What is 2-Dimensional Convolution?
Create your own image filters…

All of us love using image filters. I spend hours trying out different filters and choosing the one in which I look the best. What if I could customize and create filters on my own?
Quarantine has got me doing a lot of interesting stuff. Convinced of python’s superpower to do anything in the world, I am trying to explore and test the waters.
WHAT IS CONVOLUTION?
Convolution is a technique widely used in image processing. Convolution is a mathematical operation on two functions that produces a third function expressing how the shape of one is modified by the other. (As defined in Wikipedia).

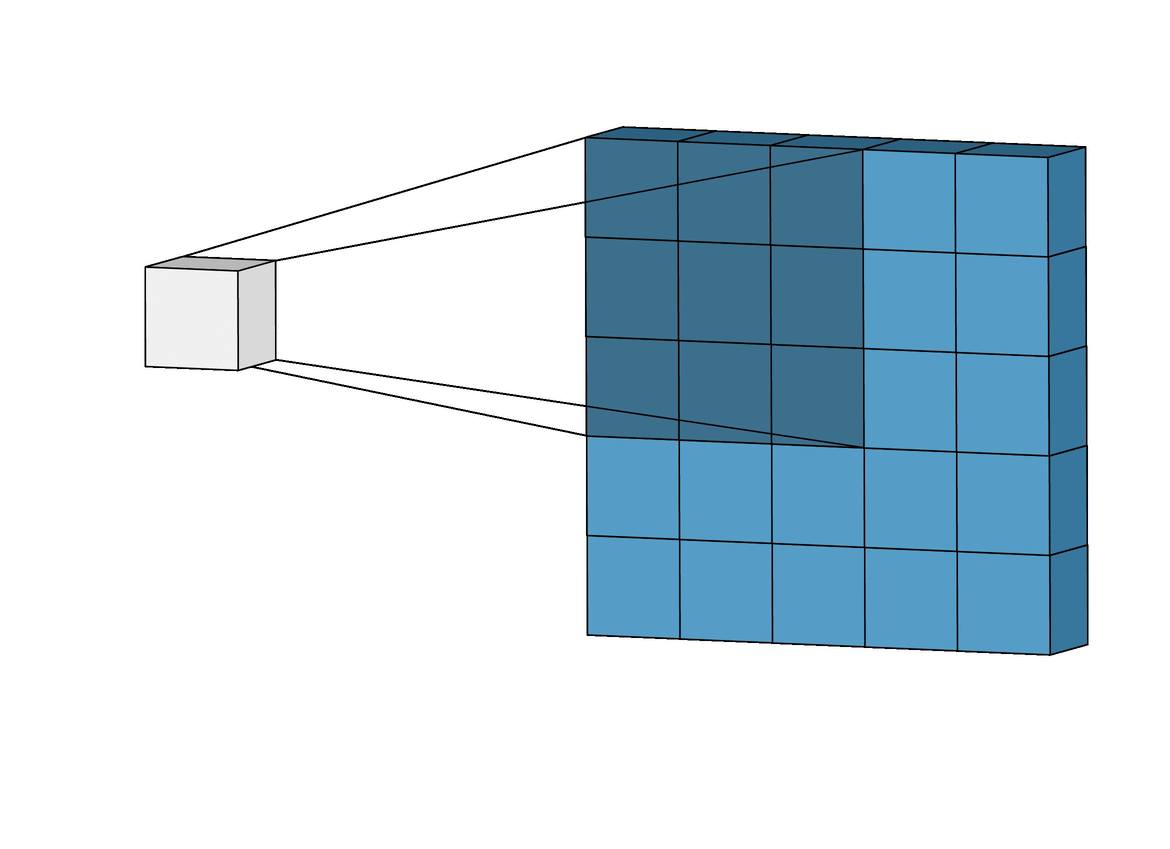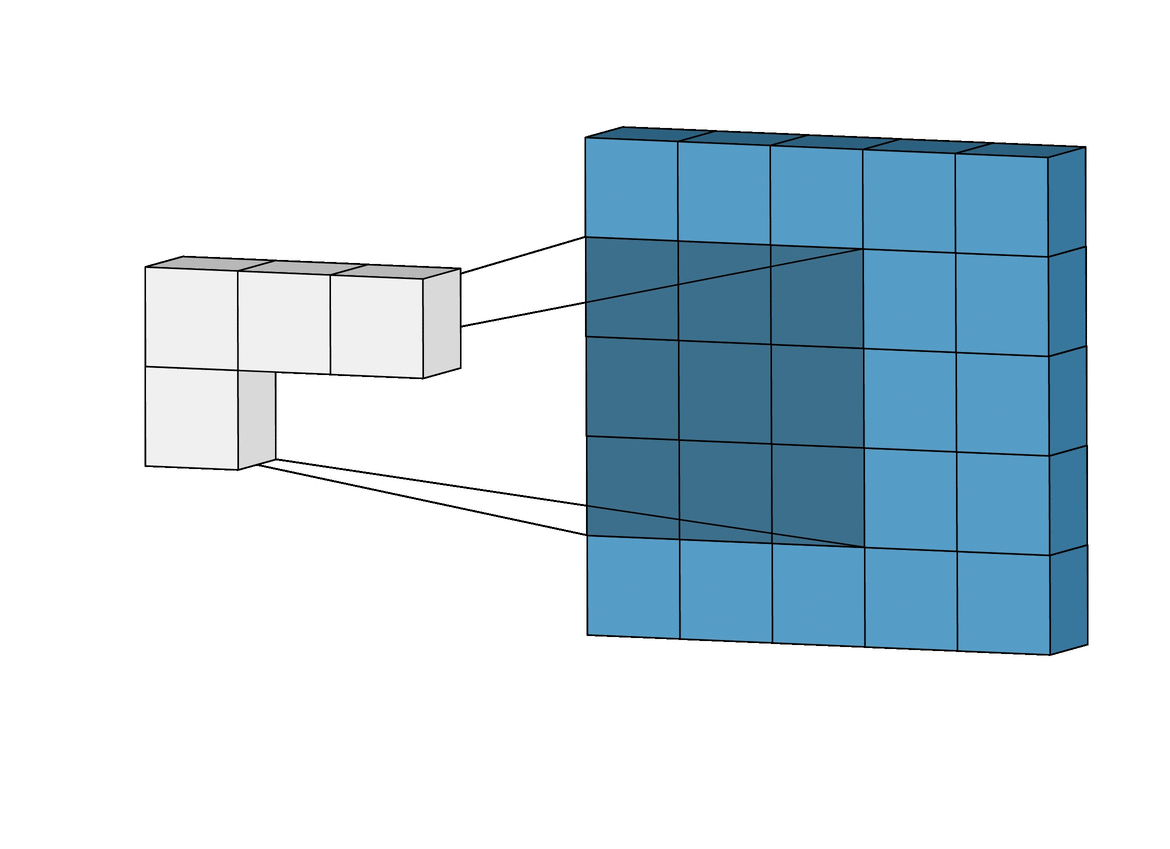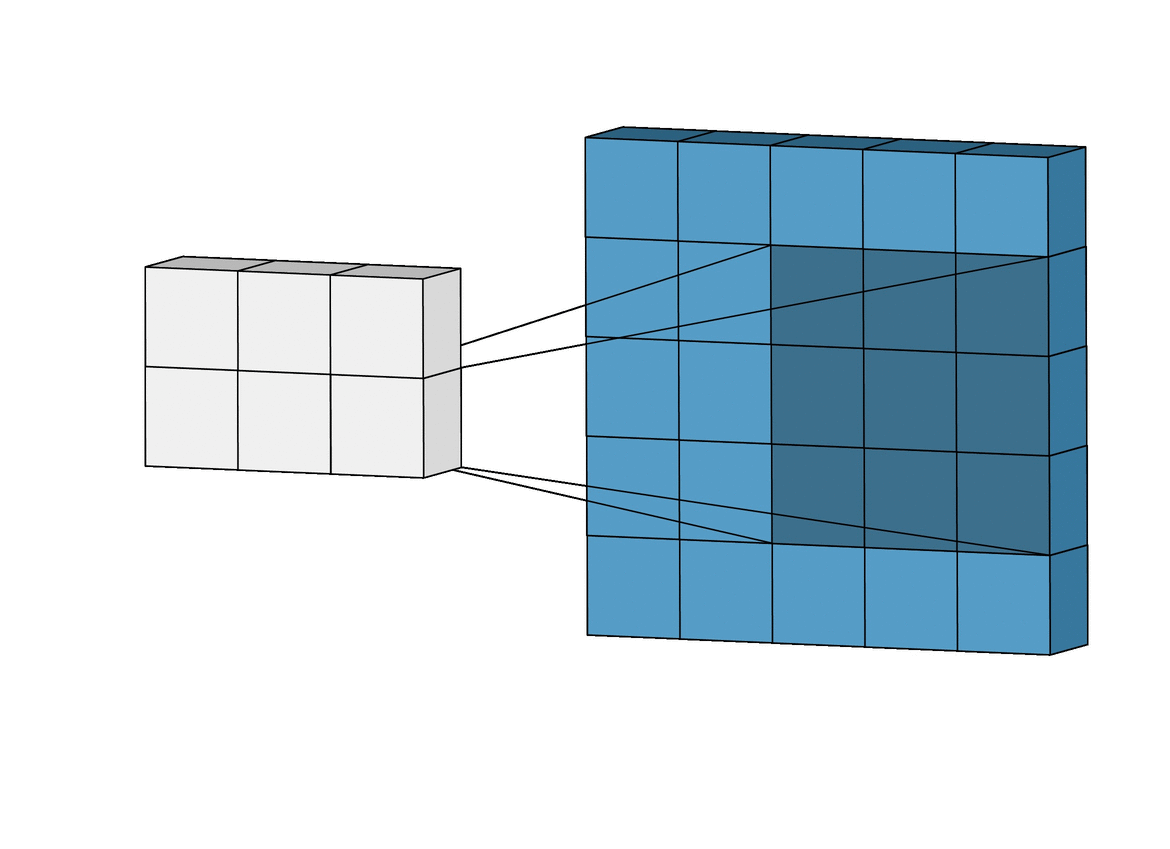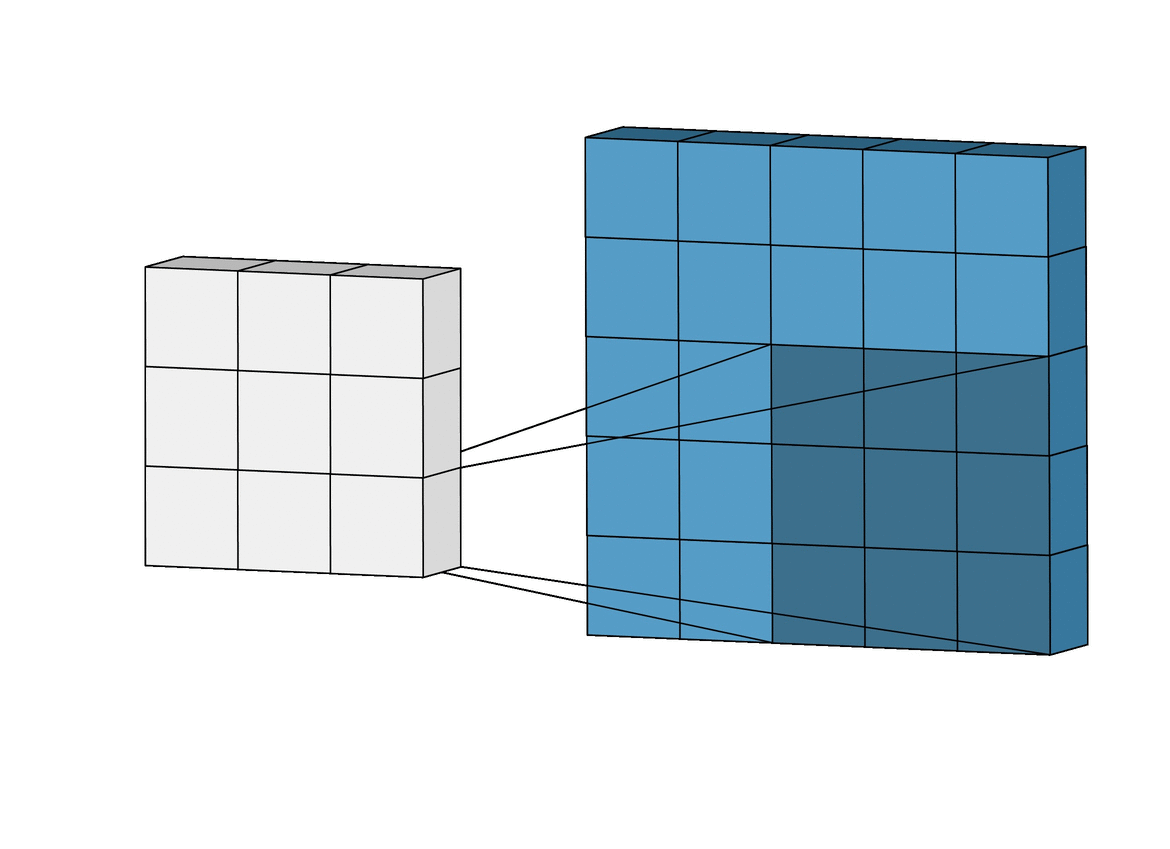
This is a visual representation of 2-Dimensional Convolution.
So I got my hands dirty and tried to implement it on my own. Most of the images we have today are colored, technically they are represented as a stream of RGB (red, green, blue) values.
To start off, I decided to implement convolution on grayscale images. This blog is a guide to applying filters to grayscale images.
In grayscale images, the RGB values are reduced to a single value, so it reduces to a 2-D array, I found it a little easier to start off with 2-D convolution.
In the visual representation, the blue matrix represents the pixels of the image in grayscale. A smaller matrix (of the size 3X3 or 5X5 ) known as a kernel is multiplied to the bigger matrix sequentially as shown above. The sum of these values is stored in another matrix.

