Raj PatelLoad data from GCS to BigTable with GCP Dataproc ServerlessRecently, I have a need to transfer data from Google Cloud Storage (GCS) into Bigtable by utilizing Dataproc Serverless Spark. The…3d ago
Eduard PopainData Engineer ThingsA Practitioner’s Guide to Developing Data Engineering Solutions with DatabricksDevelopment Approaches, Environments, CI/CD and Testing with DatabricksJul 267
Yingjun WuKafka Has Reached a Turning PointIs Kafka still relevant in today’s evolving tech landscape? And where is Kafka headed in the future?Sep 238Sep 238
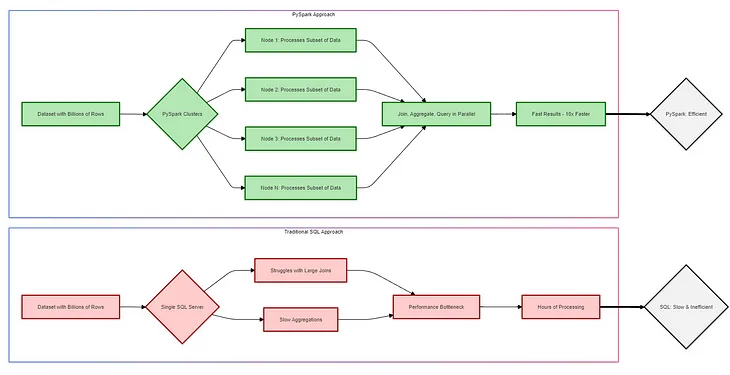
Christopher ShehuUnlocking Big Data Potential: How PySpark Surpasses Classic SQLNote: This guide will cover both PySpark (Python-based API) and Spark SQL to showcase examples of both approaches and their respective…4d ago4d ago
George ZefkilisinData Engineer ThingsBuilding a Local Data Lake from scratch with MinIO, Iceberg, Spark, StarRocks, Mage, and DockerHello again, fellow technology enthusiasts! I am a software/data engineer who transitioned from data science. The learning curve in this…Jul 136Jul 136
Raj PatelLoad data from GCS to BigTable with GCP Dataproc ServerlessRecently, I have a need to transfer data from Google Cloud Storage (GCS) into Bigtable by utilizing Dataproc Serverless Spark. The…3d ago
Eduard PopainData Engineer ThingsA Practitioner’s Guide to Developing Data Engineering Solutions with DatabricksDevelopment Approaches, Environments, CI/CD and Testing with DatabricksJul 267
Yingjun WuKafka Has Reached a Turning PointIs Kafka still relevant in today’s evolving tech landscape? And where is Kafka headed in the future?Sep 238
Christopher ShehuUnlocking Big Data Potential: How PySpark Surpasses Classic SQLNote: This guide will cover both PySpark (Python-based API) and Spark SQL to showcase examples of both approaches and their respective…4d ago
George ZefkilisinData Engineer ThingsBuilding a Local Data Lake from scratch with MinIO, Iceberg, Spark, StarRocks, Mage, and DockerHello again, fellow technology enthusiasts! I am a software/data engineer who transitioned from data science. The learning curve in this…Jul 136
Naveen KumarTuning Spark Optimization: A Guide to Efficiently Processing 1 TB DataThe aim of this article is to provide a practical guide on how to tune Spark for optimal performance, focusing on partitioning strategy…Oct 3
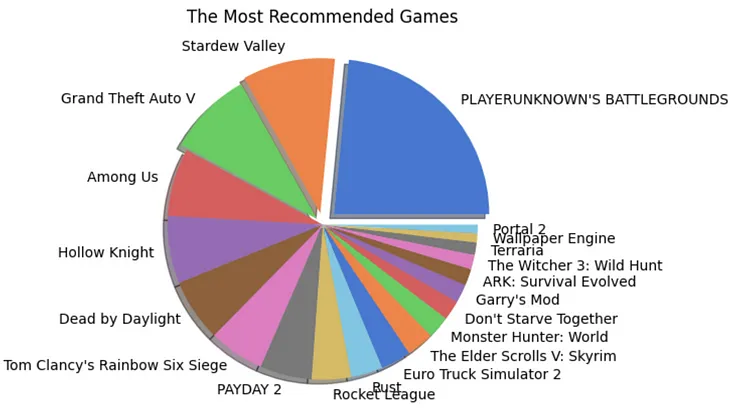
Rindhuja Treesa JohnsoninTowards Data ScienceApache Hadoop and Apache Spark for Big Data AnalysisA complete guide to big data analysis using Apache Hadoop (HDFS) and PySpark library in Python on game reviews on the Steam gaming…May 81
Yingjun WuApache Iceberg: Built for Big Data, Ready for Small?Originally built for massive data lakes, Apache Iceberg is catching the attention of small teams. But can it really fit?Sep 265