Evelyn ChungA Deep Dive Into Creating a CNN with Distributed TrainingWhy Use Distributed Training?Nov 30
Minyang ChenMulti-GPU Training for Llama 3.2 using DeepSpeed and Redundancy Optimizer (ZeRO)For inference tasks, it’s preferable to load entire model onto one GPU, containing all necessary parameters, to carry out these tasks…Oct 1
Change LeadershipWhy Distributed Training is the Key to Unlocking AI’s Full PotentialAI models are hitting a wall — and it’s time to break through. You’ve probably felt it: your models are bigger and more complex, but…Nov 26Nov 26
Sulaiman ShamasnaDistributed Model TrainingDistributed model training, mainly applicable for Deep Learning, combines distributed system principles with machine learning techniques to…Jul 161Jul 161
Ryan TallmadgeTraining Models at Scale: A Deep Dive into Distributed ML CodeDistributed training is like planning a potluck dinner with a group of friends: everyone brings a dish (or in this case, contributes to the…Nov 211Nov 211
Evelyn ChungA Deep Dive Into Creating a CNN with Distributed TrainingWhy Use Distributed Training?Nov 30
Minyang ChenMulti-GPU Training for Llama 3.2 using DeepSpeed and Redundancy Optimizer (ZeRO)For inference tasks, it’s preferable to load entire model onto one GPU, containing all necessary parameters, to carry out these tasks…Oct 1
Change LeadershipWhy Distributed Training is the Key to Unlocking AI’s Full PotentialAI models are hitting a wall — and it’s time to break through. You’ve probably felt it: your models are bigger and more complex, but…Nov 26
Sulaiman ShamasnaDistributed Model TrainingDistributed model training, mainly applicable for Deep Learning, combines distributed system principles with machine learning techniques to…Jul 161
Ryan TallmadgeTraining Models at Scale: A Deep Dive into Distributed ML CodeDistributed training is like planning a potluck dinner with a group of friends: everyone brings a dish (or in this case, contributes to the…Nov 211
Siddhartha ShresthaFinetuning Llama 3.2 11B vision model using FSDPIn my last blog, I discussed the introduction to FSDP to give a high-level overview of what FSDP provides. You can go through it: hereOct 17
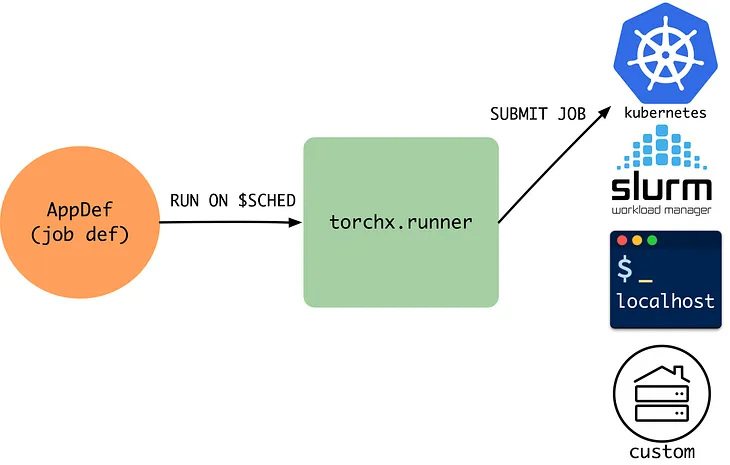
Filip MelbergDistributed training with PyTorch Lightning, TorchX and KubernetesIn this tutorial we will split the training process of an autoencoder model between two different machines to reduce training time.Oct 27
InKensho BlogbyDogacan ColakDistributed Training with KubernetesNeural networks are more relevant than ever with the rise of GenAI, in particular large language models, and at Kensho we’ve been…Mar 112