com mudanças menores feitas de forma certa. Apesar de o mundo dos negócios glorificar ideias grandes e disruptivas, na realidade, os melhores resultados são atingidos ao implementar centenas ou milhares de pequenas melhorias.
Colocar ofertas de cartão de crédito na página do carrinho de compras impulsionou os lucros em milhões.
Considere o seguinte exemplo, novamente da Microsoft. (Mesmo que muitos exemplos nesse artigo tenham vindo da Microsoft, onde o Ron lidera os testes, eles ilustram o aprendizado obtido em muitas companhias).
Em 2008, um funcionário no Reino Unido fez uma sugestão aparentemente irrelevante: ter uma nova aba (ou uma nova janela, nos browsers mais antigos) aberta automaticamente sempre que um usuário clicasse em um link do Hotmail na home do MSN, ao invés de abrir o Hotmail na mesma aba. Um teste foi conduzido com cerca de 900 mil usuários britânicos, e os resultados foram encorajadores: o engajamento dos usuários que abriram o Hotmail aumentou em impressionantes 8,9%, medidos pelo número de cliques feitos na home do MSN. (A maioria das mudanças de engajamento tem um efeito menor que 1%). No entanto, a ideia era controversa porque poucos sites até o momento estavam abrindo links em novas abas, então a mudança foi lançada só no Reino Unido.
Em junho de 2010, o teste foi replicado com 2,7 milhões de usuários nos Estados Unidos, produzindo resultados similares, e então a mudança foi aplicada globalmente. A partir daí, para ver o efeito obtido em outros lugares, a Microsoft explorou a possibilidade de as buscas iniciadas na página do MSN serem abertas em uma nova aba. Em um teste com mais de 12 milhões de usuários nos Estados Unidos, os cliques por usuário aumentaram em 5%.
Abrir links em novas abas foi uma das melhores formas de aumentar o engajamento de usuário que a Microsoft já introduziu, e tudo que foi preciso foi alterar algumas linhas de código. Hoje, muitos websites, incluindo Facebook.com e Twitter.com usam essa técnica. A experiência da Microsoft não é a única. Os testes da Amazon, por exemplo, revelaram que mudar as ofertas de cartão de crédito da home para o carrinho turbinou os lucros em dezenas de milhões de dólares anualmente. Claramente, pequenos investimentos podem garantir grandes retornos. Grandes investimentos, no entanto, podem gerar pouco ou nenhum retorno. Integrar o Bing com mídias sociais — para que o conteúdo do Facebook e do Twitter abrissem em um terceiro painel na página de resultados — custou mais de 25 milhões de dólares a Microsoft, e produziu pouco resultado em engajamento e receita.
Testes podem orientar decisões de investimento
Testes online podem ajudar gestores a descobrir qual é a melhor taxa de investimento em um potencial aprimoramento. Essa foi a decisão que a Microsoft enfrentou quando estava buscando reduzir o tempo que levava para o Bing mostrar os resultados de busca. Claro que quanto mais rápido melhor, mas será que o valor dessa evolução poderia ser quantificado? Deveria haver 3, 10 ou talvez 50 pessoas trabalhando nesse projeto? Para responder a essas perguntas, a companhia conduziu uma série de testes A/B em que atrasos artificiais foram adicionados para estudar os efeitos da diferença em minutos da velocidade de carregamento. Os dados mostraram que a cada 100 milissegundos de diferença em performance havia um impacto de 0,6% na receita. Com a receita anual ultrapassando os 3 bilhões de dólares, uma aceleração de 100 milissegundos valeria 18 milhões de dólares anualmente a mais de receita — o suficiente para financiar uma equipe consideravelmente grande.
Os resultados do teste também ajudaram o Bing a fazer trade-offs importantes, especificamente sobre features que ajudariam a melhorar a relevância dos resultados de busca, mas que deixaria a resposta do software mais lenta. A companhia queria evitar uma situação em que vários pequenos features acumulassem uma degradação significativa na performance. Então o lançamento de features individuais que retardavam a performance em mais do que poucos milissegundos eram segurados até que a equipe tivesse evoluído, seja na performance da funcionalidade, seja na de outro componente.
