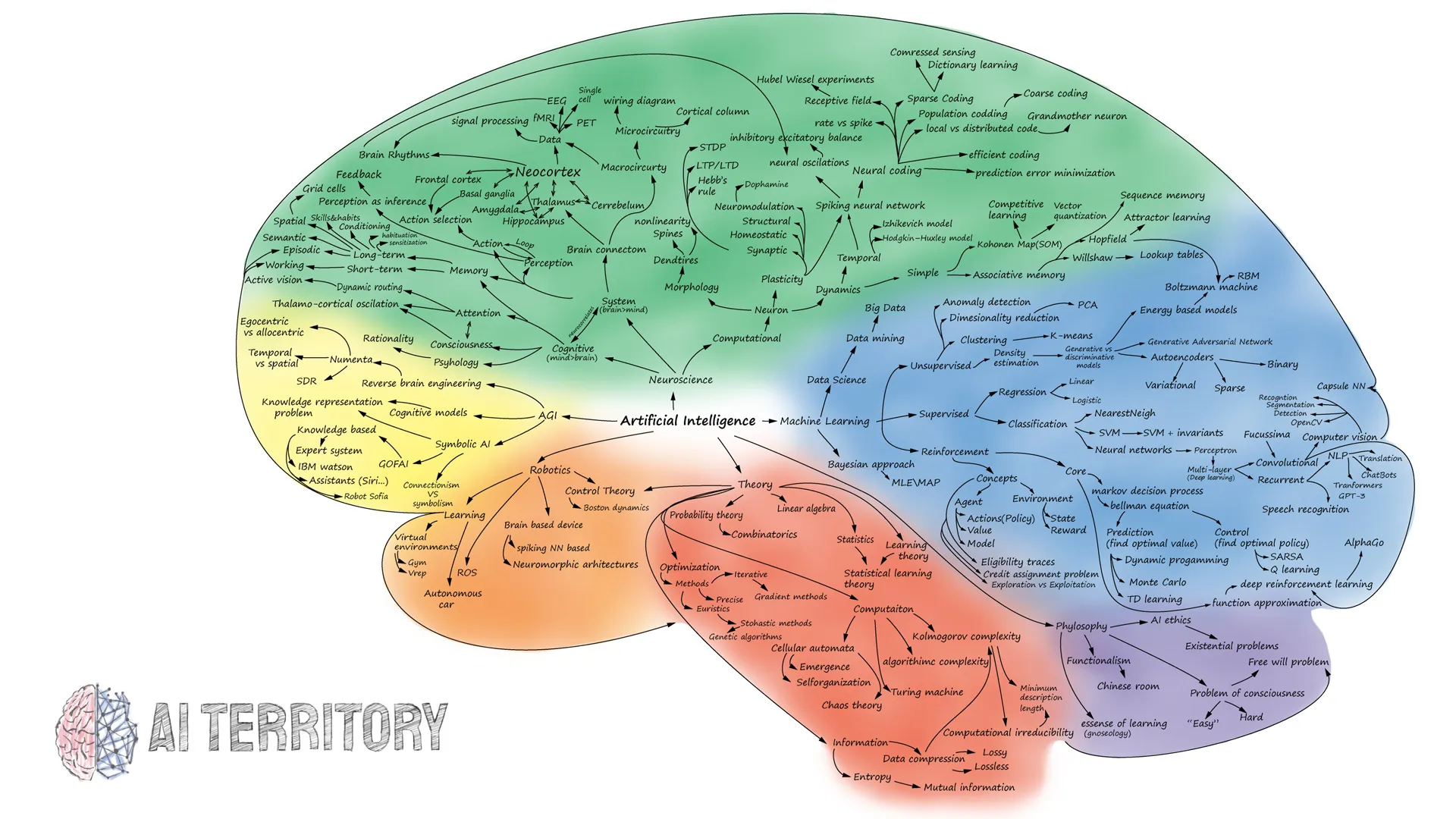
The Map of Artificial Intelligence (2020)
Notice: This map is not a precise reflection of the state of the AI field, but just my subjective representation.
This is my first map as of the end of 2020 and will be extended in the future. It contains more than 200 words or phrases, so to describe all of them would be too extensive and overkill. Much more interesting (and useful for me) to tell how this map was gradually building in my head. I will not explain everything, just the main things, so it is normal not to understand something.
