Explaining Accuracy, Precision, Recall, and F1 Score
Machine learning is full of many technical terms & these terms can be very confusing as many of them are unintuitive and similar-sounding like False Negatives and True Positives, Precision, Recall, Area Under ROC, Sensitivity, Specificity.
There are some great articles on the accuracy, precision, and recall, but when I tried to read them and few other discussions on StackExchange & Stackoverflow, these messy terms got all mixed up in my mind. So I’ve never felt like I fully understood it & It all looks like this in my brain.

The thing is you must have deep understanding of the evaluation metrics to determine the performance of your model. So, In the case of classification models, what do you really need to know?
Allow me to explain the most important metrics in simple terms & using simple examples.
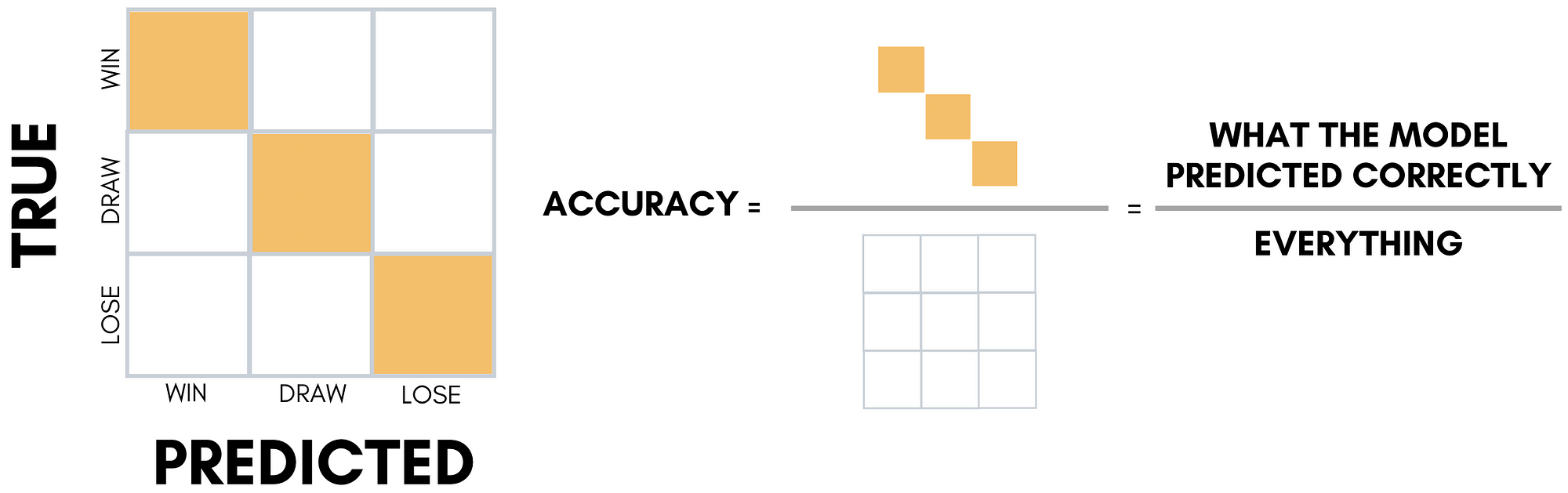
Accuracy
Let’s start with the oldest & easiest — Accuracy.
The standard definition of Accuracy is :

` Good old` Accuracy is literally how good our model is at predicting the correct category (classes or labels). If our dataset is pretty balanced and every category has equal importance, this should be our go-to metric to measure our model’s performance.

But in case our dataset is imbalanced or unbalanced like a credit card fraud detection dataset, for example, we have 5 % fraudulent transactions & 95 % genuine transactions. Now, if our model blindly predicts all test data points as the genuine transactions (majority class in this case), we would have 95% accuracy but we know that our model is not serving any purpose here.TO verify that our model is trying to classify test data points in both the categories instead of assigning majority class, we should refer to the confusion matrix.

Precision (aka Specificity)
The standard definition of Precision is :

or a more simplified version:

In simple terms, Precision is the ratio of what our model predicted correctly to what our model predicted. For each category/class, there is one precision value.
We focus on precision when we need our predictions to be correct, i.e. ideally we want to make sure our model is right when it predicts a label.
For example, if we have a Loan underwriting model that predicts whether to approve or reject a loan request, our priority is being right for all those cases where our model predicted to approve the loan as we will lose money when it approved a loan ideally it should reject. We don’t lose money when it tells us to reject the loan as we still have that money with us.

We use precision where the cost of getting a prediction wrong is much higher than the cost of missing out on the right prediction.
Recall (aka Sensitivity)
The standard definition of Recall is :

or a more simplified version:

In simple terms, Recall is the ratio of what our model predicted correctly to what the actual labels are. Similar to precision, for each category/class, there is one recall value.
We focus on recall when we have a FOMO(Fear Of Missing Out ) situation. Ideally, you want the model to capture all examples of a particular class. For example, airport security scanning machines have to make sure the detectors don’t miss any actual bombs/dangerous items, and hence we are okay with sometimes stopping the wrong bag/traveler.
When use recall, when the cost of missing a prediction is much higher than a wrong prediction.

F1-Score: Combining Precision and Recall
If we want our model to have a balanced precision and recall score, we average them to get a single metric. Here comes, F1 score, the harmonic mean of recall & precision.
The standard definition of Precision is :

But harmonic mean instead of usual arithmetic mean?
The reason is simple and clever. Let us say have a model
Model with a Precision (P)of 0.8 and Recall(R) of 0.4.
So the AM = (0.8+0.4)/2=0.6
GM = sqrt(0.8 * 0.4)=0.5657
HM = 2*(0.8*0.4)/(0.8+0.4)= 0.5333
It is clear that compared to AM and GM, HM penalizes model the most when even one of Precision and Recall is low.
Hence HM is more reliable to be F1-score compared to other means and most definitely must be used to evaluate if we are not in a position to decide levels of Precision and Recall.
Trade-Offs: Real-world Scenario
Ideally, We want both Precision & Recall to be 1 for our model. That doesn’t happen in real-world datasets. Actually, it is a zero-sum game. If we try to improve Precision, the Recall falls and vice-versa.

If we really understand the business problem we are trying to solve, we will know which to focus on — Precision or Recall. Often times, we have to give up one to get more of the other. If we are not sure which to focus on, we can use F1-score to evaluate our model performance.
Conclusion
I hope this small post explains accuracy, precision, recall, and F1 in a simple and intuitive way. If you have more examples or more intuitive way to explain & visualize these metrics, please share.
Credits:
*Also shared on ViHaze (My Startup).

{kind=link}