Interpreting COVID-19 Model Estimates With a Critical Mind
A lot of people will die, the models say. Should you be scared? Not if you understand bias and variable selection.

“The use of modeling or other projections always describes a range of possibilities … they’re not actual crystal balls or real numbers”
- Dr. Theresa Tam, Canada’s Chief Public Health Officer
Range of possibilities! I can’t agree more. Let’s look at Dr. Tam’s statement with more context.
The April Fool’s Joke of 2020
It’s the morning of April 1, and the media is wrapping its head around seemingly horrifying news.
- The White House projected that 100,000 to 240,000 people in the US will die from the coronavirus over “the next couple of months”.
- The province of Ontario in Canada estimated that 3,000 to 15,000 people will lose their lives to the coronavirus in the next two years.
However, at around the same time:
- FiveThirtyEight did not yet have a predictive model estimating the number of deaths from COVID-19. If you want to know why, read this article by Maggie Koerth, Laura Bronner and Jasmine Mithani.
- The Government of Canada did not release it’s model projections at the time of this writing, citing the need to collect better quality data. It instead prioritized better delivery of the raw data itself.
- Everyone else was talking about Tiger King.
Still figuring out what is going on? For the media, and for people in general, the model estimates had a somber message. Yet, experts asked us to not get carried away by the models, and instead focus on the present. Was our interpretation all wrong? Were there gaps in our collective understanding?

Estimates, Confidence Intervals, and Incomplete Data
Interpreting the COVID-19 model projections requires a certain level of statistical thinking. Like Dr. Theresa Tam said, models do not return actual outcomes — the projected deaths haven’t occurred yet. Models return predictions, which contain an estimate and a margin of error. Predicting a single estimate introduces a lot of uncertainty. Wouldn’t it be nice instead to predict a range within which we are confident that the estimate will be correct?
What you are reading in the news is this confidence interval, and therein lies the problem. Even if we are highly certain that anywhere between 100,000 and 240,000 people will die, don’t you think that knowing this range of possibilities beforehand is too big to be useful?
It’s one thing to predict an outcome, but quite another to make that prediction useful.
If you make a prediction, you also need to state how likely it will be actionable. Think about it for a moment. The scale of operations required to supply sufficient PPEs to avert 240,000 deaths is much larger than that required to avert 100,000. How can public health officials ever make reasonable decisions if they have to deal with such a wide range of possible outcomes?
This is the turning point. This is where we stop looking at the predictions and ask a few basic questions. What data and variables were used to train the model? Did the models measure the correct metrics? What measures were taken to reduce biases in data?
As it turns out, the COVID-19 model projections were not only horrifying, but also horribly wrong.
One Week Later
Just as we were coming to terms with our possible future,
- The White House decided to use a revised model that predicted 60,400 deaths by August.
- Everyone else was still talking about Tiger King.
Wait a minute! This is a massive about-turn from the original estimate. Can somebody please explain what is going on?

