Data monetization: How much is your data worth?
To get the buy-in for investment in data, we have to track data costs and monetize the impact data has on business outcomes. In most cases, this is a very complex task. Here is my take on the data monetization framework by using data product as an anchor (“unit of data”).

Data product as an anchor of data monetization
Nowadays, data is treated as one of the key organizational assets. Hence, we need to measure how much data cost on one side, as well as quantify the impact of overall business outcomes on the other side (the value of data). In most cases, that is not an easy task. The initial step is to determine what will be the “unit of data” in the process of data monetization, so we can use it as a baseline for quantification. In the data environment, data is typically stored in different data stores (databases) and is used by multiple applications. Also, data sets from data stores flow through many data pipelines, moving from one application to another, feeding reports and analytical data stores. Hence, for example, if I want to calculate labor costs for data required for end-user reports, how I am going to do that? Am I calculating the labor of data stored in the data store, and/or, data pipelines that feed my report? Here is where the “data product” concept comes into play as an anchor and resolves ambiguity by making the “unit of data” which can be independently tracked and measured across many other data monetization variables.
Cost of data
Now that we have the data product as an anchor to quantify the value of data, let's see how we can determine the data cost side. In general, the cost of data has components as follows:
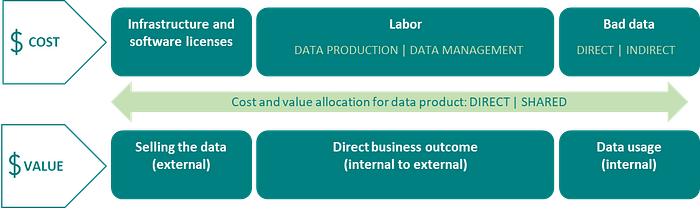
- Infrastructure and software licenses: refers to the cost of software licenses and the cost of hardware infrastructure (on-premise or cloud) which is required to create and operate data products
- Labor: refers to labor cost which can be calculated as the sum of all hours spent by different data practitioners on activities of data production and management multiplied by the hourly rate for the respective practitioner (which is calculated based on salary or agreed rate)
- Bad data: The cost of bad data is reflected through negative business outcomes which are the result of bad decisions made by using bad data. Typically, for external use of data, you should be able to determine the dollar amount (e.g., for example, a bank is fined by the FED a huge dollar amount due to incorrect regulatory reporting). For internal use, the negative impact of bad data can be calculated indirectly through the ineffective performance of the business process for which data is used. Last, but not least, “bad data” cost is overlapping with labor cost in the context of data management (e.g. remediation of data issues which are the root cause of regulatory fines)
The value of data
For the data value side, we are starting again with the data product as an anchor. In general, there are three high-level use cases for the value of data as follows:
- Selling the data (external): refers to the use case where the organization is selling its data on an external data market. The value of data is determined by market prices, and accordingly, that is an “easy” use case of how data can be associated with a dollar value
- Direct business outcome (internal to external): refers to a use case and example where you are selling products and sales performance is dominantly based on data. In that case, you can associate the sales performance with the value of data
- Data usage (internal): refers to the internal use of data, where the data consumer is using the data provided by one or more data producers to perform an internal business process. There is no money explicitly involved here, where data consumers are paying data producers for data. The business outcomes, in this case, are related to the quantified performance of the business process where data is used. Hence, the value of the data can be determined as a difference in the dollar value of business process performance with and without the data.
Direct and Shared Cost and Value
For most data cost and data value use cases, both, data cost and data value can be direct or shared. For instance, for infrastructure and software license costs, the direct cost could be related to a virtual machine where the data product is exclusively hosted. On the other side, the cost will be shared if multiple data products are hosted on the same virtual machine. Similarly, the labor cost should be able to allocate to a particular product as direct cost (e.g. data stewardship) or allocate a portion of the cost as shared cost (e.g. acquisition phase, where multiple data products can be created from multiple data sources in the same data pipeline). The same story is on the data value side. For example, data usage quantification will use the shared if multiple data products are used in the same business process in which performance is tracked.
The major challenge in shared cost or value allocation is to make a fair allocation of shared costs or value across data products. Some of the criteria that can reduce ambiguity to allocating costs or value across data products contributing to the single business process are 1) the relevance of the data product (how important is and how widely is used) or 2) the required effort to acquire, transform and manage data. After initial allocation, you can continuously enhance and tune the criteria to improve the accuracy of the cost or value allocation.
Business Process Performance
To me, the most difficult challenge in quantifying the cost and value of data is to make indirect quantification by tracking the impact of data through business process performance. The reasons are as follows:
- Many organizations don’t have mature capabilities for business process performance tracking
- Business process performance is typically not related to data only, but to some other input variables. For example, if you have the process of delivering an important business report, and you feed that process with bad data, you can still have a positive outcome (accurate and timely report) if you have an extraordinary data engineer who will remediate the impact of bad data
I believe there is no universal formula to resolve this, other than effective business process management where you can precisely track the performance of the business process and the impact of input variables on the business process outcomes.
Data Monetization Framework
In summary, based on all of the above, the data monetization framework should look as follows:
What are your thoughts? Comments are welcome and appreciated.
Disclaimer: The views and opinions expressed in this article are those of the author and do not necessarily reflect the views or positions of any entities author represents.