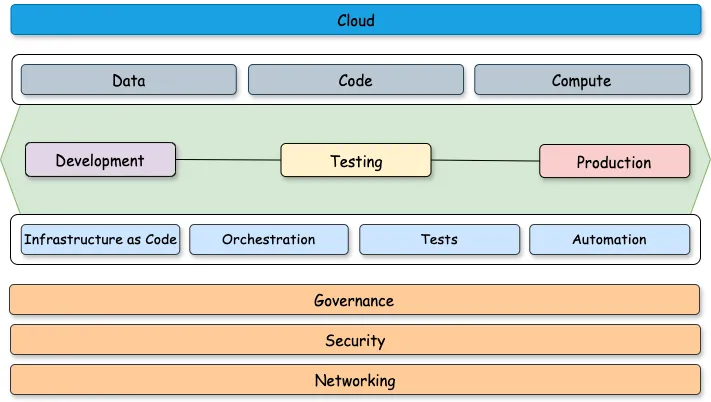
Reza AminiHarnessing the Power of Spark Operator: Orchestrating Data Pipelines with Airflow and GitSimplify Spark job deployment on Kubernetes using Airflow, GitLab, and Spark Operator, tailored for data-intensive industries.12h ago
Eduard PopainData Engineer ThingsA Practitioner’s Guide to Developing Data Engineering Solutions with DatabricksDevelopment Approaches, Environments, CI/CD and Testing with DatabricksJul 267
Archana GoyalWhat’s Next for Apache Spark 4.0: A Comprehensive Overview with Comparisons to Spark 3.xApache Spark has established itself as a leading platform for big data processing, and the upcoming release of Spark 4.0 introduces a range…Aug 252Aug 252
Yingjun WuKafka Has Reached a Turning PointIs Kafka still relevant in today’s evolving tech landscape? And where is Kafka headed in the future?2d ago2d ago
George ZefkilisinData Engineer ThingsBuilding a Local Data Lake from scratch with MinIO, Iceberg, Spark, StarRocks, Mage, and DockerHello again, fellow technology enthusiasts! I am a software/data engineer who transitioned from data science. The learning curve in this…Jul 136Jul 136
Reza AminiHarnessing the Power of Spark Operator: Orchestrating Data Pipelines with Airflow and GitSimplify Spark job deployment on Kubernetes using Airflow, GitLab, and Spark Operator, tailored for data-intensive industries.12h ago
Eduard PopainData Engineer ThingsA Practitioner’s Guide to Developing Data Engineering Solutions with DatabricksDevelopment Approaches, Environments, CI/CD and Testing with DatabricksJul 267
Archana GoyalWhat’s Next for Apache Spark 4.0: A Comprehensive Overview with Comparisons to Spark 3.xApache Spark has established itself as a leading platform for big data processing, and the upcoming release of Spark 4.0 introduces a range…Aug 252
Yingjun WuKafka Has Reached a Turning PointIs Kafka still relevant in today’s evolving tech landscape? And where is Kafka headed in the future?2d ago
George ZefkilisinData Engineer ThingsBuilding a Local Data Lake from scratch with MinIO, Iceberg, Spark, StarRocks, Mage, and DockerHello again, fellow technology enthusiasts! I am a software/data engineer who transitioned from data science. The learning curve in this…Jul 136
Kaviprakash SelvarajSpark performance optimization in Databricks — A complete guideIn this article, we are going to deep dive into techniques of spark optimization in Databricks. This article is written based on the…Aug 301
Rahul MadhaniinData Engineer Things12 Unique Ways to Create Spark DataFramesDiscover 12 Unique Ways to Create Spark DataFrames with Practical Examples and Insights.5h ago
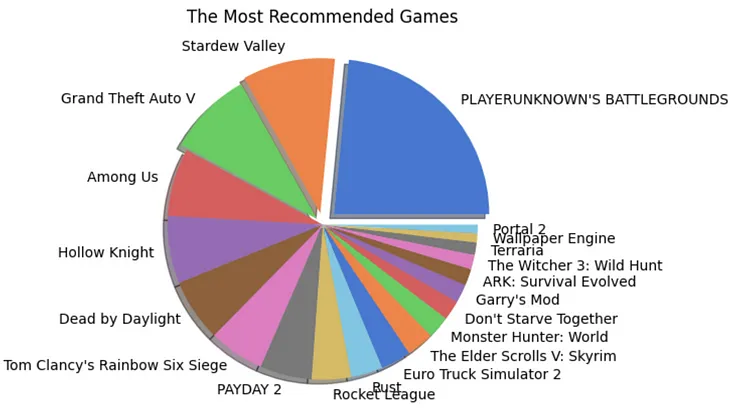
Rindhuja Treesa JohnsoninTowards Data ScienceApache Hadoop and Apache Spark for Big Data AnalysisA complete guide to big data analysis using Apache Hadoop (HDFS) and PySpark library in Python on game reviews on the Steam gaming…May 81