InAIGuysbyVishal RajputVisual Reasoning for LLMs (VLMs)Latest research in Vision Language Models.5d ago
InTowards Data SciencebyLihi Gur Arie, PhDFlorence-2: Advancing Multiple Vision Tasks with a Single VLM ModelA Guided Exploration of Florence-2's Zero-Shot Capabilities: Captioning, Object Detection, Segmentation and OCR.Oct 144
InTowards Data SciencebyLihi Gur Arie, PhDChat with Your Images using Multimodal LLMsLearn how to build Llama 3.2-Vision locally in a chat-like mode, and explore its Multimodal skills on a Colab notebookDec 52Dec 52
InGenerative AIbyMd Monsur aliHow to Use PaliGemma 2 for Multimodal AI Tasks: A Hands-On Tutorial for Image Captioning and MoreLearn how to generate accurate captions with PaliGemma 2 in this step-by-step guide. Discover image processing and model inference for…Dec 7Dec 7
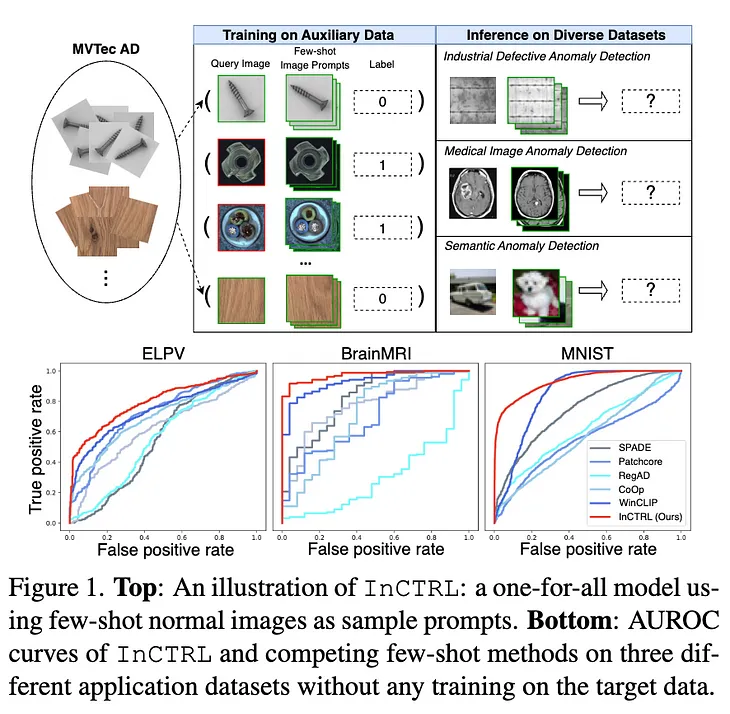
InTowards Data SciencebyGuansong PangLearning Generalist Models for Anomaly DetectionGeneralist Anomaly Detection (GAD) aims to train one single detection model that can generalize to detect anomalies in diverse datasets…Apr 14Apr 14
InAIGuysbyVishal RajputVisual Reasoning for LLMs (VLMs)Latest research in Vision Language Models.5d ago
InTowards Data SciencebyLihi Gur Arie, PhDFlorence-2: Advancing Multiple Vision Tasks with a Single VLM ModelA Guided Exploration of Florence-2's Zero-Shot Capabilities: Captioning, Object Detection, Segmentation and OCR.Oct 144
InTowards Data SciencebyLihi Gur Arie, PhDChat with Your Images using Multimodal LLMsLearn how to build Llama 3.2-Vision locally in a chat-like mode, and explore its Multimodal skills on a Colab notebookDec 52
InGenerative AIbyMd Monsur aliHow to Use PaliGemma 2 for Multimodal AI Tasks: A Hands-On Tutorial for Image Captioning and MoreLearn how to generate accurate captions with PaliGemma 2 in this step-by-step guide. Discover image processing and model inference for…Dec 7
InTowards Data SciencebyGuansong PangLearning Generalist Models for Anomaly DetectionGeneralist Anomaly Detection (GAD) aims to train one single detection model that can generalize to detect anomalies in diverse datasets…Apr 14
Gautam ChutaniMulti-Modal RAG: A Practical GuideUsing vLLM to serve models for Multimodal Text Summarization, Table Processing, and Answer SynthesisSep 17
Gautam ChutaniFine-Tuning Vision-Language Models using LoRAUsing Unsloth for fine-tuning with Weights & Biases integration for experiment trackingNov 29
InTowards Data SciencebyScott Campit, Ph.D.Exploring “Small” Vision-Language Models with TinyGPT-VTinyGPT-V is a “small” vision-language model that can run on a single GPU.Jan 123