The story begins in 2013 after I finished my bachelor in applied physics. I was researching heterostructures, something that is in the core of the solid-state lasers that are used for Internet transmission. In short, I was not satisfied, the field is good and perspective but not in Ukraine. So, I decided to write my master thesis in a different field that I will be truly interested in. I had two options and I chose one — the field of artificial intelligence.
That summer I finished my first-ever online course on Coursera — Machine learning by Andrew Ng. Online courses just began, Coursera existed only for a year. The course gave not a bad perspective on machine learning that can be subdivided into supervised, unsupervised, and reinforced learning. There are also typical problems, like classification, regression, clustering and each has its own solutions.
Back then, I understood that the area is quite premature. I was used to physics, it has deep foundations, the basis for all phenomena. For example, Maxwell’s equation and Lorenz force explain entire classical electromagnetism, optics and the base of electronics. But machine learning seemed to me as merely a collection of methods and algorithms. If you need to make clustering, you can try k-means or a mixture of Gaussians, or in case of bad results try something else.
If you need to fit the data to a line, here is a linear regression. The same for classification, there are logistic regression, or SVM, or neural networks. However, there was no theory that would generalize and explain all. You just need to look for an algorithm that works best for a particular case, particular dataset.
Later, from time to time, I was returning to machine learning, but it did not catch me.
I wanted something more. That time I read the book “On Intelligence” by Jeff Hawkins. He wrote that the essence of intelligence is to make predictions, explained how the human brain works, and that it is possible to find an algorithm that would work like the brain.
He popularized the idea that the neocortex (superficial part of the brain) consists of minicolumns. These cortical columns structurally are pretty similar and if we could understand how the one works, we could understand the brain. I thought back then, “wow, he is really going to create artificial intelligence and very soon”. Sadly, the book was written in 2004, but by 2013 there was no huge progress. It seems the problem is much harder.
However, I was excited by the idea that we need to understand the human brain to be able to create AI. That is why I started to learn neuroscience — the branch of science that studies how neural networks work. Do not confuse it with neurology, which studies the diseases of the neural system. I have found an excellent online course “Medical neuroscience”, where I learned fundamentals. Starting with the anatomy, where the peripheral neural system gathers information and sends it to the central parts, especially to the thalamus (like the main hub). It sends the activation to the neocortex and here the main information processing happens. Sensory signals are transformed into motor commands that are sent back to the periphery with the help of the cerebellum and basal ganglia. Hippocampus contributes to memory storage. Close to it, people found grid cells, neurons that become active only in particular locations in the environment (often compared with the GPS). Plus another important structure — the amygdala, also contributes to memory and emotions and can process information even before the neocortex to quickly drive actions (like escaping from the scary snake).
System neuroscience studies how the huge systems are working with as many as billions of neurons. One of the tasks is to build a brain connectome, the model of connections of all 100 billions of neurons of the brain. But it is too hard, and for now, people are happy at least with the connectome of smaller structures (macrocircuitry) or of even smaller separate neural networks with 100–10000 neurons (microcircuitry).
For example, in a big European Human Brain Project, researchers made a model of a local network with around 31000 neurons. The size of the neurons is around 30 micrometers, twice as thin as human hair. A typical neuron makes 10 000 connections, which are called synapses with the size of several micrometers. That is why it is so hard to track all connections on such a scale. But there are many methods, starting with those that work on the scale of centimeters (EEG) or millimeters (fMRI) to those that can measure the activity of a single neuron (patch clamp) or the group of neurons (multielectrode array).
System neuroscience follows the principle “brain ->mind”, by studying the brain we will better understand the mind. Cognitive neuroscience — uses the opposite approach, by studying the mind we could better understand the brain. They connect through neurocorrelates — the neural networks that we can relate to complex phenomena like memory, attention or even consciousness. Cognitive neuroscience studies memory from the psychology perspective and defines the episodic, semantic, procedural memory, but system neuroscience approaches more materialistically and searches for the particular neural networks where the memories reside. By the way, simple emotional memories are stored in the amygdala and can be identified, erased, rewritten, and paused on the neural level. Sadly, it works only still with the mice.
