Peiyuan Chien (Chris)Train AI Models More Efficiently?! Insight from MLPerf AI BenchmarkAI Benchmark Paper SeriesFeb 27
Yifeng JiangBenchmarking Storage for AI WorkloadsChoose the right storage for your AI infrastructureJan 19
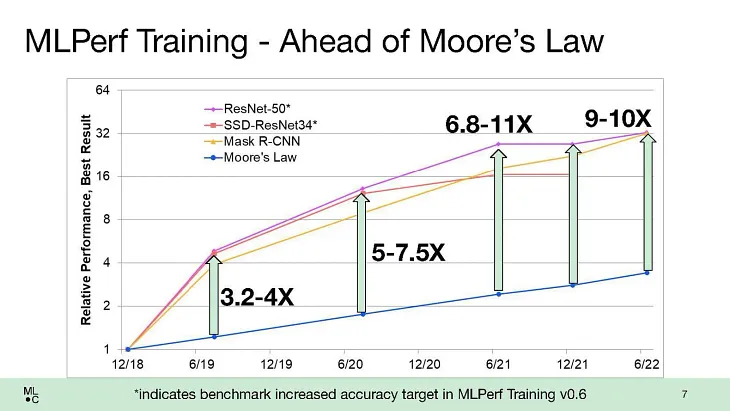
Jonathan Bown⚡💻 Outpacing Moore’s Law: The AI Performance Surge 🚀📈Is it just me or does AI performance seem to be skyrocketing in the last two years?Jun 7, 20231Jun 7, 20231
InAnalytics VidhyabyRamesh RadhakrishnanMLPerf: Getting your feet wet with benchmarking ML workloadsIn this article we will go through the steps involved in setting up and running one of the MLPerf training benchmarks. This will provide…Nov 24, 20191Nov 24, 20191
Yuanzhe DongUsing CUDA Graph in PytorchCUDA Graph is a feature to reduce training time. Instead of launching kernels one by one with all the CPU launching overheads for each…Dec 27, 2022Dec 27, 2022
Peiyuan Chien (Chris)Train AI Models More Efficiently?! Insight from MLPerf AI BenchmarkAI Benchmark Paper SeriesFeb 27
Yifeng JiangBenchmarking Storage for AI WorkloadsChoose the right storage for your AI infrastructureJan 19
Jonathan Bown⚡💻 Outpacing Moore’s Law: The AI Performance Surge 🚀📈Is it just me or does AI performance seem to be skyrocketing in the last two years?Jun 7, 20231
InAnalytics VidhyabyRamesh RadhakrishnanMLPerf: Getting your feet wet with benchmarking ML workloadsIn this article we will go through the steps involved in setting up and running one of the MLPerf training benchmarks. This will provide…Nov 24, 20191
Yuanzhe DongUsing CUDA Graph in PytorchCUDA Graph is a feature to reduce training time. Instead of launching kernels one by one with all the CPU launching overheads for each…Dec 27, 2022
InTowards Data SciencebyDr Anton LokhmotovDemystifying MLPerf InferenceThe MLPerf community is enabling fair and objective benchmarking of ML workloads. What does it mean for Inference (and for you)?May 5, 2020
InTowards Data SciencebyDr. Mario Michael KrellAccelerating ResNet-50 Training on the IPU: Behind our MLPerf BenchmarkA technical guide on efficient hardware scaling, memory optimization strategies and performance toolsJan 13, 2022
InAccelAccelerated Inference on FPGA clusters using InAccel: MLPerf resultsEvaluating the best hardware platform for your deep learning application can sometimes be challenging. Also, the marketing numbers…Oct 23, 2020