Construa capacidade de grande escala
Mais de um século atrás, o dono de lojas de departamento John Wanamaker cunhou a seguinte frase célebre:
“Metade do dinheiro que eu gastei em propaganda foi jogado fora; o problema é que eu não sei qual metade”.
Nós descobrimos que há algo semelhante em novas ideias: a maioria delas falha em testes, e mesmo os mais experientes acabam errando sobre qual vai vingar. No Google e no Bing, apenas 10 a 20% dos testes geram resultados positivos. Na Microsoft como um todo, um terço se prova eficaz, um terço tem resultados neutros e um terço é negativo. Tudo isso para mostrar que as empresas precisam beijar um monte de sapos (ou seja, conduzir um grande número de testes) para encontrar um príncipe.
Qualquer número que pareça interessante ou diferente geralmente está errado.
Esse é um ponto chave para qualquer teste garantir que as mudanças não sejam para pior ou que tenham efeitos inesperados. No Bing, cerca de 80% das mudanças propostas passam primeiro por testes controlados. (Exceto algumas soluções de bug de baixo risco e mudanças de engenharia como upgrades de sistemas operacionais).
Testar cientificamente quase toda ideia proposta requer uma infraestrutura: instrumentação (para gravar coisas como cliques, mouse-overs e períodos de tempo de eventos específicos), pipelines de dados e cientistas de dados. Várias ferramentas e serviços terceirizados facilitam para testar os experimentos, mas se você quer fazer as coisas em escala maior, você deve integrar essa capacidade nos seus processos. Isso irá reduzir os custos de cada teste e aumentar a confiabilidade. Por outro lado, uma falta de infraestrutura vai manter os custos marginais dos testes alto e pode fazer com que os diretores fiquem relutantes em optar por mais testes.
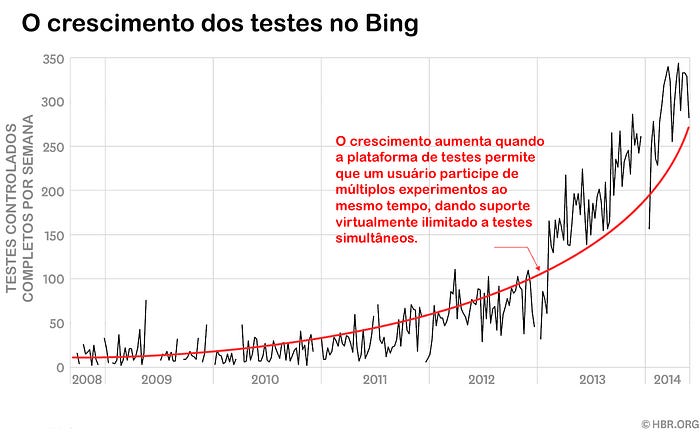
A Microsoft é um bom exemplo de uma infraestrutura de testes substancial — apesar de uma empresa menor ou uma companhia cujo negócio não seja dependente da experimentação possa fazer o suficiente com menos, claro.
A equipe de análise e experimentação da Microsoft consiste em mais de 80 pessoas que em um dia comum ajudam a conduzir centenas de testes controlados online em vários produtos, incluindo o Bing, Cortana, Exchange, MSN, Office, Skype, Windows e Xbox. Cada teste expõe centenas de milhares — e algumas vezes dezenas de milhões — de usuários a uma nova mudança ou feature. A equipe roda análises estatísticas rigorosas em todos esses testes, gerando automaticamente scorecards que checam de centenas a milhares de métricas e apontam mudanças significativas.
A equipe de testes de uma companhia pode ser organizada de três formas:
Centralizada
Nessa abordagem a equipe de cientistas de dados está a serviço de toda a companhia. A vantagem é que eles podem focar em projetos de longo prazo, como fazer ferramentas de testes melhores e desenvolvendo algoritmos estatísticos mais avançados. Um ponto negativo considerável é que as unidades dentro da empresa que usam o departamento podem ter prioridades diferentes, o que pode levar a conflitos de alocação de recursos e custos. Outro contra é que cientistas de dados podem se sentir outsiders ao lidar com diferentes negócios envolvidos, e por consequência estarem menos sintonizados com as metas e o conhecimento específico, o que pode dificultar que conectem os pontos necessários e compartilhem insights relevantes. Além disso, cientistas de dados podem não ter a influência para persuadir diretores a investir na construção das ferramentas necessárias ou fazer com que gestores corporativos das unidades confiem nos resultados dos testes.