In that period I found many cognitive models that are trying to create programs similar to the brain. For example, here is the block that corresponds to the basal ganglia, has certain inputs and outputs, and performs the decision-making. Another block, like the frontal cortex, intervenes in decision making by adding the context of episodic memory. The more people know about the brain the more accurate and complete becomes such models.
There is even a community AGI (artificial general intelligence) with annual conferences where such models are presented. This could be a good way to organize the data, but I am very skeptical that one day some cognitive model will start thinking by itself. Environment of the AGI community is peculiar. On one side I like that they remain faithful to the original goal to create true (general) artificial intelligence on par with the human and they openly state that. They think very wide, take information from neuroscience, psychology and mathematical algorithms. On the other side, I did not see the fundamental basis like in physics. There are many handcrafted solutions, like the robot Sofia that is portrayed by the journalists as a smart robot, but in reality, it is not.
With the AGI we can relate the symbolic approach in artificial intelligence, or Good Old Fashioned AI (GOFAI). It tries to make AI as a program that manipulates symbols, or via the logic operation, or by the cause and effect rules. This approach was popular at the beginning of AI in the 50th to 80th but now is barely alive. Not long ago, it was forced out by the connectionist approach in the form of neural networks.
In the middle of 2014, I went to a summer school in my Kyiv Polytechnic University. That is where I become addicted to computational neuroscience that describes a neural system in a rigorous mathematical way. Only that makes it interesting :) There are two main topics — neural dynamics and synaptic plasticity. Neuron generates electrical impulses with an amplitude of 0.1 volts and a duration of several milliseconds. Dynamics describes how the electrical potential of a neuron changes and when a neuron should fire impulses. Mathematically it is well defined by a Hodgkin Huxley model (system of four first-order differential equations), which was even awarded a Nobel Prize.
It can be extended and complicated with the addition of ion channels and providing the shape of a neuron (it is called morphology, how axons and dendrites are located in space).
Dynamics becomes very accurate with a more complete model that is even possible to predict individual electrical impulses (huge blow to the free will:)). It is possible to simplify equations leaving behind a biological mess and just recreate electrical impulses. Usually, such models are used in spiking neural networks — computational models where many neurons are connected together and they show complex rhythmic or chaotic activity.
The second key topic in computational neuroscience is synaptic plasticity that describes how neurons change their connections. Dynamics of a neuron is more or less well studied and understood, but the change of connections is covered in mystery. All magic of the brain comes from the plasticity of synapses between neurons. The strength of a connection can vary because of the different number of ion channels (that neuron uses to pump in/out positive/negative charges), or due to the presence of neuromodulators, like the dopamine (that makes neuron pump even stronger), or because of internal processes, that try to sustain a stable state, that is to maintain homeostasis. Moreover, connections may disappear, disconnecting the neurons, or be silent, waiting to be reactivated in the right moment, or be created in totally new places. It changes the whole network structure; the graph that describes the connections is dynamic. It is believed that neurons through their connections reflect all subtleties of an environment (that is perceived by sensors).
This is one of the main differences between learning in biological and artificial neural networks. For the first, the structure is constantly changing (architecture is dynamic), for the second learning predominantly occurs by tweaking the strength of connections.
There are many mathematical models of learning in biological neural networks. First and the most famous is Hebb’s rule: the strength of connection from neuron A to neuron B increases if neuron A takes part in the activation of neuron B. Simplified: fired together — wired together. Think about two different objects, two encoding groups of neurons get activated and wired together as an association is formed.
Ending 2015 and the whole of 2016 I spent researching synaptic plasticity because the change of connections is the key to understanding the brain. I have dug into very complicated molecular mechanisms of synapse regulation, huge cascades where one molecule activates another and that another so that another makes something useful. When I saw that everything is governed by genetics, by gene expression that through epigenetics can be unique in every neuron, I thought “no way, it is too much, there should be some more simple, more general principles”.
By the beginning of 2017, I had a lot of practice with spiking neural networks and quite well understood them. I was lucky to spend the next 6 months in a French robotics laboratory. It was a good chance to check if it is possible to apply fundamental research of learning in biological neural networks in practice. Could I make something useful, like controlling the robot? There is a classical approach to robotics, based on control theory that is used, for example, in Boston dynamics in their robodogs. I liked the approach of brain-based devices, where neural networks similar to biological send commands to a robot. In addition, there is an even more advanced approach with neuromorphic architectures, where specially designed electronics efficiently implement algorithms of activation and learning of neurons, like the TrueNorth chip.