It’s time to ask ourselves some serious questions.
A statistician asks: What variables were selected in training the model?
Simply translated: Did Italy and Wuhan have returning spring breakers and snowbirds?
Incorrect variables do not generate models with actionable insights. The models projecting deaths in North America were built using known data from other countries like Italy and China. Why is that a big problem? Let’s use an example. The communal spread in Italy was attributed to other factors, and not necessarily from returning snowbirds and spring breakers like in Québec and New York. Predicting the number of coronavirus cases in the United States or Canada based on models trained on data collected from other countries such as Italy would be very inaccurate.
A statistician asks: Did you normalize your data?
Simply translated: How many people are being tested for the coronavirus?
The number of positive cases of COVID-19 come from those who have been tested. The more you test, the more the number of positive cases you will observe. Fair enough, right? Except that each country has different criteria to decide who gets tested, resulting in a lack of uniformity across all the data collected. The problem is worse in North America, where the testing criteria change from state to state, county to county, province to province. Add to that a shortage of testing kits, and you will actually under-report the number of positive cases. Using such incomplete data in modeling leaves the room open for adding biases that should have been removed.
Let’s compare the numbers in Canada’s four largest provinces.
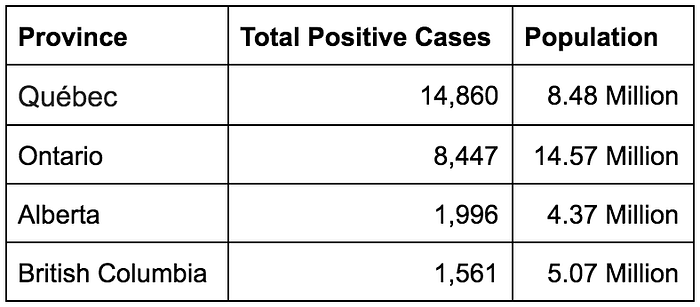
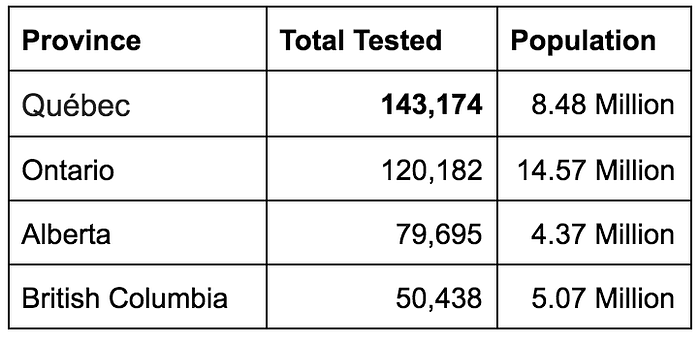
Québec looks like the worst affected province in Canada, but is it? This table gives you only half the picture. Québec has not only tested more people than any other province in Canada, but has also conducted more tests per capita.
Also, notice how the growth rate in the number of cases in Québec accelerated after March 23.
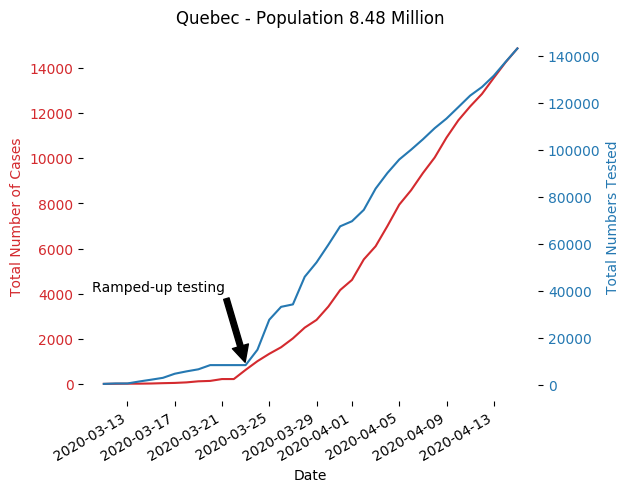
According to this article, epidemiologists are interested in the doubling rate and tenfold rate, i.e., in how many days will the number cases double, and increase tenfold, respectively. If the growth rate changes dramatically by restricting or expanding the testing criteria, like we see with Quebec, then any modeling on the doubling rate and tenfold rate won’t be reliable. We need to normalize these numbers to control for the biases we observe.
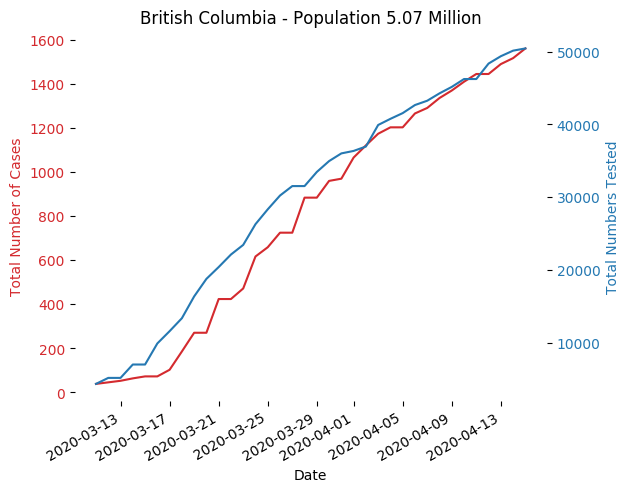
On the other end of the spectrum, British Columbia seems to be successfully flattening the curve. Note how their testing curve seems to be flattening too!
A statistician asks: Is the model built on data that is representative of the target population?
Simply translated: Will social distancing impact the model estimates?
Yeah, you might have heard of it. Always model your data on a random sample that is representative of the universe. Except that in this scenario, it was not possible. Did these models account for how social distancing can potentially reduce the number of cases and deaths? I don’t know the answer, but if I read this article, I have a reason to believe that was not the case. Again, the point is that if conditions change, using models that do not control them are not going to be useful.
What do we make of these COVID-19 models?
Be concerned, but not scared. These models are not doomsday predictions. Rather, their purpose is to help public health officials estimate how many ICU beds, ventilators, and PPEs we will need to fight this pandemic over the coming months. For the rest of us, it offers a glimpse into the damage that can cause if we choose to be careless and not listen to our epidemiologists. If you want to live in a better world than the one predicted, then practice social distancing, stay at home, and watch Tiger King!