Descentralizada
Outra forma é distribuir os cientistas de dados em diferentes unidades de negócios. O benefício desse modelo é que os cientistas de dados se tornam especialistas em cada um dos negócios. A principal desvantagem é a falta de um caminho claro na carreira desses profissionais, que podem não receber feedback dos seus pares nem a mentoria adequada que as ajude a se desenvolver. Além disso, os testes de unidades individuais podem não ter a massa crítica para justificar o desenvolvimento das ferramentas necessárias.
Centro de excelência
A terceira opção é ter alguns cientistas de dados em funções centralizadas e outros dentro das diferentes unidades da empresa (esse é o modelo utilizado pela Microsoft). Um centro de excelência foca majoritariamente no design, execução e análise de testes controlados. Isso reduz significativamente o tempo e os recursos requeridos para essas tarefas ao desenvolver uma plataforma e ferramentas relacionadas que se apliquem a toda a empresa.
Esse modelo também ajuda a difundir a utilização dos testes em toda a empresa, por meio de aulas, laboratórios e conferências. As principais desvantagens são a falta de clareza sobre o que é do centro de excelência e o que é das equipes de produto, quem deve pagar por mais cientistas de dados quando várias unidades aumentarem seus testes, e quem é responsável por investimentos em alertas e verificações que indicam que os resultados não são confiáveis.
Não há modelo certo ou errado. Pequenas companhias geralmente começam centralizadas, ou terceirizam, e depois de crescer, mudam para um dos outros dois modelos. Em empresas com muitos negócios, gestores que consideram testes uma prioridade podem não querer esperar até que os líderes da corporação desenvolvam uma abordagem organizacional coordenada; nesses casos, um modelo descentralizado pode fazer sentido, pelo menos no começo. E se os testes online são uma prioridade da empresa, ela pode querer desenvolver uma expertise e padrões em uma unidade central antes de entregar para cada unidade.
Pense na definição de sucesso
Toda empresa tem que definir uma métrica de avaliação adequada (geralmente combinada) para os testes que alinham com as metas estratégicas. Isso pode parecer simples, mas determinar quais métricas de curto prazo são as melhores previsões de longo prazo é difícil.
Muitas companhias não entendem isso. Entender corretamente — ter um overall evaluation criterion (OEC, ou critério de avaliação geral) — gera debates internos longos e bastante reflexão.
Isso requer uma cooperação próxima entre executivos sêniores que entendem a estratégia e analistas de dados que entendem as métricas e os trade-offs. E não é um exercício que se faz uma vez: nós recomendamos que o OEC seja ajustado anualmente. Chegar a um OEC não é uma coisa fácil, como mostra a experiência do Bing. Suas metas de longo prazo são aumentar a participação nas buscas do mecanismo de pesquisa e suas receitas com propaganda. É interessante notar que a redução da relevância dos resultados de busca vai fazer com que os usuários aumentem as consultas (aumentando as buscas) e cliquem em mais anúncios (aumentando a receita).
Obviamente, tais ganhos devem ter vida curta, porque as pessoas eventualmente mudam para outras plataformas de busca. Então, quais são as métricas de curto prazo que preveem as melhorias de longo prazo em receita e volume de buscas? Em sua discussão do OEC, os executivos e analistas de dados da Bing decidiram que eles querem minimizar o número de buscas pelos usuários em cada sessão e maximizar o número de sessões que os usuários conduzem.
Também é importante depurar os componentes de um OEC e acompanhá-los, já que eles tipicamente oferecem insights sobre o porquê do sucesso de uma ideia. Por exemplo: se o número de cliques é integral para o OEC, medir quais partes da página receberam os cliques é algo crítico.