Usually, before putting an algorithm into a robot you need to get it to work in a virtual environment. The same was with me, I placed the robot in a simulated room, scattered the objects and the image from a camera was sent to a neural network. Thanks to my internship in a lab, I could perform experiments in real life. In this video, I just played with the robot that says “Glory to Ukraine” :)).
As a result, I understood that computational neuroscience and particularly spiking neural networks are not a proper solution for practical tasks. Yet. They are too computationally hungry and require powerful computers. Even so, the ultimate problem is that it is very hard to understand how to make them work. The model of a neuron can have dozens of parameters and be described by dozens of differential equations. Try to unravel this mess…
Still, there is something magical in robots. At first, they look like a stupid piece of matter, even if you run the stock soft that makes the robot speak and answer simple questions. However, when you upload a simple saliency map (a program that determines interesting places where to look, like bright colors, or movements, or complex shapes, or textures), the robot starts to move its head as if it purposefully investigates the world around. Suddenly, you start to think that there is something inside the robot, that it is not empty. You endow it with life and emotionally treat it so differently. In the future when the software becomes better, robots will enter our life. And we will make bonds with them like with our pets or even stronger.
After the failure with the spiking neural networks, I started to seek other approaches, simpler. Then I entered a new field — a field of association memory. It researches how many “memories” you can store in connections between neurons. A typical example is a Hopfield network, you show it a set of images, the network remembers them (as attractors), and when you show part of the image or the noisy image, the network recalls the correct stored image.
Classical result in this field is that memory capacity is the biggest when the number of active neurons is small. Interestingly, the same is true for biological neurons: in the memory-related areas of the neocortex, the number of simultaneously active cells is very small, around 2- 5%. This is a very cool example when people have found an abstract law of mathematics that is realized in real neural networks. Based on that, a completely new branch in signal processing aroused — sparse coding. It originates from neuroscience recognizing that a sparse representation is ubiquitous in biology and is a good candidate for the storage and processing of information.
At the end of 2017, my friend left the job of a software engineer to do science and we together started to dig into the hierarchical temporal memory (HTM). This is a model from the Numenta Company, founded by Jeff Hawkins, mentioned in the beginning. The company tries to do reverse brain engineering, to implement neuroscience in algorithms. We carefully and with scrutiny studied their algorithms, and came up with a conclusion that the ideas are great but the realization could be better. One of the best ideas is that we need to encode information in various coordinate systems: relative to other objects, called allocentric, and relative to our own body or its parts, egocentric. The point is that humans constantly and unconsciously move their eyes (do saccades) while examining some objects. This helps the brain to pick up valuable spatial relationships about what and where everything is located.
Another crucial idea from HTM is the recognition of the importance of sequences. They are everywhere, and even our perception is sequential. Thus, the model should somehow store sequences, predict and generate them (like humans constantly generating motor commands).
We tried to do our implementation of these ideas, wrote the program that sequentially finds interesting places on the image and links local features with their relationships. It worked, more or less, but not exactly how we wanted (by the way, a capsule network by Hinton tries to realize the same idea, also unsuccessfully). After the failure, I realized that we were moving blindly, without any fundamental theory like in physics.
The same is true for Deep learning (DL). The story behind DL is a good example of how science interacts with the industry, popularizes itself and earns grant support. Multilayer neural networks have existed for a long time, also sometimes called multilayer perceptron. Still, they didn’t show good results: for the classification, the SVM was the number one, in language processing — hidden Markov models, in computer vision — complex models, a mix of different algorithms. But with the emergence of relatively cheap and powerful enough computational resources (graphics cards, GPU) it became possible to train large neural networks on huge datasets for a short time (still, sometimes it took weeks). Of course, there were many smart engineering solutions, but no one expected that suddenly neural networks would beat previous records in many machine-learning tasks (benchmarks). With this success (2012 year and even a bit earlier) researchers started to rebrand multilayer neural networks into Deep Learning. Mass media caught it and spread it as something new, as a great advance in AI, often too exaggerating. A similar story was with Data science, as a new more attractive name for applied statistics, or Data mining as methods from unsupervised learning. Still, it works, the number of grants in this field skyrocketed. It brought forward new researchers, educational programs, and, of course, engineers in tech companies.
