InSync ComputingbySync ComputingData Lake vs. Data Warehouse vs. Data LakehouseA look into the strengths and weaknesses of leading data storage solutionsNov 8
AgusmahariPySpark : Step-by-Step Guide to Installing PySpark on LinuxPySpark, a Python library for Apache Spark, allows developers to harness the power of distributed computing and big data processing.Jul 4, 20231
Parag JainSnowflake streaming data ingestion with Snowpipe Streaming API and External Oauth integration…With Amir Durrani & Parag JainNov 5Nov 5
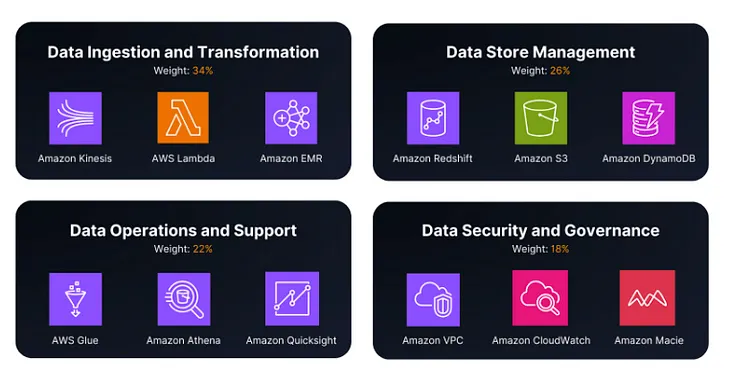
InTowards AWSbyVishal MishraHow did I Pass the AWS Data Engineer Associate exam in 2024?Achieving Success: My Journey to AWS Certified Data Engineer AssociateJun 271Jun 271
casimirrex antonyComprehensive Data Engineering Ecosystem**1. Infrastructure and Containerization:**Jul 20Jul 20
InSync ComputingbySync ComputingData Lake vs. Data Warehouse vs. Data LakehouseA look into the strengths and weaknesses of leading data storage solutionsNov 8
AgusmahariPySpark : Step-by-Step Guide to Installing PySpark on LinuxPySpark, a Python library for Apache Spark, allows developers to harness the power of distributed computing and big data processing.Jul 4, 20231
Parag JainSnowflake streaming data ingestion with Snowpipe Streaming API and External Oauth integration…With Amir Durrani & Parag JainNov 5
InTowards AWSbyVishal MishraHow did I Pass the AWS Data Engineer Associate exam in 2024?Achieving Success: My Journey to AWS Certified Data Engineer AssociateJun 271
casimirrex antonyComprehensive Data Engineering Ecosystem**1. Infrastructure and Containerization:**Jul 20
jennyI spent 5 hours studied about DuckDB, here’s what I foundAs a data enthusiast always on the lookout for innovative tools, DuckDB has been caught my eyes recently. Impressed by its popularity (20k+…Jul 16
Alireza SadeghiTechniques for Managing Dependency Between Data PipelinesIt’s a common challenge to manage dependency between data pipelines on data-driven systems and analytical platforms which having data…Aug 29, 2023