Observar diferentes métricas é crucial porque ajuda as equipes a descobrir se um experimento teve um impacto imprevisto em outra área. Por exemplo, uma equipe está modificando a exibição dos resultados de busca (digamos, uma busca por “Harry Potter” irá mostrar resultados de livros, filmes, elenco dos filmes, entre outros). A equipe pode não perceber que está alterando a distribuição das buscas (ao aumentar as buscas relacionadas), o que pode afetar a receita positiva ou negativamente.
Com o tempo, o processo de desenvolver e ajustar o OEC e entender as causas e efeitos se torna mais fácil. Ao conduzir experimentos, depurar os resultados (vamos discutir isso mais adiante), e interpretá-los, as empresas não só adquirem uma experiência valiosa com quais métricas funcionam melhor para certos tipos de testes, mas também desenvolvem novas métricas. Com o passar dos anos, o Bing criou mais de 6 mil métricas que os condutores de testes podem utilizar. Elas são agrupadas em templates das áreas que os testes envolvem (busca geral, imagens, vídeo, mudanças de propaganda e por aí vai).
Fique atento aos dados de baixa qualidade
Não importa quão bom é seu critério de avaliação se as pessoas não confiam nos resultados dos experimentos. Conseguir os números é fácil; conseguir números confiáveis é que é difícil!
Você precisa alocar tempo e recursos para validar o sistema de experimentação e configurar salvaguardas e checks automáticos. Um método é rodar rigorosamente testes A/A — ou seja, teste alguma coisa contra ela mesma, para garantir que em cerca de 95% do tempo o sistema identifique corretamente nenhuma diferença estatística significativa. Essa abordagem simples ajudou a Microsoft a identificar centenas de testes inválidos e aplicações impróprias de fórmulas (como usar uma fórmula que assume que todas as medidas são independentes, quando não são).
Nós aprendemos que os melhores cientistas de dados são céticos e seguem a lei de Twyman:
“Qualquer número que pareça interessante ou diferente geralmente está errado”.

Resultados surpreendentes devem ser replicados — tanto para garantir que são válidos quanto para solucionar as dúvidas das pessoas.
Em 2013, por exemplo, o Bing conduziu uma série de testes com as cores de vários textos que apareciam na página de resultados de busca, incluindo títulos, links e legendas.
Apesar de a variação de cor ser sutil, os resultados eram inesperadamente positivos: eles mostravam que usuários que viam títulos em um azul e verde um pouco mais escuros e legendas em um preto um pouco mais claro tinham sucesso em suas buscas em uma porcentagem maior de tempo e aqueles que encontravam o que procuravam o faziam em bem menos tempo.
Já que as diferenças de cores são quase imperceptíveis, os resultados eram vistos compreensivelmente com ceticismo por muitas das áreas, incluindo especialistas em design. (Por anos, a Microsoft, como muitas outras companhias, se baseava em designers especialistas — ao invés do comportamento dos usuários de fato — para definir guias de estilo e cor das empresas). Então o teste foi refeito com uma amostragem muito maior de 32 milhões de usuários, e os resultados foram semelhantes. As análises indicaram que quando aplicadas a todos os usuários, as mudanças de cor aumentariam a receita em mais de 10 milhões de dólares anualmente.
Se você quer que os resultados sejam confiáveis, você deve garantir que dados de alta qualidade são utilizados. Os dados discrepantes devem ser excluídos, erros de coleta serem identificados, e por aí vai. No mundo online essa questão é especificamente importante, por várias razões. Veja os bots de internet. No Bing, mais de 50% dos pedidos vêm de robôs. Os dados podem distorcer os resultados ou acrescentar um “ruído”, o que torna mais difícil a detecção da significância estatística. Outro problema é a prevalência de pontos de medição discrepantes. A Amazon, por exemplo, descobriu que alguns usuários individuais fizeram pedidos muito grandes de livros que poderiam enviesar um teste A/B inteiro; no fim, se descobriu que eram contas de bibliotecas.
