Gleb LukicovML pipelines in the age of LLMs: from local containers to cloud experimentsEnd-to-end pipelines with Docker, Poetry, Kubeflow, Vertex AI on Google Cloud, and Experiment Tracking.1d ago
InAI AdvancesbyBernd WesselyWhy AI/ML Software Development Must Operate at Production-Level StandardsNew AI/ML applications force us to rethink how we organize DevOps and MLOpsNov 75
InTowards Data SciencebyJohn HawkinsTraining Language Models on Google ColabA guide to iterative fine-tuning and serialisationDec 42Dec 42
Muhammad Anang MahrubLearn MLOps on Google Cloud: Deploy Flask App using Artifact and Cloud Run.At the end of 2024, I decided to learn MLOps on Google Cloud. I bought a course from Udemy about MLOps on Google Cloud and started to…17h ago17h ago
InTowards Data SciencebyChayma ZatoutFrom AI Canvas to MLOps Stack Canvas: Are They Essential?The AI, ML and MLOps stack canvases, explained with examplesOct 245Oct 245
Gleb LukicovML pipelines in the age of LLMs: from local containers to cloud experimentsEnd-to-end pipelines with Docker, Poetry, Kubeflow, Vertex AI on Google Cloud, and Experiment Tracking.1d ago
InAI AdvancesbyBernd WesselyWhy AI/ML Software Development Must Operate at Production-Level StandardsNew AI/ML applications force us to rethink how we organize DevOps and MLOpsNov 75
InTowards Data SciencebyJohn HawkinsTraining Language Models on Google ColabA guide to iterative fine-tuning and serialisationDec 42
Muhammad Anang MahrubLearn MLOps on Google Cloud: Deploy Flask App using Artifact and Cloud Run.At the end of 2024, I decided to learn MLOps on Google Cloud. I bought a course from Udemy about MLOps on Google Cloud and started to…17h ago
InTowards Data SciencebyChayma ZatoutFrom AI Canvas to MLOps Stack Canvas: Are They Essential?The AI, ML and MLOps stack canvases, explained with examplesOct 245
Dr Sokratis KartakisGenAIOps: Operationalize Generative AI - A Practical GuideMove from idea to production using GenAI and Operations (GenAIOps)6d ago4
Siddharth SinghMLOPS Day 7: Building and Containerizing an End-to-End Machine Learning PipelineToday marks an important milestone in the journey of building a robust, automated, and scalable Machine Learning (ML) pipeline. The goal…10h ago
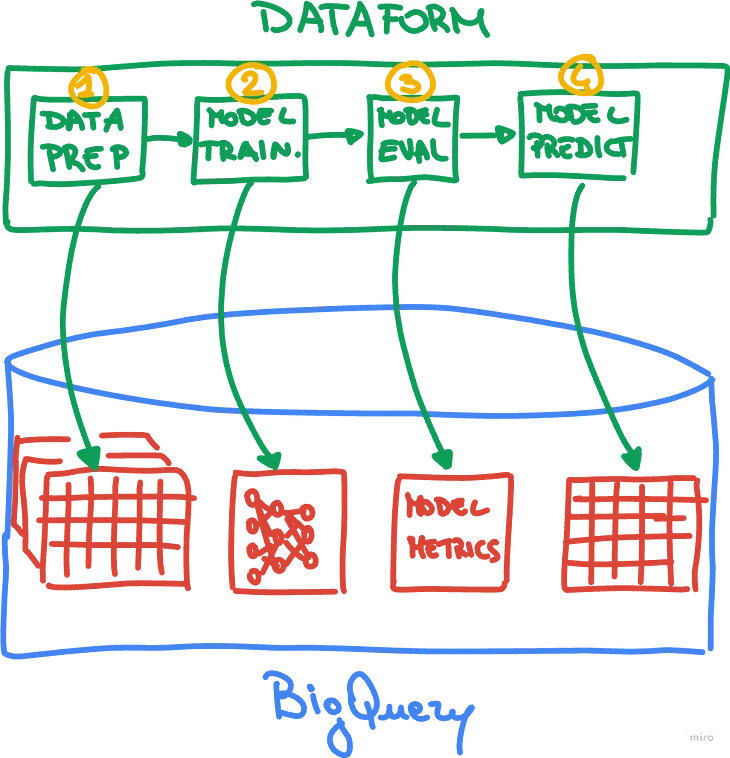
InGoogle Cloud - CommunitybyMirko GilioliMLOps made easy with Dataform & BigQuery ML— Part 1Introduction:Oct 142