Federated Learning: The Future of Distributed Machine Learning
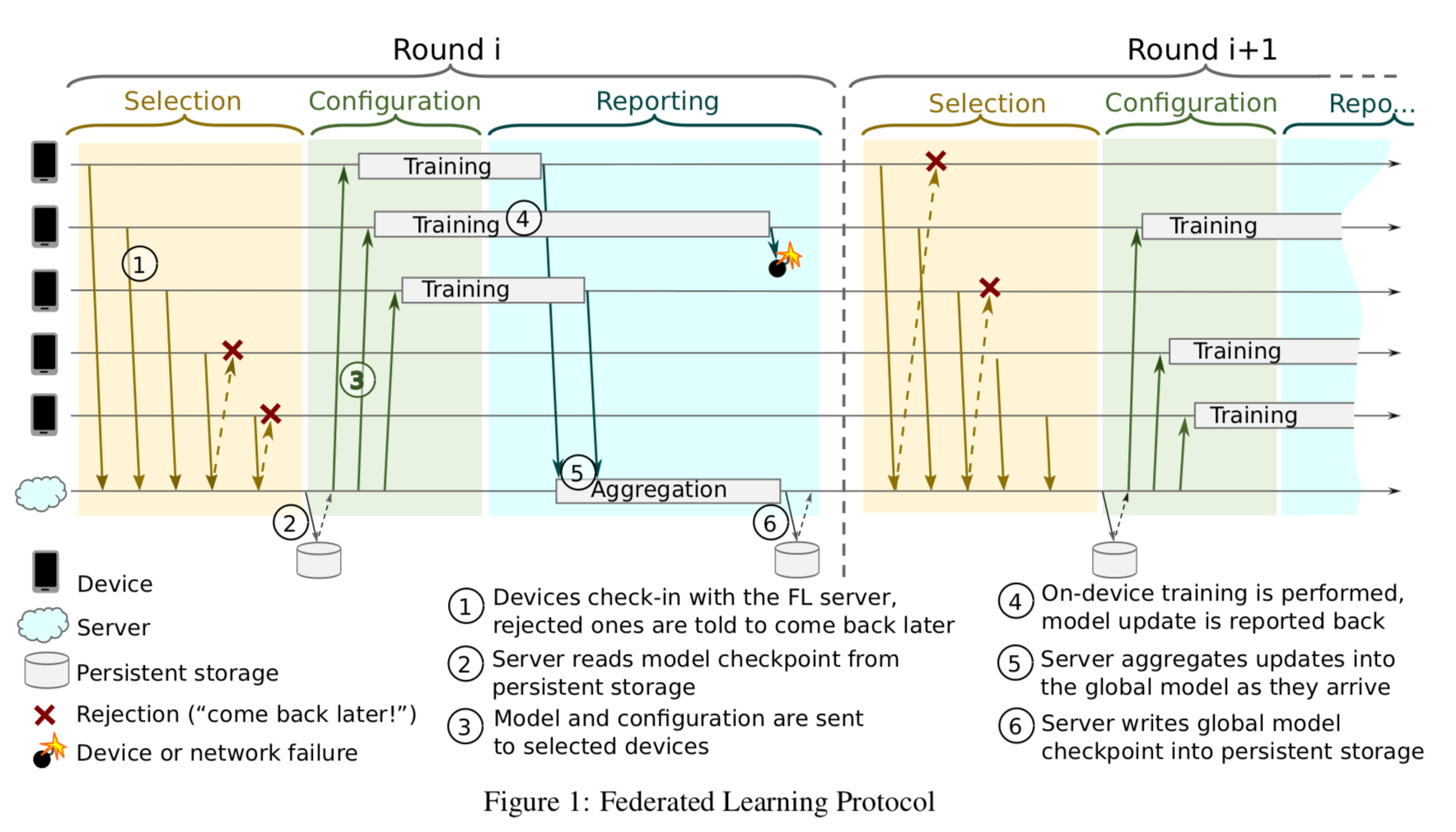
In 2017 Google introduced Federated Learning (FL), “a specific category of distributed machine learning approaches which trains machine learning models using decentralized data residing on end devices such as mobile phones.” A new Google paper has now proposed a scalable production system for federated learning to enable increasing workload and output through the addition of resources such as compute, storage, bandwidth, etc.
The Google paper also addresses various FL challenges, solutions and future prospects.
“Federated Learning is a distributed machine learning approach which enables model training on a large corpus of decentralized data. We have built a scalable production system for Federated Learning in the domain of mobile devices, based on TensorFlow. In this paper, we describe the resulting high-level design, sketch some of the challenges and their solutions, and touch upon the open problems and future directions”. (arXiv).
Synced invited Michigan State University Professor Mi Zhang, who focuses on machine learning systems, to share his thoughts on Federated Learning.
Why does this tech matter?
