A-to-Z of Blockchain Consensus

Co-authored by Julian Koh & Cheryl Sew Hoy
Blockchain consensus was one of the most heavily discussed sub-fields of blockchains throughout 2017 and 2018. We saw a bunch of companies try to compete with Ethereum by building new smart contract platforms from scratch, where the main differentiator/innovation was the consensus algorithm underlying these blockchains. Trying to understand these algorithms and being able to critically compare them was a full-time job for many crypto investors — they are by no means simple to grasp. There have been many efforts to demystify these magic ‘consensus algorithms’, but many of these still end up too technical for most people. Some concepts like synchrony, safety/liveness proofs, and impossibility results are instrumental in seeing the full picture, but are in my opinion not particularly important for most people to fully understand. This blog post will focus squarely on consensus algorithms in blockchain-land, without much mention of the larger (and super complex!) field of Distributed Systems. There will also be some hand-waving over technical concepts for the sake of simplicity and understandability.
By the end of this post, you should be able to understand the differences between Proof-of-Work and Proof-of-Stake, what “BFT” means, and most importantly, what the main trade-offs are when considering which blockchain to build your application on.
What Is Consensus, And Why Does It Matter?
A blockchain is, simply put, a public database where users agree on what is correct. Bitcoin is a public database of all the transactions that have ever happened, preserving the integrity of the money system. There are two main questions that we need to ask to understand how this works:
- What do we agree on?
- How do we come to an agreement?
We need someone to propose something, then have a way for everyone else to choose until there is some form of agreement. In the case of blockchains, we need someone to propose a block, and we need the rest of the nodes to accept this block.
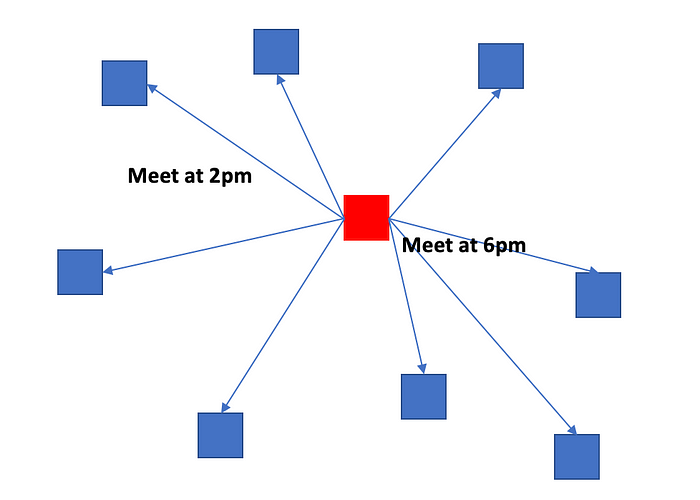
A simple example of this would be the following:

4 people try and schedule a mutual time to catch up. Each person proposes their available times (empty white slots). As we can see, there are 2 mutually available slots: 2pm and 6pm. How do they come to an agreement? Before they proposed their available times, they can agree to a specific rule — everyone must choose the earliest mutually available time. In this case, this means that they will all meet at 2pm instead of 6pm — so they have come to consensus.
Using this framework, we can extend the analogy to the Bitcoin blockchain:
- What do we agree on?
We agree on blocks of data, which contain valid Bitcoin transactions. In Bitcoin, anyone can propose blocks as long as they first solve a hard computer puzzle (Proof-of-Work). - How do we come to an agreement?
We agree to accept blocks which extend the longest chain. For example, if there is chain A of length 100 and chain B of length 200, if you receive a block 101 on chain A and block 201 on chain B, you must accept block 201. Some people may propose a block on a shorter chain because they are not aware of the longer chain, but the “longest chain rule” makes sure that everyone eventually agrees on the same thing once the blocks get propagated throughout the network.
This framework underpins all consensus algorithms. Some algorithms may use a different way of proposing blocks, and some algorithms may use a different way of agreeing on blocks.
Block Proposing
The biggest question that we need to think about regarding block proposing is who gets to propose blocks. If anyone is allowed to propose a block any time, it will be difficult to come to an agreement because it is akin to people talking over each other non-stop. There has to be some way of selecting people such that everyone else can listen to one proposal at a time. The most naive way to do this is to have the protocol randomly select a person for each new block. However, on the internet, one person can pretend to be a hundred people by running a hundred instances of the same program. Hence, we need to create some form of scarcity (“Sybil Resistance”), so that the game cannot be rigged by a single hacker masquerading as a hundred people. This is precisely what Proof-of-Work and Proof-of-Stake get you — a way for computers to be limited by some resource.
Proof-of-Work behaves as follows: to gain the right to propose a block, you must first complete a computationally intensive task. An analog would be having a computer flip a virtual coin until it gets heads 100 times in a row. This is computationally intensive, and there is no way for someone to masquerade as a hundred people, because he is physically constrained by the amount of power his computer has.