Other researchers of artificial intelligence, that perform important and perspective research, but not in a trend, sat in a corner and quietly cried :). Some researchers started to deny deep learning, saying that it is not a science; it does not have any theory behind it. Another just slowly drifted towards deep learning in their research. Yet another incorporated their previous results into the new framework. As for me, I curiously observe the deep learning progress and try not to lag behind, but for me, artificial intelligence is not limited to just deep learning, we need to look wider.
I think, in the future when the theory of artificial intelligence will be complete it will start with information theory. Thanks to the great course by D.MacKay in 2018, I understood the essence of entropy, what is mutual information and data compression. Some even say that the data compression problem and artificial intelligence are very tightly linked. However, even the information theory did not help me to solve another task. This time there were three of us; one smart PhD student had joined. We set a simple task, to make the program that would win in a pong game (hit the moving ball). It is already solved by the classical approach of reinforcement learning, but we would like to make it better. An algorithm should be adaptive to changes in the environment (like changing the size of the ball, the rules or geometry of the environment), learn much faster and be more similar to how animals learn. We are not stupid, but we could not do it. Either, the task is much harder than we thought or we were solving the wrong question. Nevertheless, I continued diving deeper into the theory.
On the map, I put theory purposefully to the bottom, because it is fundamental for everything else. It includes math, particularly linear algebra and combinatorics. Probability theory and statistics gave birth to statistical learning theory, which someday may become that fundamental theory of machine learning. Still, I could not fully grasp it, either it is very profound or just a special case that will hardly send any ripples to the upcoming theory. The theory of optimization pierces every domain, many thick books dedicated to it, and it forms the basis for many algorithms in machine learning, neuroscience and data compression. The theory of computation is also very valuable and deals with the transformation of data. The Turing machine is abstract but still essential to understand. Cellular automata more known from the “Game of Life” by Conway is undervalued in the AI community. It shows that the simple rules of interaction create very complicated patterns. Very plausible, that in the end, it appears that neurons work by relatively simple rules, and together, millions of them self-organize and give rise to meaningful behavior for an animal.
Cellular automata is related to yet another concept — computational irreducibility. There are things in nature that can be easily predicted knowing the laws. For example, put the initial velocity and the angle of the ball to the formula and you know its future trajectory, when and where it falls, before it falls. But there are such phenomena that cannot be described by a simple formula (no closed-form solution) and you need to simulate dynamics on a computer. For example, a three-body problem in physics (like the movement of the Sun, Earth and Moon) is described by differential equations but there is no simple expression of a solution that could predict (compute) the future.
Computational irreducibility tells exactly that — some things inherently are not easily predictable and require more computation. The same applies to neural networks — no formula predicts a neuron behavior after an hour. You need to simulate all 3600 seconds for it. This intersects with the philosophy, more precisely with free will. If no program could predict your actions, then no one knows in advance what you will do. So, do you have the freedom to choose, or are you still bound by laws of activation and learning of 100 billion neurons?
I draw the map in the shape of the brain, and I put philosophy in the place of the cerebellum. Humans can remain conscious and live without the cerebellum, though motor command and cognitive agility are very impaired. The same with philosophy, you can live without it, but still, it gives a value. Perhaps, the majority of scientists in AI, consciously or not, pertain to functionalism. It is an idea that two material systems are equivalent if they give the same outputs for the same inputs, even if inside they are totally different. If we could create an artificial neural network (silicone-based) that is equivalent to a biological one, then we could build a first substrate-independent form of life. This echoes with the central problem in philosophy — the problem of consciousness. Will the equivalent material system ever be conscious? What does it mean to be conscious? How would we know looking at the activation of artificial (and even biological) neurons if there is consciousness? Maybe this question is wrong, and it should sound differently?
The presented map does not cover all keywords in the AI field. It is just a snapshot of my current mental model (as of the end of 2020). This is the first version, and I am still learning. Still, I hope even this version will be interesting to many. Also, I did not cover all words on the map. Later, I will write more in-depth about the most important of it. If you have any proposals or criticism, I will highly appreciate your comments.