Linear Regressions and Split Datasets Using Sklearn
A basic guide to show how you can split your main dataset into two parts

In this article, we’re going to learn how we can split up our dataset into two parts — e.g., training and testing datasets.
When we have training and testing datasets, then we’ll apply a machine-learning linear-regression algorithm to predict the price of a car on the basis of its mileage and age (how old the car is).
Step #1
We’re going to use a couple of libraries in this article: pandas to read the file that contains the dataset, sklearn.model_selection to split the training and testing dataset, and matplotlib to draw the regression line.
First of all, import the following packages:
import pandas as pd
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as pltIf you don’t have the above packages installed, then please install them before moving ahead.
Step #2
In this step, we’ll load our CSV file to explore the dataset by using pd as a pandas reference variable and call the read_csv() function along with the file name to read the file.
And now display the top five rows by using the head() function.
df = pd.read_csv('carprices.csv')
df.head()Note: Either move your CSV file inside your working directory or pass the full pathname along with file name.

Step #3
Before splitting up the dataset into training and testing datasets, our focus must be finding the dependent and independent variables. Once these variables are prepared, then we’re ready to go to split up the dataset.
We’ll see the relationship between the mileage and sell price by drawing the data points, and after that, we’ll prepare the dependent and independent variables. Finally, we’ll split the dataset.
So let’s draw the data points using the following line of code:
plt.scatter(df['Mileage'],df['Sell Price($)'])
Now prepare the x and y variables, and display the data of the x variable.
X = df[['Mileage','Age(yrs)']]
Y = df['Sell Price($)']
X.head(10)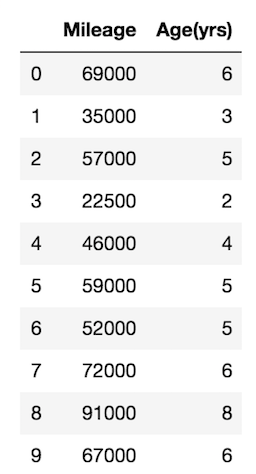
I assigned Mileage and Age(yrs) in X, so it's showing both of them.
Since we’ve split our data into x and y, now we can pass them into the train_test_split() function as a parameter along with test_size, and this function will return us four variables. They’re x_train, y_train, x_test, and y_test.
x_train, x_test,y_train,y_test = train_test_split(X,Y,test_size =0.2)
# print the data
x_trainAs many times as you rerun the above code, you’ll get a different result every time. This is because thetrain_test_split() function picks up the random rows every time, and it’s good for our machine-learning model. If you don’t want thetrain_test_split() function to pick up the random rows, then you can do so by setting random_state = 10.
The test_size parameter in the train_test_split() function defines the size of the testing data in a percentage. Let’s say we have 100 rows, and if we pass test_size=0.2, then it means we want to keep 20% of the data of the entire dataset for the testing purposes. So in this, only 80 rows will be used for training the model.
So in case of my dataset, there are 20 rows in total, and I have given 80% data for the training the model. I’m left with 20% data. If I print the length of the x_train variable, then it’ll print 16 — and if you print the length of the x_test, then it will print 4.
Step #4
Now we’re going to fit our x and y into a machine-learning model to predict the output, but before that, we have to import the LinearRegression from the sklearn.linear_model and create an object of the LinearRegression class.
from sklearn.linear_model import LinearRegression
clf = LinearRegression()Now fit the x_train and y_train variables.
clf.fit(x_train,y_train)Now predict the output by passing the x_test variable.
clf.predict(x_test)Predictions: array([38014.72666327, 16170.60704425, 17307.00704693, 34927.2349164 ])
Now let’s test the accuracy of our model.
clf.score(x_test,y_test)Accuracy: 0.904677273463023
It means our model is accurate up to 90% of the time.
Conclusion
We have seen how we can split up the dataset into training and testing parts to pass it to the fit function. Also, we have used the linear-regression algorithm to predict the price of the car on the basis of its mileage and age.
Download my Jupyter Notebook from my GitHub account.
I hope you liked reading this article, you can also visit my website where I keep posting article regularly.
Subscribe my mailing list to get the early access of my articles directly in your inbox or follow my own publication on Medium The Code Monster to polish your technical knowledge.
Know your author
Himanshu Verma has graduated from the Dr. APJ Abdul Kalam University, Lucknow (India). He is an Android & IOS Developer and Machine Learning & Data Science Learner, a Financial Advisor, and a Blogger.

