IndatamindedbebyNiels ClaeysRunning thousands of Spark applications without losing your coolI explain how to troubleshoot and detect problematic Spark applications at scale as well as show how this can be used to reduce your costs.23h ago
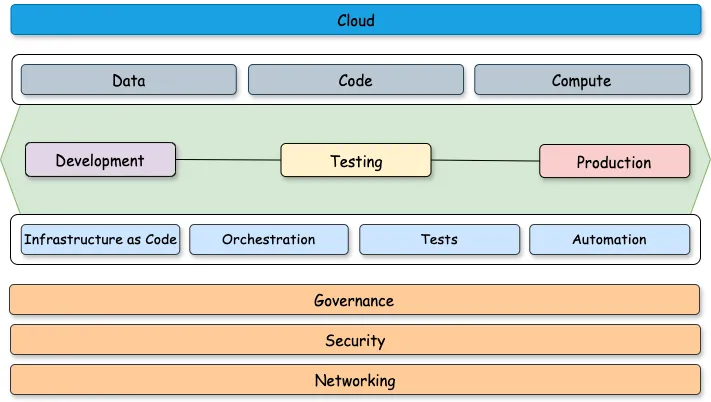
InData Engineer ThingsbyEduard PopaA Practitioner’s Guide to Developing Data Engineering Solutions with DatabricksDevelopment Approaches, Environments, CI/CD and Testing with DatabricksJul 267
InData Engineer ThingsbyYingjun WuKafka Has Reached a Turning PointIs Kafka still relevant in today’s evolving tech landscape? And where is Kafka headed in the future?Sep 2311Sep 2311
InCodeXbyMuttineni Sai RohithUnderstanding PySpark’s Catalyst Optimizer: Advanced Techniques for Query ExecutionIn the world of big data, efficiency is paramount. PySpark has become a cornerstone for data engineers dealing with large-scale data…20h ago20h ago
InData Engineer ThingsbyGeorge ZefkilisBuilding a Local Data Lake from scratch with MinIO, Iceberg, Spark, StarRocks, Mage, and DockerHello again, fellow technology enthusiasts! I am a software/data engineer who transitioned from data science. The learning curve in this…Jul 137Jul 137
IndatamindedbebyNiels ClaeysRunning thousands of Spark applications without losing your coolI explain how to troubleshoot and detect problematic Spark applications at scale as well as show how this can be used to reduce your costs.23h ago
InData Engineer ThingsbyEduard PopaA Practitioner’s Guide to Developing Data Engineering Solutions with DatabricksDevelopment Approaches, Environments, CI/CD and Testing with DatabricksJul 267
InData Engineer ThingsbyYingjun WuKafka Has Reached a Turning PointIs Kafka still relevant in today’s evolving tech landscape? And where is Kafka headed in the future?Sep 2311
InCodeXbyMuttineni Sai RohithUnderstanding PySpark’s Catalyst Optimizer: Advanced Techniques for Query ExecutionIn the world of big data, efficiency is paramount. PySpark has become a cornerstone for data engineers dealing with large-scale data…20h ago
InData Engineer ThingsbyGeorge ZefkilisBuilding a Local Data Lake from scratch with MinIO, Iceberg, Spark, StarRocks, Mage, and DockerHello again, fellow technology enthusiasts! I am a software/data engineer who transitioned from data science. The learning curve in this…Jul 137
Ritam MukherjeeBuilding Real-Time ETL Pipelines with Flink? Here’s How You Can Nail It!All you need to know to get started with Flink ETL.10h ago
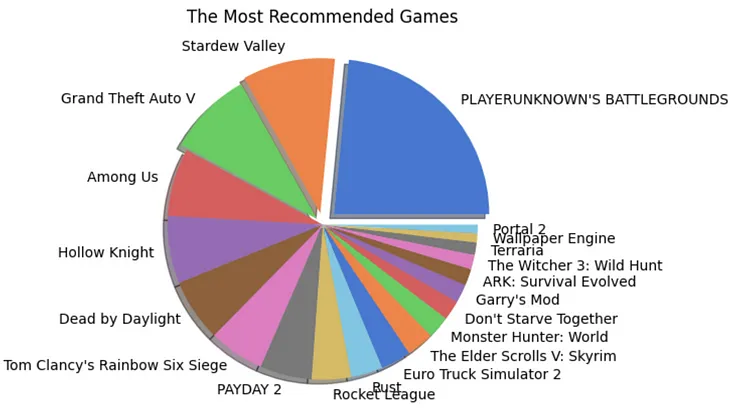
InTowards Data SciencebyRindhuja Treesa JohnsonApache Hadoop and Apache Spark for Big Data AnalysisA complete guide to big data analysis using Apache Hadoop (HDFS) and PySpark library in Python on game reviews on the Steam gaming…May 81