Scene Text Detection, Recognition & Translation
Published in
9 min readJan 19, 2021

Table of contents
- Introduction
- Business Problem
- Mapping to Deep Learning Problem
- Data Overview
- EDA(Exploratory Data Analysis)
- Baseline Model
- First Cut Solution
- Model Explanation
- Best Model
- Conclusion
- Future Work
- References
1. Introduction
- The need for computer vision in text detection and recognition from an image or video is getting very popular these days. Because the text is to reliably and effectively spread or acquire information across time and space.
- This approach can be used for handwriting recognition, natural scene text detection and recognition, vehicle number detection and recognition, and many more. But multiple challenges may still be encountered when detecting and recognizing text in the scene.
2. Business Problem
- Natural scene images may be blurred, noisy, and in low quality, or multi-oriented(rotated/ curved).
- So, we have to deal with this problem also. To overcome this before detecting the text from those regions there are several steps needed for processing the image to deblur and de-noising it.
3. Mapping to ML/DL Problem
3.1. Type of ML/DL Problem
- The problem is to build a system that can detect the text regions from natural scenes and then text can be extracted/recognized from those regions.
- This system can also be integrated to not only recognize the text from natural scenes but also text can be translated to any native language of the end-user.
- To do so, we can either build a Deep Learning-based end-to-end scene text detection and recognition model and then integrate a text translation module on top of it, or an independent text detection, recognition, and translation model can be integrated together.
3.2. Performance Metric
To measure the performance of end-to-end scene text detection and recognition, we can either compute character-level accuracy or word level accuracy.
4. Data Overview
- The scope of this project is limited to only one language for detecting text and then converting it to another language after recognition.
- For this project, I’ve chosen the ICDAR 2015 dataset which contains images for English word-level text.
a. The ICDAR15 dataset contains 1,500 images: 1,000 for training and 500 for testing. Specifically, it contains 2,077 cropped text instances, including more than 200 irregular text samples.
b. As text images were taken by Google Glasses without ensuring the image quality, most of the text is very small, blurred, and multi-oriented.
c. No lexicon is provided. - The whole dataset can be downloaded from here.
- An ICDAR 2015 images are blurred, noisy, multi-oriented, rotated or curved, and of low quality.
- A training set of 1000 images containing about 4500 readable words will be provided through the downloads section.
- Different ground truth data is provided for each task.
- All images are provided as JPG files and the text files are UTF-8 files with CR/LF newline endings.
- The ground truth is given as separate text files (one per image) where each line specifies the coordinates of one word’s bounding box and its transcription in a comma-separated format.
- There is a total of 1000 train images and 500 test images.
- The total size of the ICDAR15 dataset for both train and test images is 129 MB.
5. Exploratory Data Analysis
5.1. Displaying a few sample datapoint
Displaying a few random images

Sample file (gt_img_1.txt) which has ground truth for each word of img_1.jpg with their co-ordinates
377,117,463,117,465,130,378,130,Genaxis Theatre
493,115,519,115,519,131,493,131,[06]
374,155,409,155,409,170,374,170,###
492,151,551,151,551,170,492,170,62-03
376,198,422,198,422,212,376,212,Carpark
494,190,539,189,539,205,494,206,###
374,1,494,0,492,85,372,86,###Note: Anything that follows the eighth comma is part of the transcription, and no escape characters are used. “Do Not Care” regions are indicated in the ground truth with a transcription of “###”.
5.2. Total text instances and unique text instances in the dataset
Total number of text instances in whole dataset images is 6545.
There are total of 4468 text instances for ground truth of train images.
There are total of 2077 text instances for ground truth of test images.
--------------------------------------------------------------------
Total number of unique text instances in whole dataset images is 3558.
There are total of 2374 unique text instances for ground truth of train images.
There are total of 1184 unique text instances for ground truth of test images.5.3. The number of images with different dimension, channels & extension
Unique dimension of all images: {(720, 1280)}
Unique channels of all images: {3}
Unique extesions of all images: {'jpg'}6. Baseline model
6.1. Text Detection using MSER