However, by employing this “Sybil Resistance” mechanism, people have set up server farms with thousands of computers so that they can out-power their competition and be granted the right to propose blocks. These server farms cost an exorbitant amount of electricity to power, so they are geographically concentrated in countries or zones which have the cheapest access to electricity. So what does it mean for decentralization when a majority of Bitcoin miners are based in China? This geographic centralization poses a real threat to the longevity of the system, as the Chinese government could easily regulate these mining companies.

Proof-of-Stake on the other hand uses a radically different “Sybil Resistance” mechanism. Since it costs money to buy these Bitcoin mining computers and costs money to power them, why don’t we just use money as a way to select block proposers and skip this whole computationally intensive process? Proof-of-Stake is the idea of selecting block proposers based on how much money they have in the system — or the proportion of coins they own in the system. In Proof-of-Work, the more computers you have, the higher your chances are of being selected to propose the next block. In Proof-of-Stake, the more coins you own, the higher your chances are.
Note that we have not talked about agreement on blocks whatsoever. There is a common misconception that Proof-of-Work and Proof-of-Stake are consensus algorithms. They are not. They are merely ways to select block proposers by constraining some scarce resource.
Block Agreements
This is where things get interesting and most of the innovation has happened in the last few years. Once someone has proposed a block, how do we come to agreement? This has been a question computer scientists have been trying to solve since the 80s to build clusters of computers that could sync up even if some crash occasionally. In the 90s, these computer scientists started thinking of an even more difficult problem — what if a hacker could control some of these computers? Were they able to build systems robust enough to ensure that all non-corrupt computers could still come to agreement? This property was dubbed “Byzantine Fault Tolerance” (BFT), which was based off the problem called the Byzantine Generals Problem. BFT systems were a fairly niche topic of study because most systems did not need that level of robustness, since the cluster of computers were usually all owned by a single corporation. Until blockchains.
