Comparative Analysis of CIFAR-10 Image Classification: Transfer Learning vs. User-Defined CNNs

CIFAR-10 is one of the benchmark datasets for the task of image classification. It is a subset of the 80 million tiny images dataset and consists of 60,000 colored images (32x32) composed of 10 object classes.
This dataset allowed us to explore different approaches to Image Classification.
In this article, we try to bring forth the issues faced and results while training the dataset and carrying out predictions on Google Colab Notebooks.
We tried the following approaches on CIFAR-10 dataset:
- CNN Architecture: Default CIFAR-10 Image Size
- ResNet101 Model: Default CIFAR-10 Image Size
- ResNet101 Model: Default ResNet101 Input Image Size
For all three variations, the preprocessing was almost the same.
Preprocessing
Both our training and test dataset were available as NumPy arrays. We loaded them using the following code:
trainX=np.load('train_images.npy')
testX=np.load('test_images.npy')We decided to make our validation set of 10,000 images, resulting in 50,000 images in the training dataset. The test dataset contained 10,000 images.
CIFAR-10 dataset is arranged in channel_first format, i.e., an array of (3,32,32), but most of the models interpret the image in channel_last format, i.e., (32,32,3).
def preprocessX(data):
size=data.shape[0]
data_new=np.zeros((size, 32, 32,3 ))
for i in range (size):
data_new[i]=np.dstack((data[i][0], data[i][1], data[i][2]))
i=i+1
return data_newSince we are using the loss function CategoricalCrossentropy(), we need to convert the trainY to one-hot encoded multi-class vectors using to_categorical().
def preprocessY (lst):
integer_encoded = label_encoder.fit_transform(np.array(lst))
trainY=to_categorical(integer_encoded)
return trainYCNN Architecture: Default CIFAR-10 Image Size
Two convolution layers (kernel size as 5x5) having 128 filters each were used. MaxPooling (stride of 2) is used for downsampling. ReLu activation is used to determine the output of each neuron. A fully connected layer with 256 output neurons was followed by a Softmax layer with ten outputs.
model=Sequential()
model.add(Conv2D(128, kernel_size=(5, 5), activation=’relu’, input_shape=input_shape))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(128, kernel_size=(5, 5), activation=’relu’))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256, activation=’relu’))
model.add(Dense(10, activation=’softmax’))ResNet101 Model: Default CIFAR-10 Image Size
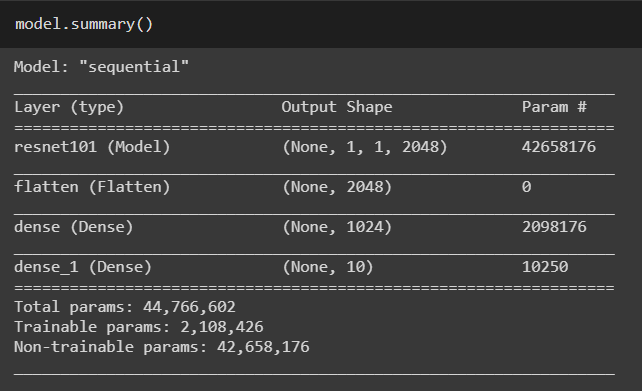
Tensorflow ResNet101 was used as a separate feature extraction program. The input is preprocessed by a portion of the model to give an output for each input image, which is further used as input when training a new model. The include_top parameter is set to False, implying that the fully-connected output layers of the model used to make predictions are not loaded, allowing a new output layer to be added and trained.
base_model = ResNet101(include_top=False, input_shape=(32, 32, 3))The weights of the pre-trained model, (by default, ImageNet) are frozen so that they aren’t updated during training:
base_model.trainable = FalseWhy did we freeze the weights?
ResNet101 is a vast architecture. With limited RAM access on Google Colabs, training a single epoch had an ETA of over an hour.
Further, the CIFAR-10 dataset is similar to ImageNet. Features learnt while training ImageNet may prove to be useful to us.
The following layers were added to the base_model.
layer1=Flatten()
layer2=Dense(1024, activation=’relu’)
layer3=Dense(10, activation=’softmax’)Why did we add a Flatten() layer?
Since the final layer of the ResNet101 architecture was Batch_Normalization, we need to flatten the output before applying fully connected layers.
How did we decide the number of output neurons in the first fully connected layer?
We played around with different numbers like 512, 256, 2048. For each architecture, the training accuracy after the first epoch was noted. We finally narrowed down to 1024 output neurons as it gave a decent accuracy in comparison to the others.
Why do we use a Softmax layer?
Softmax is ideally used for categorical classification. It answers the question:
What is the probability that the image belongs to this category?
We used Keras’ ImageDataGenerator for data augmentation purposes:
gen = ImageDataGenerator(rotation_range=30, width_shift_range=0.08, shear_range=0.3, height_shift_range=0.08, zoom_range=0.08)ResNet101 Model: Default ResNet101 Input Image Size
This approach is the same as the previous approach involving ResNet101 with a change of input size. While incorporating this change on Google Colabs, we faced certain complications.
What were these complications?
The input to the model has to be an array with the following dimensions, [batch_size, img_width, img_height, channel]. In our previous model creating this array was not such an expensive task, but when we try to create this array for 50,000 images, Google Colab crashes. By performing several hit and trial experiments, we concluded that the maximum batch_size possible with a size of 200x200 is 2000.
How did we tackle this problem?
If you notice, we need to convert the data into an array format for the model to interpret it. So we decided to carry out the resizing operation and array creation inside the generator function. Implying, our generator will take some random 64 images and perform the above operations on them.
def gen(features, labels, batch_size):
# Create empty arrays to contain batch of features and labels
batch_features = np.zeros((batch_size, 32, 32, 3))
batch_features_new=np.zeros((batch_size, 200, 200, 3))
batch_labels = np.zeros((batch_size,3))while True:for i in range(batch_size):
# choose random index in features
index= random.choices(range(len(labels)),k=batch_size)
batch_features = features[index]
batch_labels = labels[index]
for j in range(batch_size):
batch_features_new[j]=cv2.resize(batch_features[j], (200, 200), interpolation = cv2.INTER_AREA)yield batch_features_new, batch_labels
Model Compilation
- Optimizer: Adam
- Loss: CategoricalCrossentropy()
Analysis: Training Accuracy
Only the Model Architectures which showed a decent accuracy after the first epoch (comprised of 625 batches) were taken into consideration (trust us, not many fell in this criteria). This is because we felt their accuracy wouldn’t increase sufficiently even after the end of a reasonable number of epochs. We’d love to hear in the comments section what you think about this assumption.
The first three models have been discussed above.

Explaining our Results
A complex multi-layer model like ResNet101 is trained to extract features from large images (it has been pre-trained on image size 256x256). We tried to train it with significantly smaller images (CIFAR-10 image size 32x32). This might have led to the model picking up redundant information or tiny features that may not really contribute to determining the image label, hence leading to incorrect classification and poor accuracy.
However, when we increased the size of the image from 32X32 to 200X200, we got a training accuracy of 97% and validation accuracy of 85%, which is very good considering our previous approaches.
Again, let us know in the comments if you feel we have gone wrong somewhere!
The blog and code were compiled in a joint effort by Nikita Saxena and Naitik Khandelwal.
Github Links: CIFAR-10 Default ResNet101 Size, CIFAR-10 Default CIFAR-10 Size, CNN Architecture