6.2. Text Recognition using Pytesseract

- As we can observe, MSERs have limited performances on blurred or noisy images and textured images. MSER is not suitable for rotated or curved, word-level text detection because it can detect one word as multiple characters. Also as we can see, MSER also detects some unwanted or say no-textual region in our case.
- Pytesseract is not 100% accurate, has its own limitation. As we can observe blurred, rotated, small images are either recognized incorrectly or not recognizes any text. So, the Pytesseract OCR engine recognizes accurate text mostly for horizontal text instances but for rotated or curved text instances it may not work well.
7. First Cut Solution
- The main objective of this case study is to build a system that can detect and recognize a text from a natural scene image and then can be translated to another language that the end-user can understand.
- This dataset is multi-oriented, so there are few instances of images that are rotated or curved. So, we have to deal with this problem also. To overcome this problem, there is something called Spatial transformer networks (STN).
- Spatial transformer networks (STN) allow a neural network to learn how to perform spatial transformations on the input image in order to enhance the geometric invariance of the model. For example, it can crop a region of interest, scale, and correct the orientation of an image.
- It can be a useful mechanism because CNNs are not invariant to rotation and scale and more general affine transformations.
- The overall architecture of this system can be as follows:
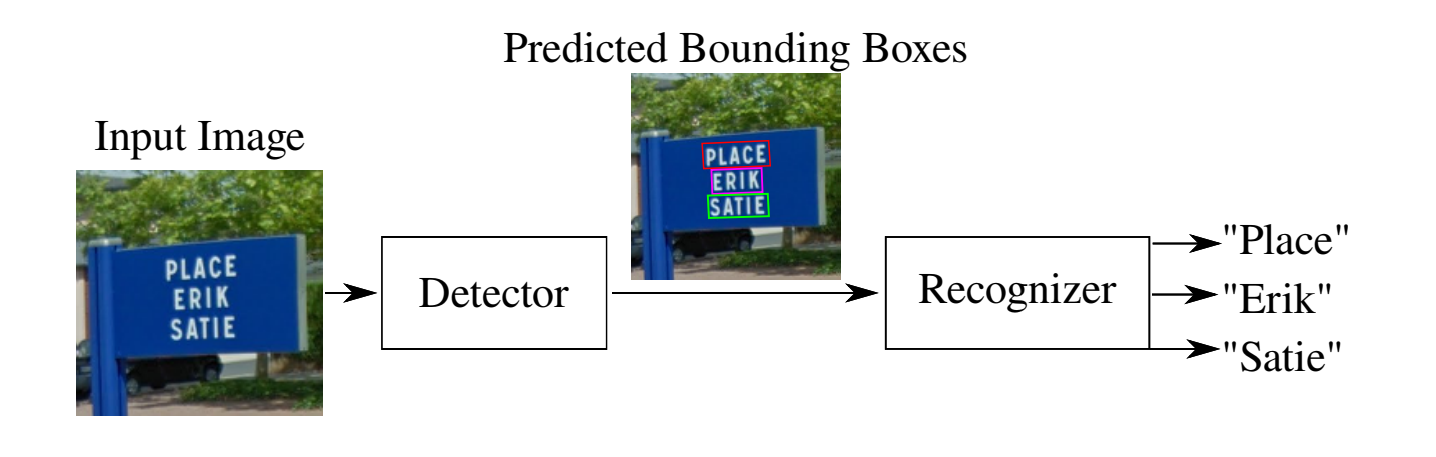
a. Text detection: Detect the text region or say getting co-ordinates of text region in an image,
b. Text recognition(Recognizing the text from the retrieved bounding box images using OCR),
c. Text correction: There might be a possibility that 1 or 2 char of text is recognized incorrectly, which will make the whole word incorrectly recognized for word-level recognition. So this can be avoided by implementing a text correction model that can correct the spelling of recognized words to improve the model,
d. Text language translation: Recognized and corrected text can be translated into any language that the end-user can understand
8. Model Explanation
8.1. EAST (Efficient accurate scene text detector) text detection with pytesseract text recognition
Actual text instances: ['joint', 'yourself', '154', '197', '727', '198', '20029', 'free', 'from', 'pain']
Predicted text instances: ['free', 'yourself', 'from', 'joint', 'pain', 'pte']
Number of correctly recognized word: 5
Number of incorrectly or not recognized word: 5
Accuracy: 50.0 %
-------------------------------------------------------------------
- The EAST model finds a bounding box of text instances very well for clearly visible instances but for small, rotated or noisy instances it doesn’t work very well.
- Pytesseract OCR engine recognizes accurate text mostly for horizontal text instances but for rotated or curved text instances it is not working as per our expectations.
8.2. EasyOCR text detection & recognition