In blockchains, anyone can run a node (a computer in the cluster) and send other nodes messages or data. This is a really adversarial environment, since malicious actors could pretend to be honest. For example, what if a corrupt computers in a cluster of 10 were sending the other 9 computers conflicting information?
Since good computers are not able to differentiate good from bad, this problem becomes extremely difficult to solve. There have been 2 major families of approaches to solving this problem — Nakamoto Consensus and Classical Consensus.
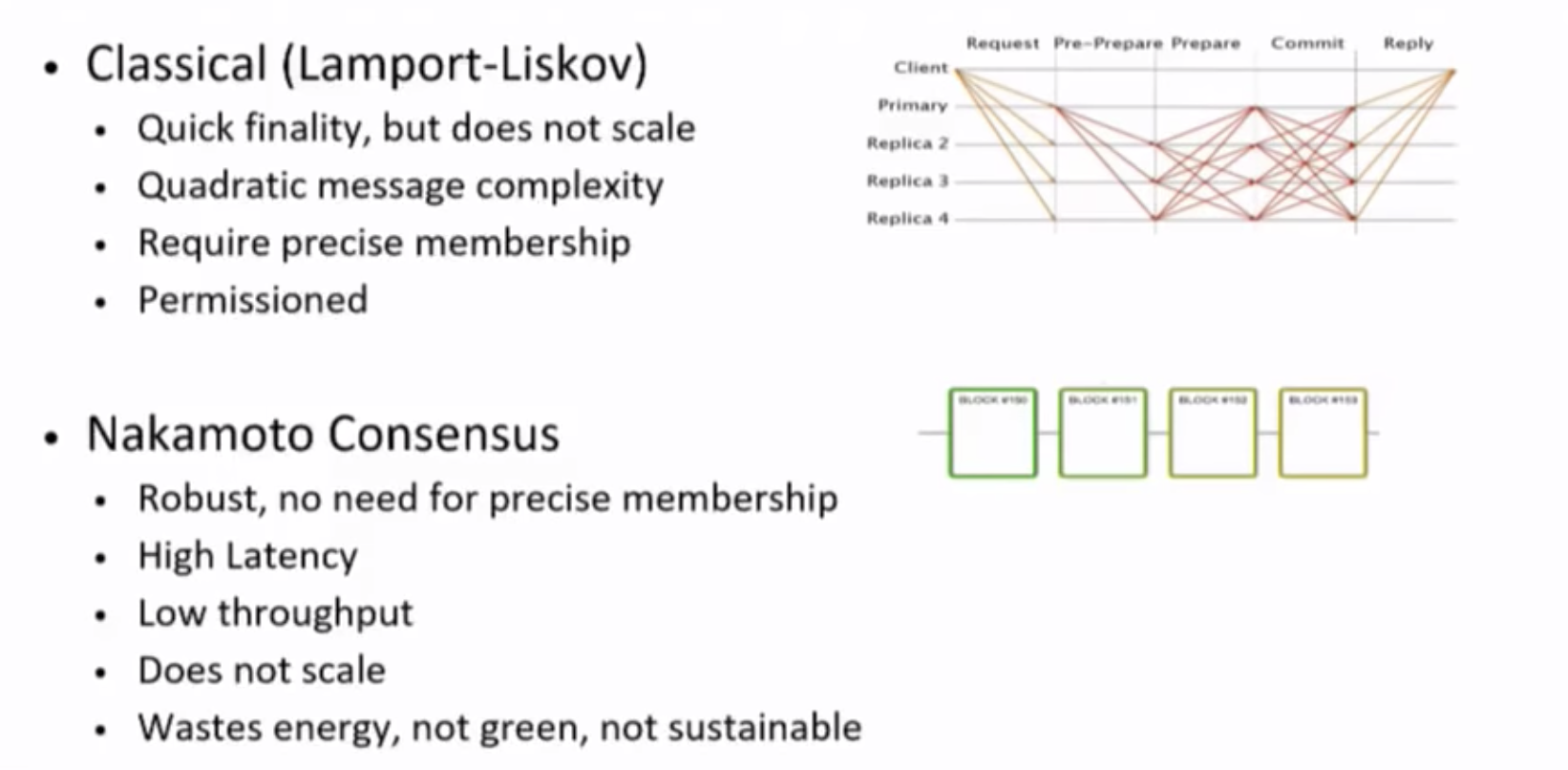
Nakamoto Consensus
Nakamoto Consensus is what is used in Bitcoin and majority of Proof-of-Work systems, pioneered by Satoshi Nakamoto. It is the single rule: “when you see a block proposed that has the most proof-of-work on it, accept it”. Usually, the block with the highest block number will have the most proof-of-work done on it.
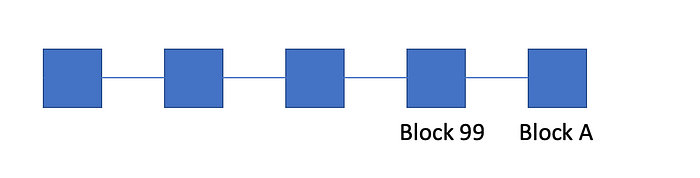
What this means is that you are never 100% sure of whether a block you see is “correct”. For example, the highest block you have seen is block 99. You may receive a block A at height 100, so you accept it.
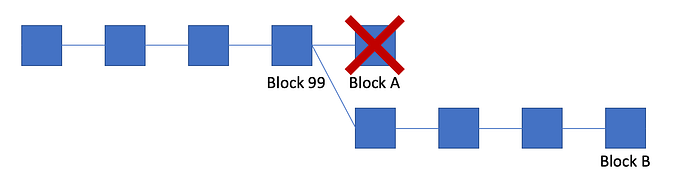
Suddenly, you receive a block B at height 103 which has a different block at height 100. According to the consensus rules, you will need to “reverse” the block A that you previously accepted, and now accept this new history of blocks.
In this system, an attacker who has more than 50% of the system’s overall computing power will be able to consistently build the longest chain, and hence can create whatever blocks they desire. Through this example, we can see that these rules help align people to come to agreement about which chain is the accepted one.
Classical Consensus
Before Nakamoto Consensus was invented in 2009, computer scientists had a different solution to this problem which has a different set of properties. The first consensus algorithm that was Byzantine-Fault Tolerant was an algorithm called Practical Byzantine-Fault Tolerance (I know, what a name). It works by having a set of participants doing multiple rounds of voting until some percentage of voters come to agreement.
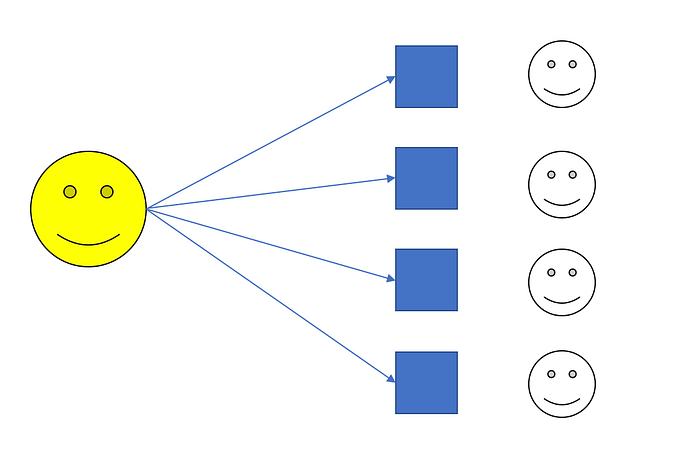
Someone is selected to propose a block, based on something like Proof-of-Stake. He sends the block to the other known participants. The other participants vote.

