ConvNet Architectures for beginners Part I

Often beginners are intimidated by the number of CNN architectures and Deep Learning terms thrown at them, which can be pretty confusing. This blog series is an attempt to clear those challenges by giving a somewhat brief overview of the architectures available in the industry to aid your decision.
ConvNet: In deep learning, a convolutional neural network (CNN) is a class of deep neural networks, most commonly applied to analyzing visual imagery.
ConvNet architectures are basically made of 3 elements:-
- Convolution Layers
- Pooling Layers
- Fully Connected Layers
Let’s dig a little deeper into these:

Convolution- The term convolution refers to the mathematical combination of two functions to produce a third function.
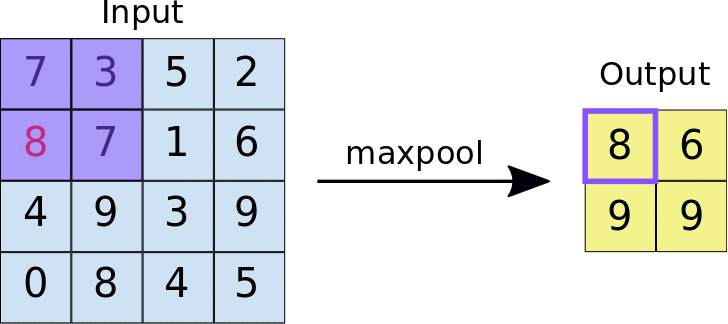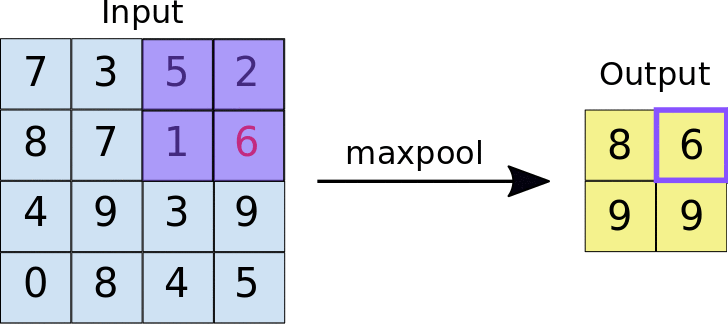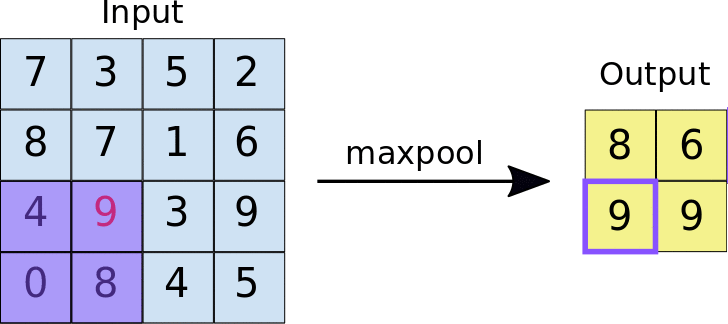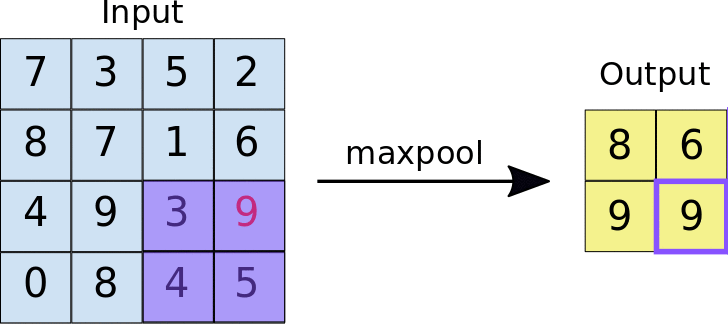
Pooling- The objective of Pooling is to down-sample an input representation (image, hidden-layer output matrix, etc.), reducing its dimensions and allowing for assumptions to be made about features contained in the sub-regions created.

Fully Connected Layers- FCL in a neural network are those layers where all the inputs from one layer are connected to every activation unit of the next layer.
ConvNet architectures follow a general rule of successively applying Convolutional Layers to the input, periodically down-sampling the spatial dimensions while decreasing the number of feature maps using the Pooling Layers.
Feature Maps- The feature map is the output of one filter applied to the previous layer. I.e at each layer, the feature map is the output of that layer.

The architectures to be discussed are used as general design guidelines for modern programmers to adapt and used to implement feature extraction and exploring which are further used for image classification, object detection, image captioning, image segmentation and much more.
Some common architectures:-
- LeNet-5
- AlexNet
- VGG 16
- Inception (GoogLeNet)
- ResNet
- DenseNet
In this part we will talk about the first 3 architectures, which can be regarded as the classic ConvNet architectures.
LeNet-5
LeNet-5 is a convolutional neural network proposed by Yann LeCun in 1989. It was one of the earliest ConvNet architecture and has had a dominant influence over the coming architectures.
Structure

LeNet-5 comprises 2 sets of convolution and max-pooling layers, followed by a flattening convolutional layer, then two fully-connected layers and finally a softmax classifier.

Parameters
~60,000 parameters
Applications
The driving application of this architecture was to recognize simple handwritten numerical digits and was prominently used for recognition of handwritten zip codes in US Postal Services. It can produce >98% accuracy on the MNIST dataset after only 20 epochs.
MNIST- Modified National Institute of Standards and Technology database is an extensive database of handwritten digits that is commonly used for training various image processing systems. The database is also widely used for training and testing in machine learning.
AlexNet
AlexNet is a convolutional neural network, designed by Alex Krizhevsky in 2012. AlexNet is considered the most influential neural net architecture and as of 2020 has been cited over 65,000 times.
Structure

AlexNet comprises of 5 Convolutional layers with 3 Fully Connected layers followed with a softmax layer. From these 5 Convolutional layers, 3 layers have a Max Pooling Layer.

Parameters
~62 million parameters
Application
AlexNet can perform Image Classification on images and is famous for winning the 2012 ImageNet LSVRC-2012 competition by a large margin (15.3% VS 26.2% (second place) error rates).
ImageNet- ImageNet is formally a project aimed at (manually) labeling and categorizing images into almost 22,000 separate object categories for computer vision research. Models are trained on ~1.2 million training images with another 50,000 images for validation and 100,000 images for testing.
VGG-16
VGG Net is a convolutional neural network invented by Simonyan and Zisserman from Visual Geometry Group (VGG) at University of Oxford in 2014.
Structure

The VGG-16 comprises 13 Convolutional Layers with a Max-pooling Layer every 2–3 layers followed with 3 Fully Connected Layers and finally a softmax layer. What puts this ConvNet above others is continuous use of same convolutions with a fixed filter and stride and always using the same padding and max-pool layer of 2x2 filter of stride 2.

There is a variant of this network called VGG-19 which follows the same pattern but with 16 Convolutional Layers and 3 Fully Connected Layers.
Parameters
~138 Million parameters
Application
VGG-16 is considered to be one of the most excellent vision model architecture till date, having scored a tremendous 92.7% accuracy on ImageNet in 2014.