Os administradores também devem estar a par quando alguns segmentos sofrem efeitos ou muito maiores ou muito menores que os outros (um fenômeno que os estatísticos chamam de “efeito heterogêneo de tratamento”). Em alguns casos, um único segmento bom ou ruim pode enviesar a média o suficiente para invalidar os resultados gerais. Isso aconteceu em um experimento da Microsoft onde um segmento — os usuários do Internet Explorer 7 — não conseguiam clicar nos resultados de busca do Bing por conta de um bug no JavaScript, e os resultados gerais, que de outra forma teriam sido positivos, ficaram negativos. Uma plataforma de testes deve detectar tais segmentos incomuns; caso contrário, os condutores dos testes que estão observando um efeito da média podem identificar uma ideia boa como uma ruim.
Os resultados também podem ser enviesados se as companhias reutilizam populações de tratamento e controle de um experimento em outro. Essa prática leva ao efeito chamado carryover, em que a experiência de um indivíduo no teste modifica seu comportamento futuro. Para evitar esse fenômeno, as companhias devem randomizar os usuários nos testes.
Outra verificação comum na plataforma de testes da Microsoft é validar que as porcentagens de usuários nos grupos de tratamento e controle no teste em questão corresponda ao design experimental. Quando elas divergem, há uma “taxa de erro da amostragem”, que frequentemente esvazia os resultados. Por exemplo, uma taxa de 50.2/49.8 (821,588 contra 815,482 usuários) diverge o suficiente de uma taxa esperada de 50/50 que a probabilidade de ter acontecido por acaso é menos de uma em 500 mil. Esses erros ocorrem regularmente (geralmente toda semana), e as equipes precisam ser diligentes ao entender o por que, e resolve-los.
Evite suposições sobre causalidade
Devido ao hype da big data, alguns executivos acreditam, equivocadamente, que a causalidade não é importante. Eles acham que tudo o que precisa ser feito é estabelecer uma correlação, e a causalidade não pode ser inferida. Errado!
Os seguintes exemplos ilustram o porquê — e também realçam a falta de testes que contenham grupos de controle. A primeira diz respeito às duas equipes que conduziram estudos observatórios separados sobre dois features avançados para o Microsoft Office. Cada uma concluiu que o novo feature avaliado reduzia o desgaste. Na verdade, quase todo feature avançado vai mostrar essa correlação, porque as pessoas que vão usar um feature avançado são heavy users, e heavy users tendem a ter um desgaste menor. Então enquanto um novo feature avançado tende a ser relacionado a um desgaste menor, ele não necessariamente causa um.
Usuários do Office que recebem mensagens de erro também têm um desgaste menor, porque eles também tendem a ser heavy users. Mas isso significa que mostrar mais mensagens de erro às pessoas usuárias irá reduzir o atrito? Dificilmente.
O segundo exemplo é sobre um estudo que o Yahoo fez para avaliar se as propagandas exibidas nos seus sites poderiam aumentar a procura pelo nome da marca ou palavras chave relacionadas. A parte observacional do estudo estimou que os anúncios aumentaram o número de buscas de 871% a 1.198%. Mas quando foi conduzido o teste controlado, o aumento foi de apenas 5.4%. Se não fosse pelo controle, a empresa teria concluído que os anúncios tiveram um grande impacto e não teriam percebido que o aumento nas buscas se devia a outras variáveis que mudaram durante o período de observação.
Alguns executivos acreditam que tudo que precisam é estabelecer uma correlação. Errado!
Claramente, estudos de observação não podem estabelecer causalidade. Isso é bem conhecido na medicina, e é a razão de a U.S. Food and Drug Administration ordenar que as empresas conduzam testes clínicos randômicos para provar que suas drogas são seguras e eficazes.
Incluir muitas variáveis em testes também dificulta o aprendizado sobre a causalidade. Com esses testes é difícil desfazer o nó dos resultados e interpretá-los. Idealmente, um teste deve ser simples o suficiente para que as relações de causa e efeito sejam compreendidas facilmente.