- As we can see, EasyOCR gives better results than EAST text detection and pytesseract text recognition.
- But still while recognizing the text there are some mistakes although the detected text region is quite accurate. Even for rotated and blurred text regions, it detects very efficiently.
- So to build the accurate text detection and recognition model, we can combine the EasyOCR text detection result and different much more accurate text recognition models.
9. Best Model
- We have seen, EasyOCR models do a pretty well job while detecting the text region from an image although its recognition is quite good. But as we know, our ICDAR15 dataset has lots of rotated, blurred, low-resolution due to which in some cases text recognition fails.
- So, to improve or get well adequate text recognition results we’ll be proposing a different recognition model and then we can combine the results of EasyOCR text detection with different text recognition models to get more accurate predictions.
- Most of the text regions are blurry, rotated(can be clockwise as well as anti-clockwise), so to do more accurate recognition we need to apply some kind of transformation on images.
- In most recent years, spatial transformation network became very popular for image transformation as it allows a neural network to learn how to perform spatial transformations on the input image in order to enhance the geometric invariance of the model.
- For example, it can crop a region of interest, scale and correct the orientation of an image, and so on.
- So, after getting N different detected text regions we’ll be processing those regions independently from each other. The processing of the N different regions is handled by a CNN. ResNet-based feature extraction will be used to achieves good results if we use a variant of the ResNet architecture for our recognition network. We can also integrate BiLSTM (Bi-directional Long Short-Term Memory) sequence model to improve the result by learning not only from beginning-to-end but also from end-to-beginning.


Accuracy of the best model
- The average character-level accuracy of test images is 85.69%.
- The average word-level accuracy of test images is 67.45%.
- 90.4 % of test images have more than 60% of character-level accuracy.
- 64.4 % of test images have more than 60% of word-level accuracy.
10. Conclusion
- EAST with pytesseract text detection and recognition works well but only for horizontal and nice quality images. But in our case, its performance is like a random model that may work well but not in every case or in very few cases.
- EasyOCR gives better results than EAST text detection and pytesseract text recognition. But still while recognizing the text there are some mistakes although the detected text region is quite accurate. Even for rotated and blurred text regions.
- Final hybrid text detection, recognition, and translation model which is a combination of EasyOCR text detection, custom text recognition, and pre-trained language translation give much better result than our previously experimented models.
- With our final model, 90.4 % of test images have more than 60% of character-level accuracy and 64.4 % of test images have more than 60% of word-level accuracy.
11. Future Work
- We can build this model with multilingual support.
- It can be improved to not only the recognized text of one language but also the recognized text that can be translated to any native language of the end-user.
- We can also deploy our best model in production using streamlit, flask, or any other API.
12. References
- https://www.appliedaicourse.com/
- https://www.pyimagesearch.com/2018/08/20/opencv-text-detection-east-text-detector/
- https://github.com/saveriomiroddi/EasyOCR-dev
- https://github.com/clovaai/deep-text-recognition-benchmark
- https://norvig.com/spell-correct.html
- https://www.geeksforgeeks.org/build-an-application-to-translate-english-to-hindi-in-python/

{kind=link}