The kernel or mask can be different based on the filter that you would want to apply.


These are a few examples, different kernels that can be used to enhance or extract different features.
This is the link to the code, feel free to try it out: https://colab.research.google.com/drive/1OqVQEd8M7l0HnfOfcwlkMh3GFJFYmL39?usp=sharing
So let’s dive into the code. I use Google Colaboratory for all my python projects. It’s my personal favorite.

Upload an image in google colab, pass the path as a parameter in the cv2.imread function.

In the resize function, the arguments are as (width, height) as opposed to (height, width)
When an image is converted from the RGB format to grayscale, (r,g,b) is converted to a single value.

I would like to explain my approach. An image is made of pixels, each pixel is made of color from the RGB scheme represented as (r,g,b), each taking values between 0 to 255. The image can be interpreted as a matrix of RGB values equal to the size of the image. The kernel is another matrix. A simple operation of matrix multiplication is used to obtain the result after convolution.

The pixels at the edges are not dealt with, they are neglected. This causes a reduction in the size of the convoluted_matrix.

This is the result after applying the gaussian filter.
This is the result after applying the Sobel filter in the y-direction
The kernel has a different set of values


I would strongly recommend the readers to go through the documentation of the above-used libraries so as to gain a better understanding of the code.
That’s it! Hope you liked the blog, don’t forget to hit the clap button a few times.
Don’t forget to follow The Lean Programmer Publication for more such articles, and subscribe to our newsletter tinyletter.com/TheLeanProgrammer

{kind=link}