Since a majority of the participants vote yes on that block, everyone in the system will accept that block as a correct block. Using this type of consensus requires a known set of voters, but once they vote to pass the block, the block becomes final. Hence, there is no such thing as blocks being reversed. If there are disagreements, the system halts instead.
This PBFT algorithm has been adapted to work with blockchains, the most prominent BFT-algorithm for blockchains being Tendermint Core. Tendermint Core was the first consensus algorithm on blockchains that did not use Nakamoto Consensus, but instead built on the 20+ years of computer science research. The main limitation of BFT algorithms is that they are usually constrained to a fairly small group of voters, since all voters need to be known beforehand. It becomes extremely difficult to have 100,000 people constantly communicating with every other person to come to an agreement. Cosmoshas run what is probably the largest public BFT system so far in their Game of Stakes test network with 200+ validators taking part.
There are other variants of Nakamoto Consensus such as GHOST (new scoring algorithm, not just longest chain), and there are also other variants of BFT-consensus such as Casper-BFT and Thunderella. These consensus algorithms really only differ in the way blocks are proposed or the amount of communication people need to do to come to agreement — for the most part, they have similar trade-offs as other algorithms in each respective family. There are also newer forms of consensus such as Avalanche which do not fit into either category.
Which Consensus Algorithm do I need?
Depending on the type of application you want to build, these are guiding questions in selecting which consensus algorithm, and in turn which smart-contract platform to build on.
- How important is finality?
Finality is extremely important for some applications, and less so for others. If you are building a new payment system for tiny micro-payments, having a transaction get reversed is not the end of the world. Similarly, if you are building a decentralized social network, having 100% guarantee that a status update will go through immediately is not a particularly important property. Conversely, if you are building a decentralized exchange, finality is absolutely crucial for the user experience. Having trades get reversed is worse than having a trade not happen. For reference, Bitcoin has approximately 1 hour finality, Ethereum has approximately 6 minute finality, and Tendermint Core has 1-second finality. - How fast does your application need to be?
If you are building a game, is it reasonable to wait 15 seconds (or more!) before every action? Because of Ethereum’s block times, games built on it end up having a poor user experience because of Ethereum’s throughput. However, an application that transfers ownership of a housing certificate may be perfectly fine to be run on Ethereum. Using the Cosmos SDK to build applications allows a developer to use Tendermint Core out of the box, which has short block times and high throughput, up to 10,000 transactions per second. You can do so by setting a maximum number of validators for your application — reducing the required communication overhead and speeding up the application. - How “decentralized” do you need your application to be?
Some applications like games may not require significant censorship resistance, which is a byproduct of decentralization. Does it really matter if, in theory, validators could create cartels and block/reverse transactions in your game to profit for themselves? If it does not matter, blockchains such as EOS may be suitable for your use-case because of fast transactions and no fees. However, some applications like an autonomous bank will be more robust the more decentralized it is. Although Ethereum is deemed as decentralized, there are proponents who claim that mining pools in Ethereum are a significant point of centralization for the platform, and in reality there are only 11 validators (mining pools). One of the big benefits of building your own blockchain, instead of building on a smart-contract platform, is that you are able to customize the way validation is done for your application. However, it is difficult to build your own blockchain, so the Cosmos SDK it useful in that regard, making it easy to build your own blockchain and customizing the level of decentralization your application needs. - Is it OK if the system halts?
If you are building an application like a decentralized ride-sharing service, it may be priority #1 to ensure that the service runs 24/7, even if there are occasional errors in accounting (for e.g, transactions getting reversed). One of the properties of Tendermint Core is that if there are disagreements among the validators of the network, the network will choose to stall instead of making incorrect transactions. Some applications like decentralized exchanges require correctness at all costs — it is much better to have a decentralized exchange that pauses if there are problems, instead of making trades that will be reversed.
Conclusion
There is no single “best” consensus algorithm — each one comes with it’s own set of trade-offs. However, by understanding the consensus process (proposal & agreement) and having a framework to think about what consensus algorithm your application may need, you should be able to have a much more informed decision about choosing your blockchain of choice. Of course, there are other considerations such as developer tools, community, and so on, but that is a topic for another blog post.
The main TL;DR takeaways from this blog post are the following:
- Proof-of-work and Proof-of-stake are not consensus algorithms. They are “Sybil Resistance Mechanisms” that help you pick a block proposer.
- The main two families of consensus are Nakamoto Consensus and Classical Consensus. These algorithms are used to come to agreement about blocks in a blockchain.
- There are specific trade-offs for each consensus algorithm. Pick based on application use-case.
- Factors to consider:
- Finality
- Speed
- Decentralization
- Liveness
Let us know what you think of this post and what you’d like us to write about next.