Outro ponto negativo dos designs complexos é que eles tornam o experimento muito mais vulnerável a falhas. Se um novo feature tem uma chance de 10% de gerar um problema desastroso que exija abortar o teste, então a probabilidade de uma mudança que envolva sete novos features ter um bug fatal é de mais de 50%. E se você puder determinar que uma coisa causa a outra, mas não sabe o por que? Você deveria tentar entender o mecanismo de causa? A resposta curta é sim.
Entre 1500 e 1800, cerca de 2 milhões de marinheiros morreram de escorbuto. Hoje, nós sabemos que o escorbuto é causado pela falta de vitamina C nas dietas, porque os marinheiros não tinham suprimentos suficientes de frutas em viagens longas. Em 1747, o doutor James Lind, cirurgião da Marinha Real, decidiu fazer um teste para seis prováveis curas. Em uma viagem ele deu a alguns marinheiros laranjas e limões, e outros remédios alternativos como vinagre.
O experimento mostrou que frutas cítricas poderiam prevenir o escorbuto, mas ninguém sabia por que. Lind acreditou equivocadamente que a acidez da fruta era a causa da cura e tentou criar um remédio menos perecível ao aquecer o suco cítrico em um concentrado, o que destruiu a vitamina C. Só 50 anos depois, quando o suco de limão não aquecido foi adicionado às rações diárias dos marinheiros, que a Marinha Real finalmente eliminou o escorbuto de suas tripulações. Presumivelmente, a cura poderia ter vindo muito antes e ter salvado muitas vidas se Lind tivesse conduzido um teste controlado com suco de limão aquecido e não aquecido.
Devemos pontuar que nem sempre você tem que saber o “porquê” ou o “como” para tirar proveito do conhecimento do “o quê”. Isso é particularmente verdade quando se trata do comportamento de usuários, cujas motivações podem ser difíceis de serem determinadas.
No Bing, alguns dos maiores marcos foram feitos sem uma teoria subjacente. Por exemplo, mesmo que o Bing pudesse melhorar a experiência de usuário com aquelas mudanças sutis nas cores da tipologia, não há nenhuma teoria bem estabelecida sobre cores que pudesse ajudar a compreender isso.
Nesse caso, a evidência tomou o lugar da teoria.
Conclusão
O mundo online é geralmente visto como um ambiente turbulento, cheio de perigos, mas testes controlados podem nos ajudar a navegar nele. Eles podem nos apontar a direção correta quando as respostas não são óbvias ou as pessoas têm opiniões conflitantes e estão inseguras sobre o valor de uma ideia.
Muitos anos atrás, havia um debate no Bing para deixar os anúncios maiores para que os anunciantes pudessem incluir links para landing pages específicas neles. (Por exemplo, uma financeira de empréstimos poderia ter links como “taxas comparativas” e “sobre a empresa”, ao invés de apenas um link para uma home page). Um ponto negativo era que anúncios maiores obviamente ocupariam mais espaço na tela, o que se sabe, aumenta a insatisfação e irritação do usuário.
As pessoas que estavam considerando a ideia estavam divididas. Então a equipe testou anúncios maiores mantendo o espaço geral para propaganda inalterado, o que levou a exibir menos anúncios. A conclusão foi que mostrar menos anúncios, mas anúncios maiores levou a uma grande evolução: as receitas subiram em mais de 50 milhões de dólares anuais, sem ferir os aspectos principais da experiência de usuário.
Se você realmente quer entender o valor de um teste, veja a diferença entre o resultado esperado e o resultado real.
Se você achou que algo ia acontecer e de fato aconteceu, então você não aprendeu muita coisa. Se você achou que algo ia acontecer e não aconteceu, então você aprendeu uma coisa importante. E se você achou que algo pequeno fosse ocorrer, e os resultados são uma grande surpresa e levam a uma grande quebra de barreira, você aprendeu algo muito valioso.
Ao combinar o poder do software com o rigor científico dos experimentos controlados, sua empresa pode criar um laboratório de aprendizado. Os retornos que você tiver — em economia de custos, novas receitas e uma experiência de usuário melhor — podem ser enormes. Se você quer ganhar vantagens competitivas, sua empresa deveria desenvolver uma capacidade de testes e dominar a ciência de conduzir experimentos online.

