
How Data Mining The Web Reveals What Makes Puzzles Hard For Humans
Huge data sets from puzzle websites are providing a new way of studying the way humans solve problems
What makes a puzzle hard for humans? Why, for example, might one Sudoku puzzle take you 10 minutes to solve while another seemingly similar one stump you for 40 minutes.
The answer is that nobody quite knows. But that looks set to change thanks to Radek Pelanek at Masaryk University Brno in the Czech Republic, who has found a way to study the way humans solve puzzles in more detail than has ever been possible.
That’s allowed him to build the first model of human problem solving that almost exactly explains the observed data. His new approach could kickstart an entirely new approach to the study of how humans understand, approach and attempt to solve problems.
Studying human problem solving is tricky because it isn’t always clear how humans do this task, whether they choose the best way to find a solution or even a good way to do it.
Pelanek’s work is changing all this. The puzzle he has started with is Sudoku and the question he hopes to answer is how to predict the difficulty of a particular Sudoku puzzle.
The game is straightforward in principle. The objective is to fill a 9 x 9 grid with the numbers from 1 to 9 and in such a way that each row, column and 3 x 3 subgrid contain all the digits.
Sudoku falls into a class of problems known as constraint satisfaction problems. Others include colouring a map so that countries with a common border do not share the same colour. But how to determine the difficulty of this task?
One way is measure how long it takes people to solve different problems and then work out what it is about them that takes longer. This is a time-consuming business. Most studies of this kind have gathered data about the way a few tens of individuals have solved a handful of puzzles. And this gives only limited insight.
But there’s another way to gather this kind of data, says Pelanek: from gaming sites on the internet. And that’s exactly what he’s done.
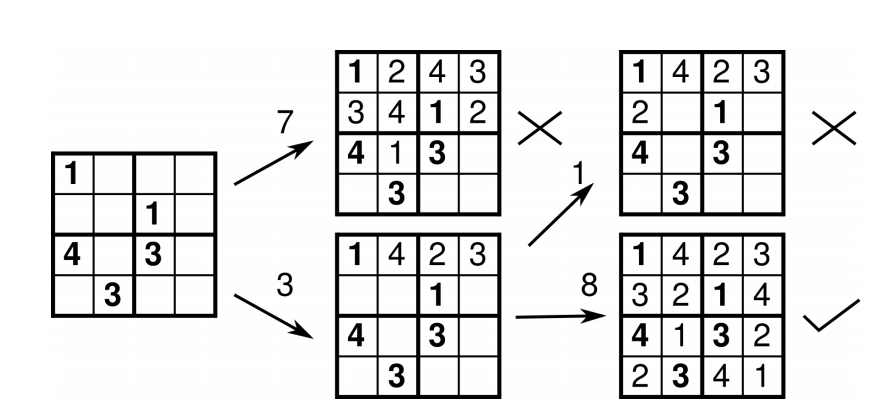
Pelanek has gathered hundreds of thousands of hours of data on the way humans solve Sudoku puzzles on websites, such as www.sudoku.org.uk. His data focuses on 2000 puzzles each solved by hundreds of individual players.
His measure of the difficulty of a puzzle is the average time it takes to solve it. The data shows a clear distribution of solution times, with a few puzzles being very quick to solve, most taking between 500 and 1,000 seconds but with a long tail of puzzles that can take anything up to 2500 seconds.
One way to explain this difference is to look at the complexity of the steps required to solve a puzzle. Clearly, the more complex the steps, the longer it will take. Indeed, a model that predicts difficulty based on step complexity does a reasonable job.
But Pelanek has done significantly better. “We show that there is also a second aspect that has not yet been utilized for difficulty rating,” he says.

His key insight is to ask whether the individual steps in the solution are independent and so can be applied in parallel; or whether they are dependent on each other and so must be applied in series, one after the other.
He then goes on to build a model of puzzle solving that captures both of these aspects and shows that it is better match to the actual data than anything that has been achieved before. He says the correlation with the measured data is 0.95.
That immediately allows puzzles to be rated in advance simply by working out the complexity of the steps needed to solve it and whether they depend on each other. But it has broader ramifications.
Exactly the same approach can also be used to rate the difficulty of map colouring problems, for example. Or indeed any other puzzle that falls into the category of constraint satisfaction problems.
All this is significantly different from the conventional approach to problem difficulty, an area of science that is known as computational complexity theory. Much time has been devoted to studying the difficulty of certain problems for computers and categorising them accordingly.
But humans do things differently. Pelanek is able to show just how significant this is by also examining other ways of solving Sudoku that would be straightforward for a computer but almost impossible for human.
One way is through a process known as constraint relaxation. Sudoku puzzles are generally easier when they contain more information for the player, in other words when they contain more starting digits. That’s because this dramatically narrows the number of possible solutions.
But reduce the number of starting digits and the puzzles become harder, taking more steps to complete. Indeed, remove enough digits and there can end up being many solutions to a single puzzle.
What’s interesting is that as the number of starting digits is reduced, the number of steps required to solve the puzzle undergoes a kind of phase change—a small change in the number of starting digits leads to a dramatic increase in the number of steps required to solve the puzzle.
That also leads to a good way of rating the difficulty of a puzzle. So although a human would never approach a puzzle in this way, the method still provides insight into how difficult a human would find it. “It does not mimic human thinking and yet it can predict it,” says Pelanek.
That’s a fascinating conclusion that immediately points to other ways of gaining insights into human problem-solving using different data sets.
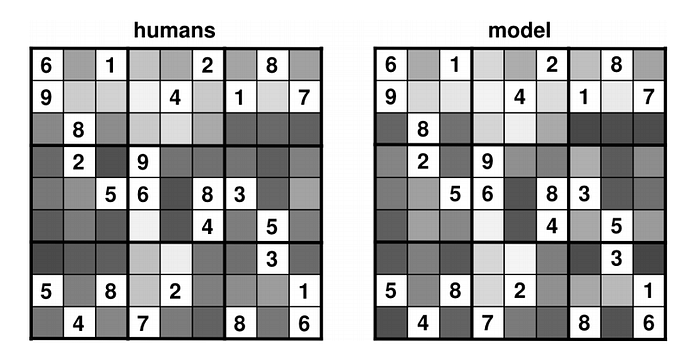
An interesting question is whether the same approach that Pelanek has used for Sudoku can also be used for other puzzles. Pelanek has already begun work on other problems such as Nurikabe, another number puzzle played a grid.
Clearly, human problem-solving is a science with plenty of low-hanging fruit for an enterprising researcher. We’ll be watching to see what it produces.
Ref: arxiv.org/abs/1403.7373 : Difficulty Rating of Sudoku Puzzles: An Overview and Evaluation
Follow the Physics arXiv Blog by hitting the Follow button below, on Twitter at @arxivblog and now also on Facebook