To train a machine learning model, traditional machine learning adopts a centralized approach which requires the training data to be aggregated on a single machine or in a datacenter. This is practically what giant AI companies such as Google, Facebook, and Amazon have been doing over the years. These companies have been collecting a gigantic amount of data and store these data in their datacenters where machine learning models are trained. This centralized training approach, however, is privacy-intrusive, especially for mobile phone users. This is because mobile phones may contain the owners’ privacy-sensitive data. To train or obtain a better machine learning model under such a centralized training approach, mobile phone users have to trade their privacy by sending their personal data stored inside phones to the clouds owned by the AI companies.
Compared to the centralized training approach, federated learning is a decentralized training approach which enables mobile phones located at different geographical locations to collaboratively learn a machine learning model while keeping all the personal data that may contain private information on device. In such a case, mobile phone users can benefit from obtaining a well-trained machine learning model without sending their privacy-sensitive personal data to the cloud.
What impact might this bring to the AI community?
Federated learning opens up a brand new research field in AI. Today, gigantic amounts of data are generated by consumer devices such as mobile phones on a daily basis. These data contain valuable information about users and their personal preferences: what websites they mostly visited, what social media apps they mostly used, what types of videos they mostly watched, etc. With such valuable information, these data become the key to building better and personalized machine learning models to deliver personalized services to maximally enhance user experiences. Federated learning provides a unique way to build such personalized models without intruding users’ privacy. Such a unique advantage is the key motivation to attract researchers in the AI community to work on this new research direction.
Federated learning also opens up a brand new computing paradigm for AI. As compute resources inside end devices such as mobile phones are becoming increasingly powerful, especially with the emergence of AI chipsets, AI is moving from clouds and datacenters to end devices. Federated learning provides a privacy-preserving mechanism to effectively leverage those decentralized compute resources inside end devices to train machine learning models. Considering that there are billions of mobile devices worldwide, the compute resources accumulated from those mobile devices are way beyond the reach of the largest datacenter in the world. In this sense, federated learning has the potential to disrupt cloud computing, the dominant computing paradigm today.
Can you identify any bottlenecks?
Federated learning is confronted by two key challenges. One of the challenges is communication bandwidth. Federated learning on mobile phones relies on wireless communication to collaboratively learn a machine learning model. Although compute resources of mobile phones are becoming increasingly powerful, the bandwidth of wireless communication has not increased as much. As such, the bottleneck is shifted from computation to communication. As a consequence, limited communication bandwidth could incur long communication latency, and thus could significantly slow down the convergence time of the federated learning process.
Another challenge that federated learning needs to address is the reliability of end devices which participate in the federated learning process. Federated learning is an iterative process, it relies on the participating end devices to continuously communicate over iterations until the learning process converges. However, in real-world deployments, due to various practical reasons, not all end devices may fully participate in the complete iterative process from beginning to end. For end devices which drop out in the middle of the federated learning process, their data cannot be fully utilized during the learning process. As such, the learning quality of federated learning could be considerably jeopardized.
Could you predict any potential future trends related to this tech?
Federated learning is revolutionizing how machine learning models are trained. Google has just released their first production-level federated learning platform, which will spawn many federated learning-based applications such as on-device item ranking, next-word prediction, and content suggestion. In the future, machine learning models can be trained without counting on the compute resources owned by giant AI companies. And users will not need to trade their privacy for better services.
The paper Towards Federated Learning at Scale: System Design is on arXiv.

About Prof. Mi Zhang
Mi Zhang is an Assistant Professor of Electrical and Computer Engineering and Computer Science and Engineering at Michigan State University where he directs the Systems for Machine Intelligence (SysML) Lab. Prof. Zhang received his Ph.D. from University of Southern California and B.S. from Peking University. His research lies at the intersection of computer systems and machine intelligence, spanning areas including mobile/edge computing, deep learning systems, distributed systems, Internet of Things, and mobile health. His work has been reported on and highlighted by leading national and international media such as MIT Technology Review, WIRED, TechCrunch, New Scientist, TIME, CNN, ABC, NPR, The Washington Post, Smithsonian Magazine, and The Wall Street Journal.
Synced Insight Partner Program
The Synced Insight Partner Program is an invitation-only program that brings together influential organizations, companies, academic experts and industry leaders to share professional experiences and insights through interviews and public speaking engagements, etc. Synced invites all industry experts, professionals, analysts, and others working in AI technologies and machine learning to participate.
Simply Apply for the Synced Insight Partner Program and let us know about yourself and your focus in AI. We will give you a response once your application is approved.
2018 Fortune Global 500 Public Company AI Adaptivity Report is out!
Purchase a Kindle-formatted report on Amazon.
Apply for Insight Partner Program to get a complimentary full PDF report.

Follow us on Twitter @Synced_Global for daily AI news!
We know you don’t want to miss any stories. Subscribe to our popular Synced Global AI Weekly to get weekly AI updates.