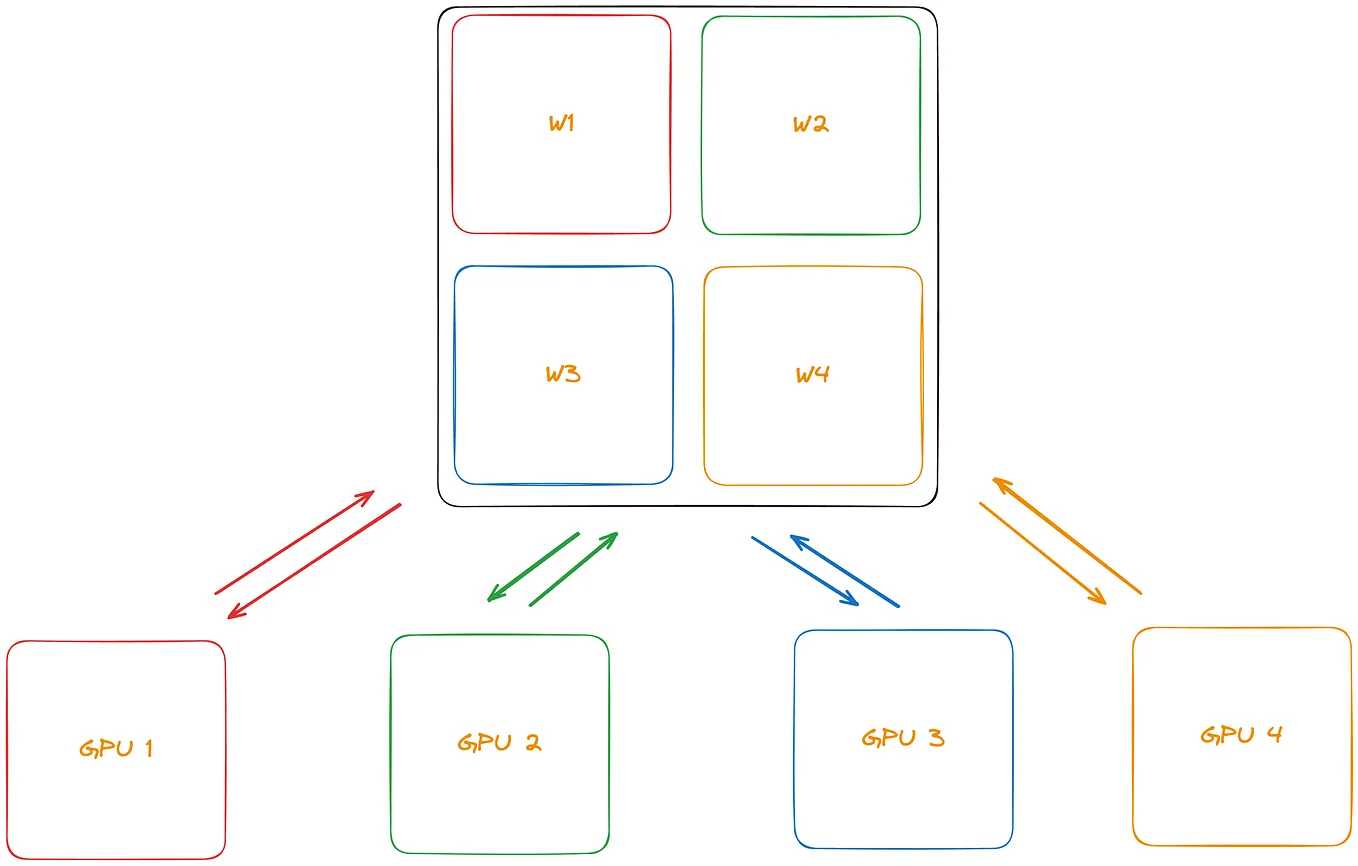
DivyamDifferent Parallelisms in the World of Distributed Systems for Model TrainingFor your ChatGPT or Claude to work, the distributed system has to not just do all the processing grunt work, but it even gets parallel-ized…18h ago
Luhui HuinTowards Data ScienceDistributed Parallel Training: Data Parallelism and Model ParallelismHow to scale out training large models like GPT-3 & DALL-E 2 in PyTorchSep 18, 20221Sep 18, 20221
Subrata GoswamiUnder the Hood of Llama 3.1 70B Distributed InferenceThe following are some notes on how the Llama 3.1 70B model works in distributed environment. Will focus only on the pure PyTorch…Sep 3Sep 3
DivyamDifferent Parallelisms in the World of Distributed Systems for Model TrainingFor your ChatGPT or Claude to work, the distributed system has to not just do all the processing grunt work, but it even gets parallel-ized…18h ago
Luhui HuinTowards Data ScienceDistributed Parallel Training: Data Parallelism and Model ParallelismHow to scale out training large models like GPT-3 & DALL-E 2 in PyTorchSep 18, 20221
Subrata GoswamiUnder the Hood of Llama 3.1 70B Distributed InferenceThe following are some notes on how the Llama 3.1 70B model works in distributed environment. Will focus only on the pure PyTorch…Sep 3
Haseeb Ullah Khan ShinwariUnlocking the Power of Distributed Training: Scaling Deep Learning for Massive DatasetsJul 15
Pranay JanupalliUnderstanding Model Sharding and Model Parallelism: Scaling Large Language ModelsIn the realm of large-scale models, particularly large language models (LLMs), managing memory and computational resources efficiently is a…Jul 7
Pranjal KhadkaProblem with training large neural networks and solutions devised over the yearsNeural networks are being used extensively today around the world to solve complex problems in different domains. In the recent years…Jun 61